前人的缺陷:
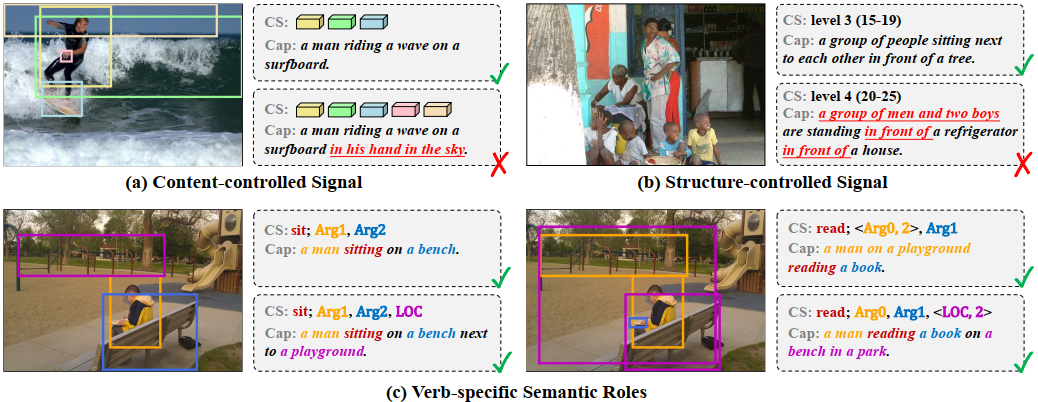
CIC works mainly focus on (1)subjective control signals,(2)objective control signals or (1) Content-controlled (2) Structure controlled。
almost all existing objective control signals have overlooked two indispensable characteristics of an ideal control signal:
1) Event-compatible:all visual contents referred to in a single sentence should be compatible with the describe activity.
2) Sample-suitable: the control signals should be suitable for a specific image sample.
论文的创新点:
propose a new event-oriented objective control signal, Verb-specific Semantic Roles (VSR), to meet both event-compatible and sample-suitable requirements simultaneously。
VSR consists of a verb and some user-interested semantic roles。
Grounded Semantic Role Labeling: visual features of all grounded proposal sets。
Semantic Structure Planner: hierarchical semantic structure learning model, which aims to learn a reasonable sequence of sub-roles S。
Verb-specific Semantic Roles = Grounded Semantic Role Labeling υ Semantic Structure Planner
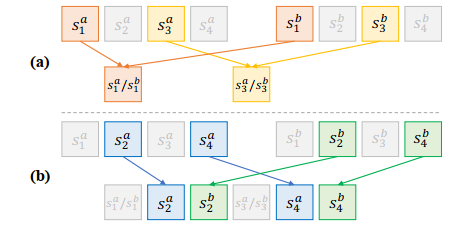
step:we first use GSRL and SSP to obtain semantic structures and grounded regions features: (Sa; Ra) and (Sb; Rb).
Then,as shown in Figure above, we merge them by two steps。
(a) find the sub-roles in both Sa and Sb which refer to the same visual regions
(b) insert all other sub-roles between the nearest two selected sub-roles
模型架构:
Faster R-CNN(ResNet-101) + Controllable LSTM + Controllable UpDn + SCT