一、ByteBuf类的结构
ByteBuf类继承关系图如下:
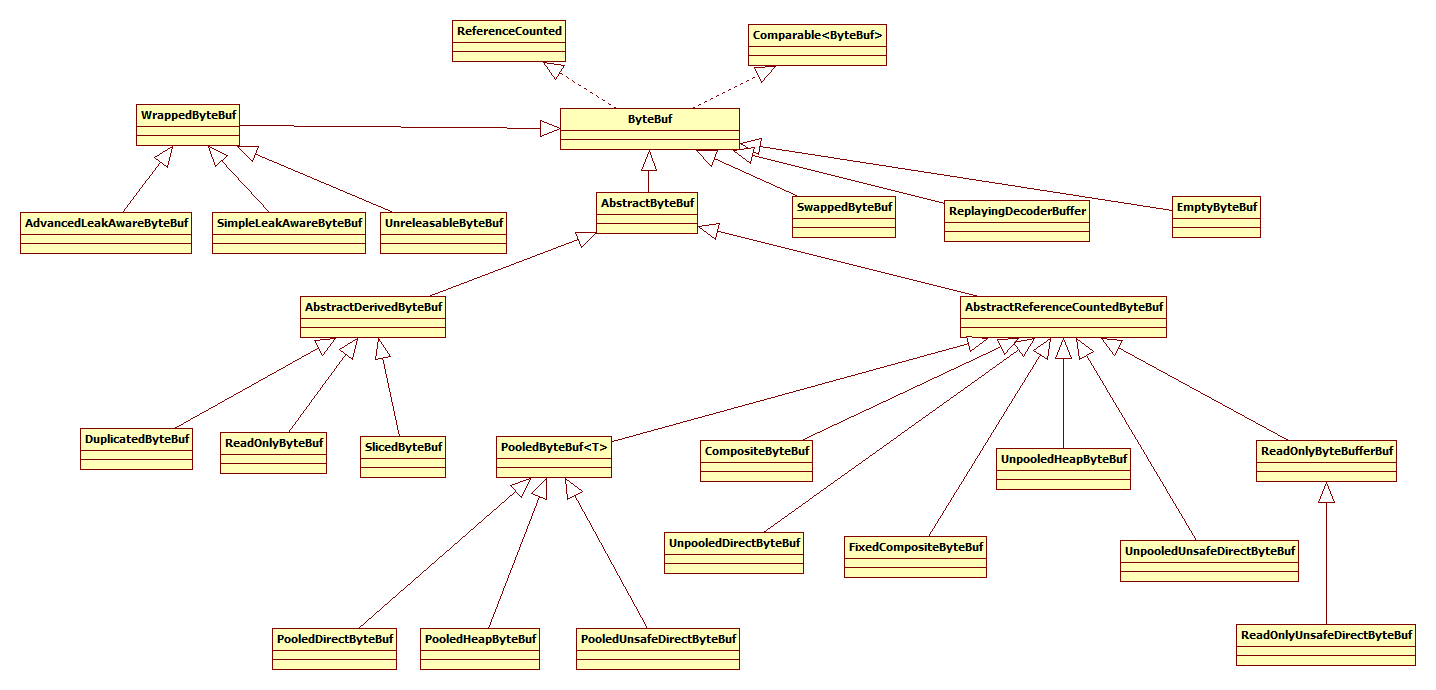
ReferenceCounted:对象引用计数器,初始化ReferenceCounted对象时,引用数量refCnt为1,调用retain()可增加refCnt,release()用于减少refCnt。refCnt为1时,说明对象实际不可达,release()方法将立即调用deallocate()释放对象。如果refCnt为0,说明对象被错误的引用。在AbstractReferenceCountedByteBuf源码分析小节将详细介绍ReferenceCounted的原理。
ByteBuf:实现接口ReferenceCounted和Comparable,实现ReferenceCounted使得ByteBuf具备引用计数的能力,方便跟踪ByteBuf对象分配和释放。
- ByteBuf直接子类
EmptyByteBuf:用于构建空ByteBuf对象,capacity和maxCapacity均为0。
ReplayingDecoderBuffer:用于构建在IO阻塞条件下实现无阻塞解码的特殊ByteBuf对象,当要读取的数据还未接收完全时,抛出异常,交由ReplayingDecoder处理。
SwappedByteBuf:用于构建具有切换字节顺序功能的ByteBuf对象,默认ByteBuf对象使用BIG_ENDIAN(大字节序)存储数据,SwappedByteBuf可以在BIG_ENDIAN和LITTLE_ENDIAN之间自由切换。TCP/IP各层协议均采用网络字节序(BIG_ENDIAN),关于字节序的更多内容不详细介绍。
WrappedByteBuf:用于装饰ByteBuf对象,主要有AdvancedLeakAwareByteBuf、SimpleLeakAwareByteBuf和UnreleasableByteBuf三个子类。这里WrappedByteBuf使用装饰者模式装饰ByteBuf对象,AdvancedLeakAwareByteBuf用于对所有操作记录堆栈信息,方便监控内存泄漏;SimpleLeakAwareByteBuf只记录order(ByteOrder endianness)的堆栈信息;UnreleasableByteBuf用于阻止修改对象引用计数器refCnt的值。
AbstractByteBuf:提供ByteBuf的默认实现,同时组合ResourceLeakDetector和SwappedByteBuf的能力,ResourceLeakDetector是内存泄漏检测工具,SwappedByteBuf用于字节序不同时转换字节序。
- AbstractByteBuf直接子类
AbstractDerivedByteBuf:提供派生ByteBuf的默认实现,主要有DuplicatedByteBuf、ReadOnlyByteBuf和SlicedByteBuf。
DuplicatedByteBuf使用装饰者模式创建ByteBuf的复制对象,使得复制后的对象与原对象共享缓冲区的内容,但是独立维护自己的readerIndex和writerIndex。
ReadOnlyByteBuf使用装饰者模式创建ByteBuf的只读对象,该只读对象与原对象共享缓冲区的内容,但是独立维护自己的readerIndex和writerIndex,之后所有的写操作都被限制;
SlicedByteBuf使用装饰者模式创建ByteBuf的一个子区域ByteBuf对象,返回的ByteBuf对象与当前ByteBuf对象共享缓冲区的内容,但是维护自己独立的readerIndex和writerIndex,允许写操作。
AbstractReferenceCountedByteBuf:提供修改对象引用计数器相关操作的默认实现。
- AbstractReferenceCountedByteBuf直接子类
CompositeByteBuf:用于将多个ByteBuf组合在一起,形成一个虚拟的ByteBuf对象,支持读写和动态扩展。内部使用List<Component>组合多个ByteBuf。推荐使用ByteBufAllocator的compositeBuffer()方法,Unpooled的工厂方法compositeBuffer()或wrappedBuffer(ByteBuf... buffers)创建CompositeByteBuf对象。
FixedCompositeByteBuf:用于将多个ByteBuf组合在一起,形成一个虚拟的只读ByteBuf对象,不允许写入和动态扩展。内部使用Object[]将多个ByteBuf组合在一起,一旦FixedCompositeByteBuf对象构建完成,则不会被更改。
PooledByteBuf<T>:基于内存池的ByteBuf,主要为了重用ByteBuf对象,提升内存的使用效率;适用于高负载,高并发的应用中。主要有PooledDirectByteBuf,PooledHeapByteBuf,PooledUnsafeDirectByteBuf三个子类,PooledDirectByteBuf是在堆外进行内存分配的内存池ByteBuf,PooledHeapByteBuf是基于堆内存分配内存池ByteBuf,PooledUnsafeDirectByteBuf也是在堆外进行内存分配的内存池ByteBuf,区别在于PooledUnsafeDirectByteBuf内部使用基于PlatformDependent相关操作实现ByteBuf,具有平台相关性。
ReadOnlyByteBufferBuf:只读ByteBuf,内部持有ByteBuffer对象,相关操作委托给ByteBuffer实现,该ByteBuf限内部使用,ReadOnlyByteBufferBuf还有一个子类ReadOnlyUnsafeDirectByteBuf。
UnpooledDirectByteBuf:在堆外进行内存分配的非内存池ByteBuf,内部持有ByteBuffer对象,相关操作委托给ByteBuffer实现。
UnpooledHeapByteBuf:基于堆内存分配非内存池ByteBuf,即内部持有byte数组。
UnpooledUnsafeDirectByteBuf:与UnpooledDirectByteBuf相同,区别在于UnpooledUnsafeDirectByteBuf内部使用基于PlatformDependent相关操作实现ByteBuf,具有平台相关性。
总结:
从内存分配角度看,ByteBuf主要分为两类:
- 堆内存(HeapByteBuf)字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动回收;缺点是进行Socket的I/O读写需要额外进行一次内存复制,即将内存对应的缓冲区复制到内核Channel中,性能会有一定程度下降。
- 直接内存(DirectByteBuf)字节缓冲区:在堆外进行内存分配,相比堆内存,分配和回收速度稍慢。但用于Socket的I/O读写时,少一次内存复制,速度比堆内存字节缓冲区快。
经验表明,在I/O通信线程的读写缓冲区使用DirectByteBuf,后端业务消息的编解码模块使用HeapByteBuf,这样组合可以达到性能最优。
从内存回收角度看,ByteBuf也分为两类:
- 基于内存池的ByteBuf:优点是可以重用ByteBuf对象,通过自己维护一个内存池,可以循环利用创建的ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。适用于高负载,高并发的应用中。推荐使用基于内存池的ByteBuf。
- 非内存池的ByteBuf:优点是管理和维护相对简单。
二、图解ByteBuf
1.ByteBuf的逻辑
ByteBuf 是一个字节容器,内部是一个字节数组。从逻辑上来分,字节容器内部,可以分为四个部分:
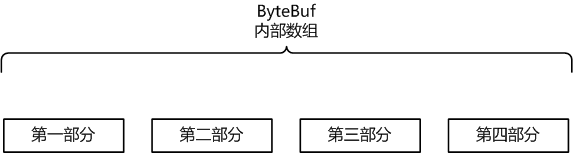
第一个部分是已经丢弃的字节,这部分数据是无效的;
第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;
第三部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。
第四部分的字节,表示的是该 ByteBuf 最多还能扩容的大小。
四个部分的逻辑功能,如下图所示:
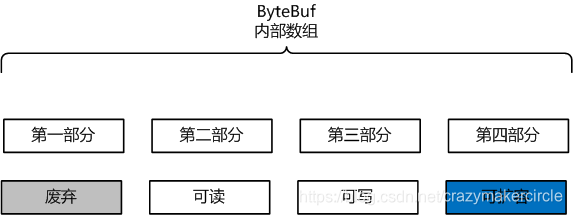
ByteBuf 通过三个整型的指针(index),有效地区分可读数据和可写数据,使得读写之间相互没有冲突。
这个三个指针,分别是:
readerIndex(读指针)
writerIndex(写指针)
maxCapacity(最大容量)

这三个指针,是三个int 型的成员属性,定义在 AbstractByteBuf 抽象基类中。
三个指针的代码如下:
public abstract class AbstractByteBuf extends ByteBuf { private static final InternalLogger logger = InternalLoggerFactory.getInstance(AbstractByteBuf.class); private static final String LEGACY_PROP_CHECK_ACCESSIBLE = "io.netty.buffer.bytebuf.checkAccessible"; private static final String PROP_CHECK_ACCESSIBLE = "io.netty.buffer.checkAccessible"; static final boolean checkAccessible; // accessed from CompositeByteBuf private static final String PROP_CHECK_BOUNDS = "io.netty.buffer.checkBounds"; private static final boolean checkBounds;int readerIndex; //1)读指针 int writerIndex; //2)写指针 private int markedReaderIndex; private int markedWriterIndex; private int maxCapacity; //3)最大容量
readerIndex 读指针
指示读取的起始位置。每读取一个字节,readerIndex 自增1 。一旦 readerIndex 与 writerIndex 相等,ByteBuf 不可读 。
writerIndex 写指针
指示写入的起始位置。每写一个字节,writerIndex 自增1。一旦增加到 writerIndex 与 capacity() 容量相等,表示 ByteBuf 已经不可写了 。
capacity()容量不是一个成员属性,是一个成员方法。表示 ByteBuf 内部的总容量。 注意,这个不是最大容量。
maxCapacity 最大容量
指示可以 ByteBuf 扩容的最大容量。当向 ByteBuf 写数据的时候,如果容量不足,可以进行扩容。
扩容的最大限度,直到 capacity() 扩容到 maxCapacity为止,超过 maxCapacity 就会报错。capacity()扩容的操作,是底层自动进行的。
2、ByteBuf 的三组方法
从三个维度三大系列,介绍ByteBuf 的常用 API 方法。

第一组:容量系列
方法 一:capacity()
表示 ByteBuf 的容量,包括丢弃的字节数、可读字节数、可写字节数。
方法二:maxCapacity()
表示 ByteBuf 底层最大能够占用的最大字节数。当向 ByteBuf 中写数据的时候,如果发现容量不足,则进行扩容,直到扩容到 maxCapacity。
第二组:写入系列
方法一:isWritable()
表示 ByteBuf 是否可写。如果 capacity() 容量大于 writerIndex 指针的位置 ,则表示可写。否则为不可写。
isWritable()的源码,也是很简单的。具体如下:
public boolean isWritable() { return capacity() > writerIndex; }
注意:如果 isWritable() 返回 false,并不代表不能往 ByteBuf 中写数据了。 如果Netty发现往 ByteBuf 中写数据写不进去的话,会自动扩容 ByteBuf。
方法二:writableBytes()
返回表示 ByteBuf 当前可写入的字节数,它的值等于 capacity()- writerIndex。
如下图所示:
方法三:maxWritableBytes()
返回可写的最大字节数,它的值等于 maxCapacity-writerIndex 。
方法四:**writeBytes(byte[] src) **
把字节数组 src 里面的数据全部写到 ByteBuf。
这个是最为常用的一个方法。
方法五:writeTYPE(TYPE value) 基础类型写入方法
基础数据类型的写入,包含了 8大基础类型的写入。
具体如下:writeByte()、 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() ,向 ByteBuf写入基础类型的数据。
方法六:setTYPE(TYPE value)基础类型写入,不改变指针值
基础数据类型的写入,包含了 8大基础类型的写入。
具体如下:setByte()、 setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble() ,向 ByteBuf 写入基础类型的数据。
setType 系列与writeTYPE系列的不同:
setType 系列 不会 改变写指针 writerIndex ;
writeTYPE系列 会 改变写指针 writerIndex 的值。
方法七:markWriterIndex() 与 resetWriterIndex() 这里两个方法一起介绍。
前一个方法,表示把当前的写指针writerIndex 保存在 markedWriterIndex 属性中;
后一个方法,表示把当前的写指针 writerIndex 恢复到之前保存的 markedWriterIndex 值 。
标记 markedWriterIndex 属性, 定义在 AbstractByteBuf 抽象基类中。
代码如下:
public abstract class AbstractByteBuf extends ByteBuf { private static final InternalLogger logger = InternalLoggerFactory.getInstance(AbstractByteBuf.class); private static final String LEGACY_PROP_CHECK_ACCESSIBLE = "io.netty.buffer.bytebuf.checkAccessible"; private static final String PROP_CHECK_ACCESSIBLE = "io.netty.buffer.checkAccessible"; static final boolean checkAccessible; // accessed from CompositeByteBuf private static final String PROP_CHECK_BOUNDS = "io.netty.buffer.checkBounds"; private static final boolean checkBounds; int readerIndex; int writerIndex; private int markedReaderIndex; //1)把当前的读指针readerIndex 保存在 markedReaderIndex 属性中
private int markedWriterIndex; //2)把当前的写指针writerIndex 保存在 markedWriterIndex 属性中
private int maxCapacity;
第三组:读取系列
方法一:isReadable()
表示 ByteBuf 是否可读。如果 writerIndex 指针的值大于 readerIndex 指针的值 ,则表示可读。否则为不可写。
isReadable()的源码,也是很简单的。具体如下:
@Override public boolean isReadable() { return writerIndex > readerIndex; } @Override public boolean isReadable(int numBytes) { return writerIndex - readerIndex >= numBytes; }
方法二:readableBytes()
返回表示 ByteBuf 当前可读取的字节数,它的值等于 writerIndex - readerIndex 。
如下图所示:

方法三: readBytes(byte[] dst)
把 ByteBuf 里面的数据全部读取到 dst 字节数组中,这里 dst 字节数组的大小通常等于 readableBytes() 。 这个方法,也是最为常用的一个方法。
方法四:readType() 基础类型读取
基础数据类型的读取,可以读取 8大基础类型。
具体如下:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() ,从 ByteBuf读取对应的基础类型的数据。
方法五:getTYPE(TYPE value)基础类型读取,不改变指针值
基础数据类型的读取,可以读取 8大基础类型。
具体如下:getByte()、 getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble() ,从 ByteBuf读取对应的基础类型的数据。
getType 系列与readTYPE系列的不同:
getType 系列 不会 改变读指针 readerIndex ;
readTYPE系列 会 改变读指针 readerIndex 的值。
方法六:markReaderIndex() 与 resetReaderIndex() 这里两个方法一起介绍。
前一个方法,表示把当前的读指针ReaderIndex 保存在 markedReaderIndex 属性中。
后一个方法,表示把当前的读指针 ReaderIndex 恢复到之前保存的 markedReaderIndex 值 。
标记 markedReaderIndex 属性, 定义在 AbstractByteBuf 抽象基类中。
public abstract class AbstractByteBuf extends ByteBuf { private static final InternalLogger logger = InternalLoggerFactory.getInstance(AbstractByteBuf.class); private static final String LEGACY_PROP_CHECK_ACCESSIBLE = "io.netty.buffer.bytebuf.checkAccessible"; private static final String PROP_CHECK_ACCESSIBLE = "io.netty.buffer.checkAccessible"; static final boolean checkAccessible; // accessed from CompositeByteBuf private static final String PROP_CHECK_BOUNDS = "io.netty.buffer.checkBounds"; private static final boolean checkBounds; int readerIndex; int writerIndex; private int markedReaderIndex; //1)把当前的读指针readerIndex 保存在 markedReaderIndex 属性中 private int markedWriterIndex; //2)把当前的写指针writerIndex 保存在 markedWriterIndex 属性中 private int maxCapacity;
3、ByteBuf 的引用计数
Netty 的 ByteBuf 的内存回收工作,是通过引用计数的方式管理的。
大致的引用计数的规则如下:
默认情况下,当创建完一个 ByteBuf 时,它的引用为1。
每次调用 retain()方法, 它的引用就加 1 ;
每次调用 release() 方法,是将引用计数减 1。
如果引用为0,再次访问这个 ByteBuf 对象,将会抛出异常。
如果引用为0,表示这个 ByteBuf 没有地方被引用到,需要回收内存。
Netty的内存回收分为两种情况:
Pooled 池化的内存,放入可以重新分配的 ByteBuf 池子,等待下一次分配。
Unpooled 未池化的 ByteBuf 内存,确保GC 可达,确保 能被 JVM 的 GC 回收器回收到。
4、ByteBuf 的浅层复制
ByteBuf 的浅层复制分为两种,有切片slice 浅层复制,和duplicate 浅层复制。

slice 切片浅层复制
首先说明一下,这是一种非常重要的操作。可以很大程度的避免内存拷贝。这一点,对于大规模消息通讯来说,是非常重要的。
slice 操作可以获取到一个 ByteBuf 的一个切片。一个ByteBuf,可以进行多次的切片操作,多个切片可以共享一个存储区域的 ByteBuf 对象。
slice 操作方法有两个重载版本:
public ByteBuf slice();
public ByteBuf slice(int index, int length);
两个版本有非常紧密的联系。
不带参数的 slice 方法,等同于 buf.slice(buf.readerIndex(), buf.readableBytes()) 调用, 即返回 ByteBuf 实例中可读部分的切片。
而带参数 slice(int index, int length) 方法,可以通过灵活的设置不同的参数,来获取到 buf 的不同区域的切片。
调用slice()方法后,返回的 ByteBuf 的切片,大致如下图:

调用slice()方法后,返回的ByteBuf 切片的属性,大致如下:
slice 的 readerIndex(读指针)的值为 0
slice 的 writerIndex(写指针) 的 值为源Bytebuf的 readableBytes() 可读字节数。
slice 的 maxCapacity(最大容量) 的值为源Bytebuf的 readableBytes() 可读字节数。maxCapacity 与 writerIndex 值相同,切片不可以写。
切片的可读字节数,为自己的 writerIndex - readerIndex。所有,切片和源Bytebuf的 readableBytes() 可读字节数相同。
也就是说,切片可读,不可写。
slice()切片和原ByteBuf的联系:
切片不会拷贝原ByteBuf底层数据,底层数组和原ByteBuf的底层数组是同一个
切片不会改变原 ByteBuf 的引用计数。
根本上,调用slice()方法生成的切片,是 源Bytebuf 可读部分的浅层复制。
duplicate() 浅层复制
duplicate() 返回的是源ByteBuf 的整个对象的一个浅层复制,包括如下内容:
duplicate() 会创建自己的读写指针,但是值与源ByteBuf 的读写指针相同;
duplicate() 不会改变源 ByteBuf 的引用计数
duplicate() 不会拷贝 源ByteBuf 的底层数据
duplicate() 和slice() 方法,都是浅层复制。不同的是,slice() 方法是切取一段的浅层复制,duplicate() 是整个的浅层复制。
浅层复制的问题
浅层复制方法不会拷贝数据,也不会改变 ByteBuf 的引用计数,这就会导致一个问题。
在源 ByteBuf 调用 release() 之后,引用计数为零,变得不能访问。这个时候,源 ByteBuf 的浅层复制实例,也不能进行读写。如果再对浅层复制实例进行读写,就会报错。
因此,在调用浅层复制实例时,可以通过调用一次 retain() 方法 来增加引用,表示它们对应的底层的内存多了一次引用,引用计数为2,在浅层复制实例用完后,需要调用两次 release() 方法,将引用计数减一,不影响源ByteBuf的内存释放。
参考:
https://blog.csdn.net/sigh667/article/details/78021940
https://blog.csdn.net/crazymakercircle/article/details/84205697