假设有Excel文件data.xlsx,其中内容为:
ID age height sex weight
张三 1 39 181 female 85
李四 2 40 180 male 80
王五 3 38 178 female 78
赵六 4 59 170 male 66
现在需要将这个Excel文件中的数据读入pandas,并且在后续的处理中不关心ID列,还需要把sex列的female替换为1,把sex列的male替换为0。本文演示有关的几个操作。
(1)导入pandas模块
>>> import pandas as pd
(2)把Excel文件中的数据读入pandas
df = pd.read_excel('data.xlsx')
df
执行效果:
ID age height sex weight
张三 1 39 181 female 85
李四 2 40 180 male 80
王五 3 38 178 female 78
赵六 4 59 170 male 66
(3)删除ID列
可以得到新的DataFrame:
>>> df.drop('ID', axis=1)
age height sex weight
张三 39 181 female 85
李四 40 180 male 80
王五 38 178 female 78
赵六 59 170 male 66
也可以直接在原DataFrame上原地删除:
df.drop('ID', axis=1, inplace=True)
df
age height sex weight
张三 39 181 female 85
李四 40 180 male 80
王五 38 178 female 78
赵六 59 170 male 66
(4)替换sex列
方法一:使用replace()方法替换sex列,得到新的DataFrame,如果指定参数inplace=True,则可以原地替换。
>>> df.replace({'female':1, 'male':0})
age height sex weight
df.replace({'female':1, 'male':0})
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法二:使用map()方法+lambda表达式,原地替换。
df1 = df[:] df1['sex'] = df1['sex'].map(lambda x:1 if x=='female' else 0) df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法三:使用map()方法+字典,原地替换。
df1 = df[:] df1['sex'] = df1['sex'].map({'female':1, 'male':0}) df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法四:使用loc类,原地替换。
>>>
df1 = df[:] >>> df1.loc[df['sex']=='female', 'sex'] = 1 >>> df1.loc[df['sex']=='male', 'sex'] = 0 >>> df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
二、运用上述功能进行实战
1、先读取一个excel文件:
代码如下:
df = pd.read_excel('file:///D:/文档/Python成绩.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据
如果想知道文件是否读取成功可以用print函数将数据输出
如:
print(df)
然后会显示文件的数据,效果如下:

2、修改excel文件内容:
运用上述的 方法三:使用map()方法+字典,原地替换。
现在要将优秀改为90,良好改为80,及格改为60
代码如下:
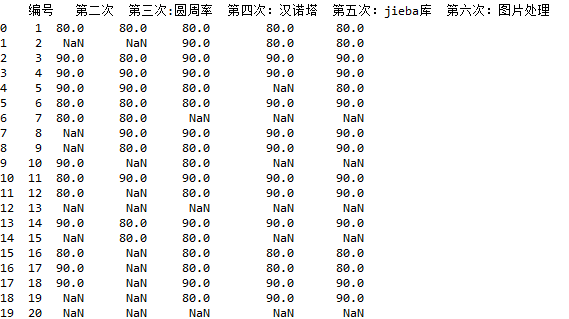
1 df1=df[:] 2 df1['第二次']=df1['第二次'].map({'优秀':90,'良好':80,'及格':60}) 3 df1['第三次:圆周率']=df1['第三次:圆周率'].map({'优秀':90,'良好':80,'及格':60}) 4 df1['第四次:汉诺塔']=df1['第四次:汉诺塔'].map({'优秀':90,'良好':80,'及格':60}) 5 df1['第五次:jieba库']=df1['第五次:jieba库'].map({'优秀':90,'良好':80,'及格':60}) 6 df1['第六次:图片处理']=df1['第六次:图片处理'].map({'优秀':90,'良好':80,'及格':60})
效果如下:
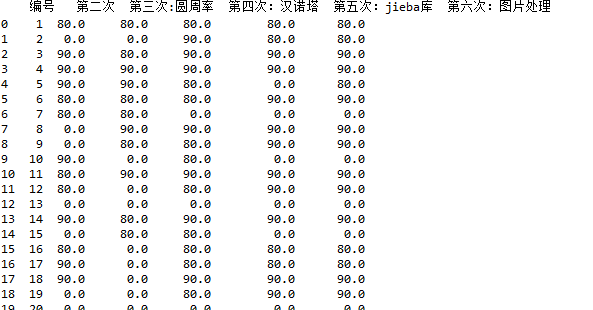
三、再将上述的NaN改为0
只需要用数据清洗之缺失数据填充fillna()就可以完成
运行代码如下:
df1=df1.fillna(0)
print(df1)
效果如下:
四、最后将excel文件保存为csv文件
代码如下:
df1.to_csv('D:/文档\thon.csv')
最后会在你保存的文件你多了一个csv文件。
五、同时可以将csv文件保存为html格式
方法一(用工具实现):
代码如下:
df1.to_html('d:\st.html')
同样会在你保存的文件夹中会多出一个html格式的文件
方法二:
代码如下:
seg1 = ''' <!DOCTYPE HTML> <html> <body> <meta charset=gb2312> <h2 align=center>2016年7月部分大中城市新建住宅价格指数</h2> <table border='1' align="center" width=70%> <tr bgcolor='orange'> ''' seg2 = "</tr> " seg3 = "</table> </body> </html>" def fill_data(locls): seg = '<tr><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td></tr> '.format(*locls) return seg fr = open("D:\文档Python123.csv", "r",encoding="utf-8-sig") ls = [] for line in fr: line = line.replace(" ","") ls.append(line.split(",")) fr.close() fw = open("D:\文档Python5.html", "w") fw.write(seg1) fw.write('<th width="25%">{}</th> <th width="25%">{}</th> <th width="25%">{}</th> <th width="25%">{}</th> '.format(*ls[0])) fw.write(seg2) for i in range(len(ls)-1): fw.write(fill_data(ls[i+1])) fw.write(seg3) fw.close()