并发概念
同时拥有两个或者多个线程,如果程序在单核处理器上运行,多个线程将交替地换入或者换出内存,这些线程是同时存在的,每个线程都处于执行过程中的某个状态。如果运行在多核处理器上,程序中的每个线程都将分配到一个处理器核上,因此可以同时执行。其聚焦点是多个线程操作相同的资源,保证线程安全,合理使用资源。
高并发概念
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
二者对比
并发:多个线程操作相同的资源,保证线程的安全,合理使用资源。
高并发:服务能同时处理很多请求,提高程序性能。
并发的优势与风险
1、优势
(1)速度:同时处理多个请求,响应更快;复杂的操作可以分成多个进程(或线程)同时进行
(2)设计:程序设计在某些情况下更简单,也可以有更多的选择
(3)资源利用:CPU能够等待IO的时候能够做一些其他的事情
2、风险
(1)安全性:多个线程共享数据时可能会产生于期望不相符的结果
(2)活跃性:某个操作无法继续进行下去时,就会发生活跃性问题。比如:死锁、饥饿等问题。
(3)性能:线程过多时会使得:CPU频繁切换,调度时间增多;同步机制;消耗过多内存
CPU多级缓存
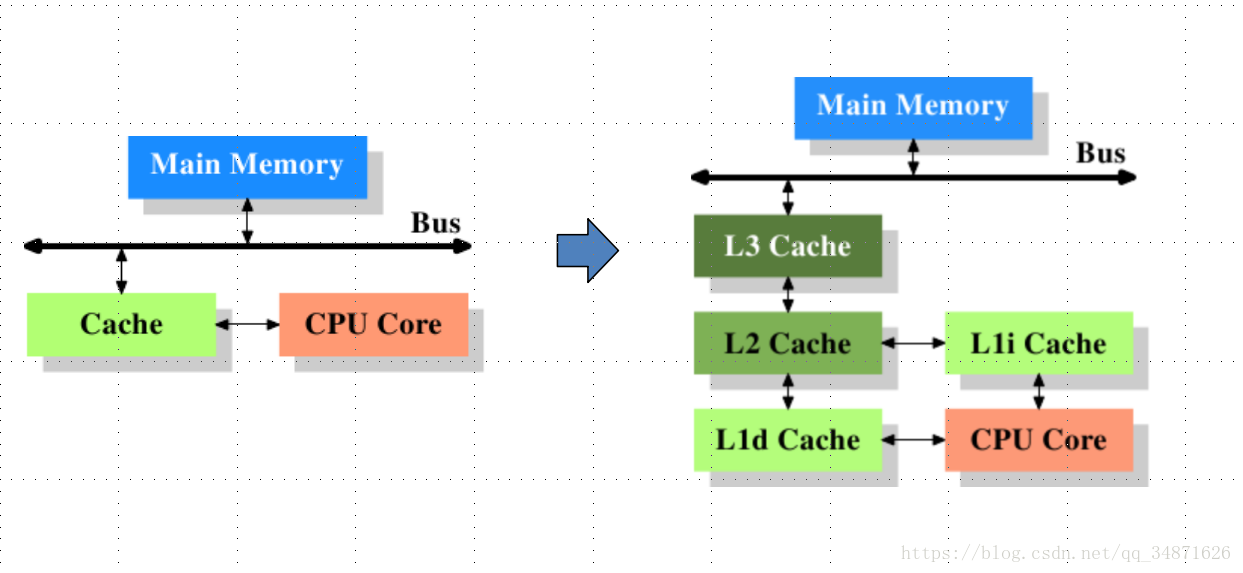
上述左图是最简单的高速缓存的图示,数据的读取和存储都经过高速缓存,CPU核心和高速缓存之间有一条特殊的快速通道,在这个简化的图示上,主存(main memory)与高速缓存(cache)都连在系统总线上。这条总线同时还用于其他组件之间的通信。在高速缓存出现后不久,系统变得更加复杂,高速缓存与主存之间的速度差异被拉大,直到加入了另一级的缓存(由于加大一级缓存的做法从经济上考虑是行不通的,所以有了二级缓存甚至三级缓存)。新加入的这些缓存比第一缓存更大但是更慢。
为什么需要CPU Cache?
CPU的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费资源。所以cache的出现,是为了缓解CPU和内存之间速度的不匹配,结构就是cpu -> cache -> memory。
CPU Cache有什么意义?
缓存的容量远远小于主存,所以缓存不命中的情况在所难免,其主要意义存在以下两点:
时间局部性:如果某个数据被访问,那么在不久的将来,它很可能被再次访问。
空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问。
CPU多级缓存之缓存一致性(MESI)
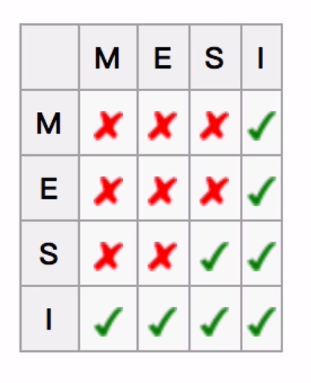
MESI这个协议为了保证多个CPU cache之间缓存共享数据的一致性,定义了cache line的四种状态,而CPU对cache 的四种操作,可能会产生不一致的状态。因此,缓存控制器监听到本地操作和远程操作的时候需要对地址一致的cache line做出一定的修改,从而保证数据在多个缓存之间保持一致性。MESI其实是四种状态的缩写:
M:modified 被修改 E:Exclusive 独享 S:shared 共享 I:invalid 无效
- Modified (修改):该缓存行只被缓存在该cpu的缓存中,并且是被修改过的。因此它与主存中数据是不一致的。该缓存行中的内存需要在未来的某个时间点(允许其他cpu读取主存中相应的内存之前)写回主存,当这里的值被写回主存之后,该缓存行的状态会变为E的状态。
- Exclusive (独享):缓存只被缓存在该cpu的缓存中,它是未被修改过的,是与主存中的数据一致,这个状态可以在任何时刻,当有其他cpu读取该内存时变为S:shared共享状态。同样的,当cpu修改该缓存行的内容时,该状态可以变为modify的状态。
- Shared (共享):该状态意味着缓存行可能被多个cpu进行缓存,并且各缓存中的数据与主存中的数据是一致的,当有一个cpu修改该缓存行的时候,其他cpu中该缓存行可以被作废。变成invalid的状态。
- Invalid (无效):表示该缓存无效,可能是有其他cpu修改了该缓存行。
四种CPU操作
local read:读本地缓存中的数据
local write:将数据写到本地的缓存里
remote read:将内存中数据读取过来
remote write:将数据写回到主存中
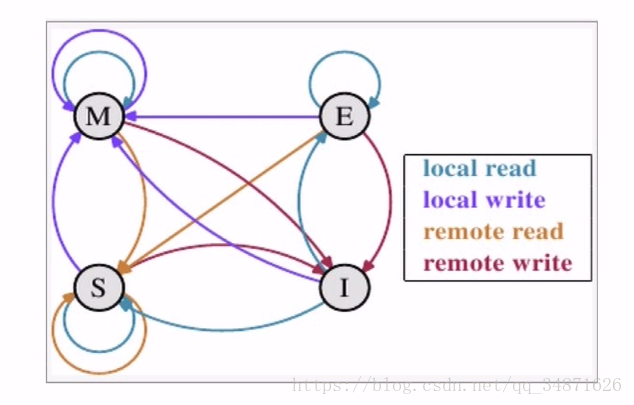
想要理解MESI协议,本质上要讲这16种状态转化的情况讨论清楚,状态之间的相互装换关系,可以使用下图来表示:
场景
当前CPU中数据的状态是modify,表示当前CPU中拥有最新数据,虽然主存中的数据和当前CPU中的数据不一致,但是以当前CPU中的数据为准;
LR:此时如果发生local read,即当前CPU读数据,直接从cache中获取数据,拥有最新数据,因此状态不变;
LW:直接修改本地cache数据,修改后也是当前CPU拥有最新数据,因此状态不变;
RR:因为本地内存中有最新数据,因此当前CPU不会发生RR和RW,当本地cache控制器监听到总线上有RR发生的时,必然是其他CPU发生了读主存的操作,此时为了保证一致性,当前CPU应该将数据写回主存,而随后的RR将会使得其他CPU和当前CPU拥有共同的数据,因此状态修改为S;
RW:同RR,当cache控制器监听到总线发生RW,当前CPU会将数据写回主存,因为随后的RW将会导致主存的数据修改,因此状态修改成I;
场景
当前CPU中的数据状态是exclusive,表示当前CPU独占数据(其他CPU没有数据),并且和主存的数据一致;
LR:从本地cache中直接获取数据,状态不变;
LW:修改本地cache中的数据,状态修改成M(因为其他CPU中并没有该数据,因此不存在共享问题,不需要通知其他CPU修改cache line的状态为I);
RR:因为本地cache中有最新数据,因此当前CPU cache操作不会发生RR和RW,当cache控制器监听到总线上发生RR的时候,必然是其他CPU发生了读取主存的操作,而RR操作不会导致数据修改,因此两个CPU中的数据和主存中的数据一致,此时cache line状态修改为S;
RW:同RR,当cache控制器监听到总线发生RW,发生其他CPU将最新数据写回到主存,此时为了保证缓存一致性,当前CPU的数据状态修改为I;
场景
当前CPU中的数据状态是shared,表示当前CPU和其他CPU共享数据,且数据在多个CPU之间一致、多个CPU之间的数据和主存一致;
LR:直接从cache中读取数据,状态不变;
LW:发生本地写,并不会将数据立即写回主存,而是在稍后的一个时间再写回主存,因此为了保证缓存一致性,当前CPU的cache line状态修改为M,并通知其他拥有该数据的CPU该数据失效,其他CPU将cache line状态修改为I;
RR:状态不变,因为多个CPU中的数据和主存一致;
RW:当监听到总线发生了RW,意味着其他CPU发生了写主存操作,此时本地cache中的数据既不是最新数据,和主存也不再一致,因此当前CPU的cache line状态修改为I;
场景
当前CPU中的数据状态是invalid,表示当前CPU中是脏数据,不可用,其他CPU可能有数据、也可能没有数据;
LR:因为当前CPU的cache line数据不可用,因此会发生RR操作,此时的情形如下。
A. 如果其他CPU中无数据则状态修改为E;
B. 如果其他CPU中有数据且状态为S或E则状态修改为S;
C. 如果其他CPU中有数据且状态为M,那么其他CPU首先发生RW将M状态的数据写回主存并修改状态为S,随后当前CPU读取主存数据,也将状态修改为S;
LW:因为当前CPU的cache line数据无效,因此发生LW会直接操作本地cache,此时的情形如下。
A. 如果其他CPU中无数据,则将本地cache line的状态修改为M;
B. 如果其他CPU中有数据且状态为S或E,则修改本地cache,通知其他CPU将数据修改为I,当前CPU中的cache line状态修改为M;
C. 如果其他CPU中有数据且状态为M,则其他CPU首先将数据写回主存,并将状态修改为I,当前CPU中的cache line转台修改为M;
RR:监听到总线发生RR操作,表示有其他CPU读取内存,和本地cache无关,状态不变;
RW:监听到总线发生RW操作,表示有其他CPU写主存,和本地cache无关,状态不变;
CPU多级缓存之乱序执行优化
乱序执行优化:处理器为提高运算速度而做出违背代码原有顺序的优化;
例如:
int a=10;
int b=20;
int result = a + b;
在cpu乱序优化的时候,代码可能变为:
int b=10;
int a=20;
int result = a + b;
在多核情况下,后写入经过乱序优化,后写入的数据未必真的后写入。如果我们不做任何防护措施,处理器得出的结果跟我们逻辑得出的结果可能不一致。