需求:
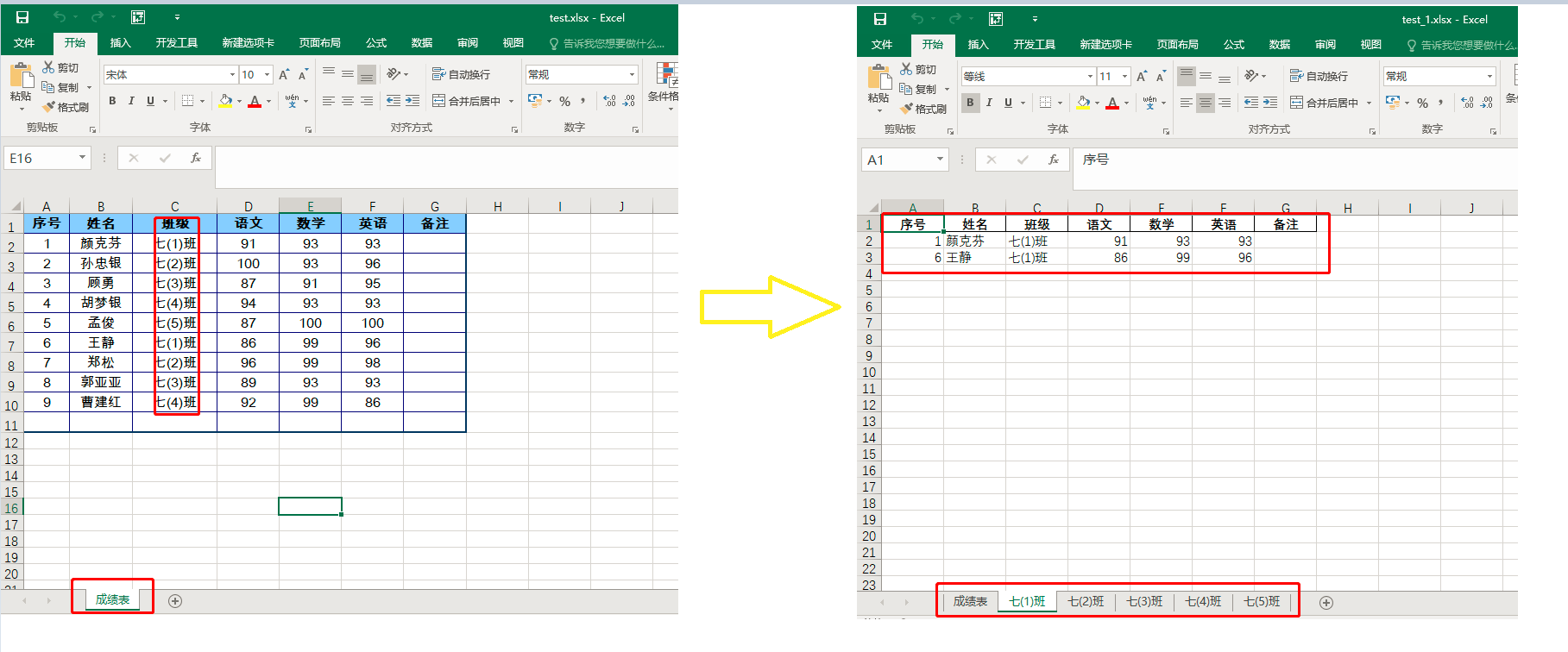
方法1、 循环插入表、写入值
import os
import pandas as pd
import openpyxl
wb_in = 'E:\excel_vba\test.xlsx'
df = pd.read_excel(wb_in)
wb = openpyxl.load_workbook(wb_in) # 加载工作表
new_sheet_name = df['班级'].drop_duplicates()
for k, name in enumerate(new_sheet_name):
sheet = wb.create_sheet(title=name) # 插入工作表,指定名称,index 参数默认为 -1
# 写入表头
for i, v in enumerate(df.columns):
sheet.cell(row=1, column=i+1).value = v
for i, row in enumerate(df[df['班级']==new_sheet_name[k]].values):
for j, v in enumerate(row):
sheet.cell(row=i+2, column=j+1).value = v # 第 2 行, 第 1 列开始写入数据
wb_out = os.path.join(os.path.dirname(wb_in), 'test_1.xlsx')
wb.save(wb_out)
方法2、直接保存 DataFrame
import os
import pandas as pd
import openpyxl
wb_in = 'E:\excel_vba\test.xlsx'
wb_out = os.path.join(os.path.dirname(wb_in), 'test_1.xlsx')
df = pd.read_excel(wb_in)
new_sheet_names = df['班级'].drop_duplicates()
book = openpyxl.load_workbook(wb_in)
writer = pd.ExcelWriter(wb_out, engine='openpyxl')
writer.book = book
for name in new_sheet_names:
df_a = df[df['班级']==name]
df_a.to_excel(writer, sheet_name=name, index=False)
writer.save()