本文旨在演示rpart包的决策树分类用法,以及利用rpart.plot对结果进行可视化。决策树(分类树)是一种十分常用的分类方法,是一种监管学习;所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
测试数据选用MushroomDataSet(蘑菇数据集),其数据属性如下:
Attribute Information:
- cap-shape: bell=b,conical=c,convex=x,flat=f, knobbed=k,sunken=s
- cap-surface: fibrous=f,grooves=g,scaly=y,smooth=s
- cap-color: brown=n,buff=b,cinnamon=c,gray=g,green=r,pink=p,purple=u,red=e,white=w,yellow=y
- bruises?: bruises=t,no=f
- odor: almond=a,anise=l,creosote=c,fishy=y,foul=f, musty=m,none=n,pungent=p,spicy=s
- gill-attachment: attached=a,descending=d,free=f,notched=n
- gill-spacing: close=c,crowded=w,distant=d
- gill-size: broad=b,narrow=n
- gill-color: black=k,brown=n,buff=b,chocolate=h,gray=g,green=r,orange=o,pink=p,purple=u,red=e, white=w,yellow=y
- stalk-shape: enlarging=e,tapering=t
- stalk-root: bulbous=b,club=c,cup=u,equal=e, rhizomorphs=z,rooted=r,missing=?
- stalk-surface-above-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-surface-below-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-color-above-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o,pink=p,red=e,white=w,yellow=y
- stalk-color-below-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o,pink=p,red=e,white=w,yellow=y
- veil-type: partial=p,universal=u
- veil-color: brown=n,orange=o,white=w,yellow=y
- ring-number: none=n,one=o,two=t
- ring-type: cobwebby=c,evanescent=e,flaring=f,large=l,none=n,pendant=p,sheathing=s,zone=z
- spore-print-color: black=k,brown=n,buff=b,chocolate=h,green=r,orange=o,purple=u,white=w,yellow=y
- population: abundant=a,clustered=c,numerous=n, scattered=s,several=v,solitary=y
- habitat: grasses=g,leaves=l,meadows=m,paths=p, urban=u,waste=w,woods=d
data数据下载地址参见关联规则-R语言实现一文。
代码
library(rpart)
library(rpart.plot)
data =read.csv(file.choose(),head=F)
str(data_ms)
table(data_ms$X1)
e p
4208 3916
prop.table(table(data_ms$X1))
e p
0.5179714 0.4820286
prop.table(table(data_ms$X1,data_ms$X2),2)
b c f k s x
e 0.8938053 0.0000000 0.5063452 0.2753623 1.0000000 0.5328228
p 0.1061947 1.0000000 0.4936548 0.7246377 0.0000000 0.4671772
fit <- rpart(X1 ~.,
data=data_ms,
method="class")
#分类结果可视化
rpart.plot(reg, type=4, extra=1,shadow.col="gray", box.col="green",
border.col="blue", split.col="red",split.cex=1.2,main="决策树")
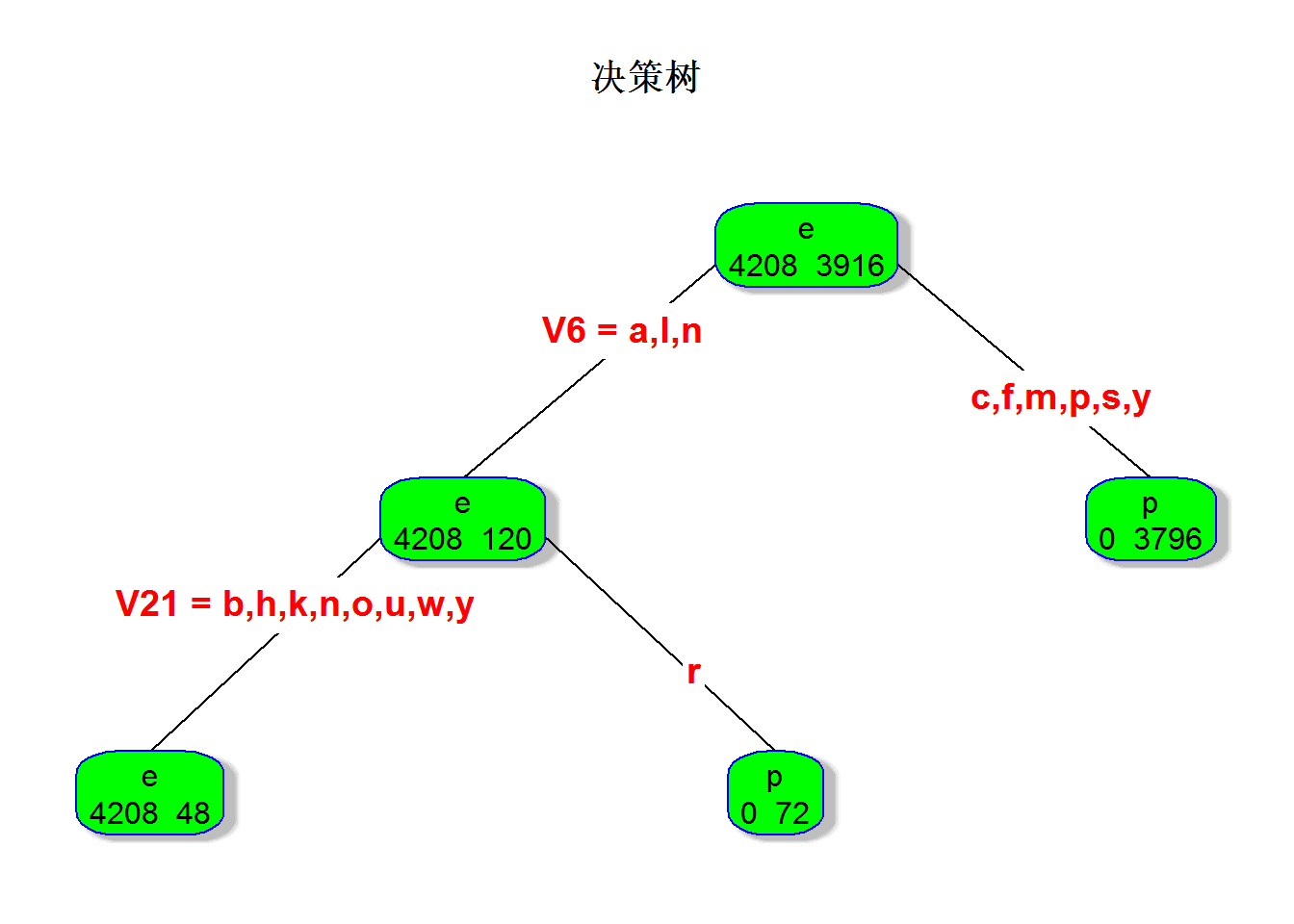
可以看出,蘑菇数据更适合通过决策树算法进行分类处理,分类规则评判蘑菇有毒与否清晰明了。
反馈与建议
- 作者:ShangFR
- 邮箱:shangfr@foxmail.com