一、Beanstalkd是什么?
Beanstalkd是一个高性能,轻量级的分布式内存队列
二、Beanstalkd特性
1、支持优先级(支持任务插队)
2、延迟(实现定时任务)
3、持久化(定时把内存中的数据刷到binlog日志)
4、预留(把任务设置成预留,消费者无法取出任务,等某个合适时机再拿出来处理)
5、任务超时重发(消费者必须在指定时间内处理任务,如果没有则认为任务失败,重新进入队列)
三、Beanstalkd核心元素
生产者 -> 管道(tube) -> 任务(job) -> 消费者
Beanstalkd可以创建多个管道,管道里面存了很多任务,消费者从管道中取出任务进行处理。
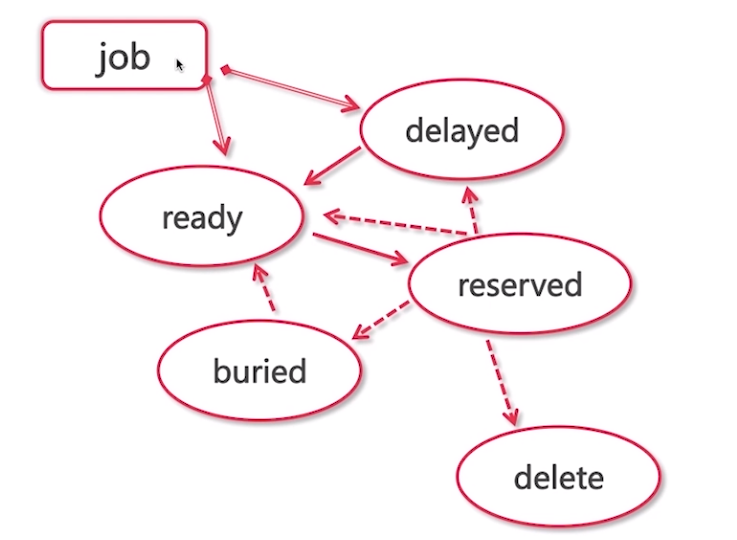
四、任务job状态
delayed 延迟状态
ready 准备好状态
reserved 消费者把任务读出来,处理时
buried 预留状态
五、安装Beanstalkd
http://kr.github.io/beanstalkd/download.html
下载beanstalkd-1.10.tar.gz
> tar -xf beanstalkd-1.10.tar.gz
> cd beanstalkd-1.10
> make
查看beanstalkd参数信息
> ./beanstalkd -h
启动beanstalkd
> ./beanstalkd -l 127.0.0.1 -p 11300 -b /data/beanstalkd/binlog &
-b表示开启binlog,断电后重启自动恢复任务
六、下载Pheanstalk类
首先安装composer
> curl -sS https://getcomposer.org/installer | php > mv composer.phar /usr/local/bin/composer > composer require pda/pheanstalk
编写一个简单脚本查看信息
<?php require './vendor/autoload.php'; use PheanstalkPheanstalk; $p = new Pheanstalk('127.0.0.1', 11300); //查看beanstalkd当前的状态信息 var_dump($p->stats());
七、Pheanstalk使用方法
维护方法
stats() 查看状态方法
listTubes() 目前存在的管道
listTubesWatched() 目前监听的管道
statsTube() 管道的状态
useTube() 指定使用的管道
statsJob() 查看任务的详细信息
peek() 通过任务ID获取任务
生产者方法
putInTube() 往管道中写入数据
put() 配合useTube()使用
消费者方法
watch() 监听管道,可以同时监听多个管道
ignore() 不监听管道
reserve() 以阻塞方式监听管道,获取任务
reserveFromTube()
release() 把任务重新放回管道
bury() 把任务预留
peekBuried() 把预留任务读取出来
kickJob() 把buried状态的任务设置成ready
kick() 批量把buried状态的任务设置成ready
peekReady() 把准备好的任务读取出来
peekDelayed() 把延迟的任务读取出来
pauseTube() 给管道设置延迟
resumeTube() 取消管道延迟
touch() 让任务重新计算ttr时间,给任务续命
八、使用消息队列的10个理由:
1. 解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息队列在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2. 冗余
有时在处理数据的时候处理过程会失败。除非数据被持久化,否则将永远丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。在被许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理过程明确的指出该消息已经被处理完毕,确保你的数据被安全的保存直到你使用完毕。
3. 扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的;只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
4. 灵活性 & 峰值处理能力
当你的应用上了Hacker
News的首页,你将发现访问流量攀升到一个不同寻常的水平。在访问量剧增的情况下,你的应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住增长的访问压力,而不是因为超出负荷的请求而完全崩溃。请查看我们关于峰值处理能力的博客文章了解更多此方面的信息。
5. 可恢复性
当体系的一部分组件失效,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。而这种允许重试或者延后处理请求的能力通常是造就一个略感不便的用户和一个沮丧透顶的用户之间的区别。
6. 送达保证
消息队列提供的冗余机制保证了消息能被实际的处理,只要一个进程读取了该队列即可。在此基础上,IronMQ提供了一个"只送达一次"保证。无论有多少进程在从队列中领取数据,每一个消息只能被处理一次。这之所以成为可能,是因为获取一个消息只是"预定"了这个消息,暂时把它移出了队列。除非客户端明确的表示已经处理完了这个消息,否则这个消息会被放回队列中去,在一段可配置的时间之后可再次被处理。
7.排序保证
在许多情况下,数据处理的顺序都很重要。消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。IronMO保证消息浆糊通过FIFO(先进先出)的顺序来处理,因此消息在队列中的位置就是从队列中检索他们的位置。
8.缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行--写入队列的处理会尽可能的快速,而不受从队列读的预备处理的约束。该缓冲有助于控制和优化数据流经过系统的速度。
9. 理解数据流
在一个分布式系统里,要得到一个关于用户操作会用多长时间及其原因的总体印象,是个巨大的挑战。消息系列通过消息被处理的频率,来方便的辅助确定那些表现不佳的处理过程或领域,这些地方的数据流都不够优化。
10. 异步通信
很多时候,你不想也不需要立即处理消息。消息队列提供了异步处理机制,允许你把一个消息放入队列,但并不立即处理它。你想向队列中放入多少消息就放多少,然后在你乐意的时候再去处理它们。
补充一个: 多语言通信,比如用php生产一个job,用python或者其他语言作为消费者来处理