一、基本介绍
1,时序数据介绍
(1)时间序列数据(Time Series Data,TSD,以下简称时序)从定义上来说,就是一串按时间维度索引的数据。
(2)简单的说,就是这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。它普遍存在于 IT 基础设施、运维监控系统和物联网中。
2,时序数据库介绍
(1)时序数据库产品的发明都是为了解决传统关系型数据库在时序数据存储和分析上的不足和缺陷,这类产品被统一归类为时序数据库(TSDB)
(1)在传统关系型数据库上加上时间戳一列并不能真正作为时序数据库。因为时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。此时传统关系型数据库就会出现问题。
(2)MySQL 在海量的时序数据场景下存在如下问题:
- 存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
- 维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
- 写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
- 查询性能差:适用于交易处理,海量数据的聚合分析性能差。
(3)另外,使用 Hadoop 生态(Hadoop、Spark 等)存储时序数据会有以下问题:
- 数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
- 查询性能差:不能很好的利用索引,依赖 MapReduce 任务,查询耗时一般在分钟级。
(2)时序数据库时序数据的特点对写入、存储、查询等流程进行了优化,具体特点如下:
- 数据压缩存储:利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比;通过预降精度,对历史数据做聚合,节省存储空间。
- 高并发写入:批量写入数据,降低网络开销;数据先写入内存,再周期性的 dump 为不可变的文件存储。
- 低查询延时,高查询并发:优化常见的查询模式,通过索引等技术降低查询延时;通过缓存、routing 等技术提高查询并发。
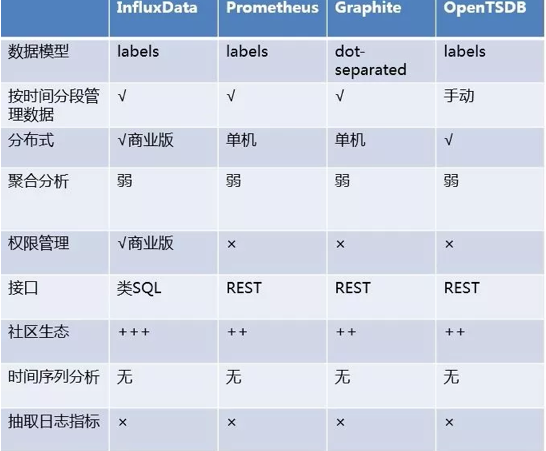
(3)目前行业内比较流行的开源时序数据库产品有 InfluxDB、OpenTSDB、Prometheus、Graphite 等,其产品特性对比如下图所示:
3,InfluxDB 介绍
(1)InfluxDB 是一个开源分布式时序、时间和指标数据库,使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展,是 InfluxData 的核心产品。
注意:InfluxDB 不是一个完整的 CRUD 数据库,它更像是一个 CR-ud 数据库。它优先考虑的是增加和读取数据而不是更新和删除数据的性能,而且它阻止了某些更新和删除行为使得创建和读取数据更加高效。
(2)InfluxDB 自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。 此外它还有如下特性:
- 内置 HTTP 接口,使用方便
- 数据可以打标记,这样查询可以很灵活
- 类 SQL 的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
(3)InfluxDB 常用于性能监控,应用程序指标,物联网传感器数据和实时分析等的后端存储。
4,InfluxDB 基本概念

(1)database
- database 类似传统数据库中的数据库概念。
- 一个数据库可以有多个 measurement,retention policy,continuous queries 以及 user。
(2)measurement
- measurement 类似传统数据库中的表概念。
- measurement 是 fields,tags 以及 time 列的容器,measurement 的名字用于描述存储在其中的字段数据,类似 mysql 的表名。
(3)point
- point 类似传统数据库中表中的一行数据
- point 的数据结构由时间戳(time)、标签(tags)、数据(fields)三部分组成
(4)timestamp
- 既然是时间序列数据库,influxdb 的数据都有一列名为 time 的列,里面存储 UTC 时间戳。
(5)field key、field value、field set
- field 为字段,在 influxdb 中,字段必须存在(即数量必须 >=1)。注意,字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及 tag。
- 其中 field key 为字段名,field value 为字段值,field value 可以为 string,float,integer 或 boolean 类型
- field key 和 field value 对组成的集合称之为 field set
(6)tag key、tag value、tag set
- tag 为标签,在 InfluxDB 中可以没有 tag(即数量 >=0)。不同于 field,tag 是有索引的。
- 其中 tag key 为标签名,tag value 为标签值,tag value 只能是 string 类型
- tag key 和 tag value 对组成的集合称之为 tag set
(7)retention policy
- retention policy 指数据保留策略(更详细介绍可以看本文下方附录部分)。
- measurement 默认会有一个 autogen 的保留策略,autogen 中的数据永不删除且备份数 replication 为 1(只有一份数据,在集群中起作用)。
(8)series
- series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series
- 同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
附:InfluxDB 保留策略(retention policy)
(1)每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,在集群中的副本个数为 1。
(2)插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。
(3)用户可以自己设置保留策略(查看、新建、修改、删除),例如保留最近 2 小时的数据。InfluxDB 会定期清除过期的数据。
(4)建议在数据库建立的时候设置存储策略,不建议设置过多且随意切换
create database testdb2 with duration 30d
(5)每个数据库可以有多个过期策略,使用如下语句查看:
show retention policies on "db_name"
(6)Shard 在 influxdb 中是一个比较重要的概念,它和 retention policy 相关联:
- 每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7 点 - 8 点 的数据落入 shard0 中,8 点 - 9 点的数据则落入 shard1 中。
- 每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
- 这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。