凡是高效的排序算法无疑都是采用了分治的策略。我们先来看一下什么是分治的思想:
分治法,字面意思是“分而治之”,就是把一个复杂的问题分成多个相同或相似的子问题,再把子问题分成更小的子问题直到最后子问题可以简单地直接求解,原问题的解即子问题的解的合并。即,分治法的思想是将原问题拆解成相同或者相似的子问题,直到子问题可以简单的直接求解。
再来看一下递归所蕴含的思想:递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解。
也就是说:分治法是一种思想,分治法将问题拆解成子问题,但是分治法并没有给出求解这些子问题的方法!而递归则是一种策略,递归可以用于解决这些同类的子问题。
归并排序
关于归并排序的Java代码和动图演示,可以看下面这个博客:https://www.cnblogs.com/l199616j/p/10604351.html
关于归并排序的c++代码,可以看下面这篇博客:https://blog.csdn.net/m0_38068229/article/details/81262282
下面,我将深入详细的分析归并递归的过程,并讲解递归的详细过程,并给出其中的要点:
我们以下面的数组为例子,用归并排序的方法将上述数组排序。方法:递归:
9 7 8 4 1 6
首先,先表明在归并排序中的第一个要点:将数组均等的一分为二.,这是什么意思呢?,也就是我们不是将数组拆分成:
9 7 8 4 1 6 ——>9 7|8 4 1 6
尽管这也是将原问题分解成同类的子问题,但是这些子问题的规模不一致,但是请别搞错了,这仍然是分治,而且我们仍然可以采用递归的方式继续求解这些子问题。也就是说:分治与递归并不要求我们必须将子问题划分成同等规模大小的问题(尽管这好像看起来划分成同等规模似乎更为合理)。实际上,快速排序算法就不是采用均分策略,但人家依然采用的是分治思想。因此,请记住:
归并排序采用了递归的策略,但是数组均分策略是归并的第一特点! 也就是,我们会将数组划分成:
9 7 8 4 1 6 ——>9 7 8|4 1 6
那么现在,我们问自己:现在这个子问题,我能解决吗?很多人会回答?还不能...因为子问题还不够小。
你之所以会这么回答,也是因为经验主义,这样会限制你修改算法的思维,假如我们将数组划分的很小了,只要我们认为能解决了,那么这个划分的过程就可以结束了。比如上述我们可以采用O(n2)的算法解决子问题,也不是不可以。所以,没有任何算法是完美的和绝对的。
那么这里,既然我们单纯的讨论递归的解决排序,我们自然可以继续划分上述子问题:
9 7 8 4 1 6 ——>9 7 8|4 1 6 -->9 7|8|4 1|6
这个时候,有人会问:这样划分,什么时候是个头呢?
此时,你应该问自己这么一个问题:这个问题原本要解决什么问题?答:对数组排序。那么子问题的目标自然也是对数组排序,那么分治问题的思想是,子问题解决了,原问题就可以解决;那么子问题解决了是指什么:子问题排好序了!继续追问:什么时候子问题排好序了:答案:子问题只剩下一个元素的时候,此时子数组自然就是有序的了。
即,划分的终点是:
9 7 8 4 1 6 ——>9 7 8|4 1 6 -->9 7|8|4 1|6 -->9|7|8|4|1|6
用伪代码表示:
1 if(length == 1)//length为子数组的长度 2 return;
即:如果子数组的长度为1:那么就可以返回。至此,递归的“递”过程执行完毕,我们再来问自己一遍:递归的“递”过程,完成了什么?答:完成了将原问题划分成子问题的过程,
并且最终的子问题都是有解的(对于这里而言,都是有序的,而子问题有解是所有递归的终结条件,请记住)
那么递归的“归”过程呢?一言蔽之:反向求解每个子问题的解,直到求出原问题的解。
我们再来反向思考一下:如何考虑这个归的过程。最后一步是:每个子数组只有一个元素,因此这个数组是有序的。那么它的上一级是什么?每个数组有两个元素,这两个元素是有序的。也就是说,我们进一步考虑一般问题就是:每个子数组上一组的问题就是:在两个子数组都是有序的情况下,将这两个有序的子数组合并成一个有序的子数组。这个就是归并排序的第二要点。
伪代码表示为:
1 sort(orderdArray1,orderdarray2,array3) 2 { 3 ... 4 array3 is order; 5 }
我们用整个图表示上述过程。

总结一下归并排序的两大特点:
- 在“递”的过程中,对数组均等一分为二,再将子数组,一分为二....;
- 在“归”的过程中,将这两个有序的子数组合并成一个有序的子数组;
我们来看看具体的代码:
1 void MergeSort(vector<int>&data,int l,int r){ //使用递归对数组data从索引i到索引j之间的元素排序。 2 cout<<"the process of digui:"<<l<<","<<r<<endl; 3 if(r-l+1 == 1)//递归结束条件 4 return; 5 int mid = l+(r-l)/2; 6 MergeSort(data,l,mid);// 对前半部分继续排序 7 MergeSort(data,mid+1,r);//对后半部分继续排序 8 Sort(data,l,mid,r);//将两个有序数组归并成一个有序数组 9 }
其中,我们暂时并不给出Sort函数的具体实现,下文完整的代码中将会给出,这并不是我们要考虑的重点。很多人即使看了我之前的分析和上面的代码,仍然感觉有些模糊,原因在于,你对递归调用的恐惧和对其底层原理的不清楚,我们一步一步来:
递归而言,首先肯定 要给出递归结束条件,上述代码:r-l+1 ==1 即表述为:最终子数组只有一个元素时候,递归结束!
这里有人要问了:为何这里判断之后直接return了,不是要给出最小子问题的解之后才返回吗?比如求斐波那契数列第N项,不是返回前不是给出了第一项和第二项的值吗?那么,请别忘了排序的排序的子问题是将子数组排好序,那么其终止条件是什么:当然是将最小子数组排好序并返回。正如求斐波那契第N项时候,终止条件是:给出最开始的两项并返回。从这点看,两者在逻辑上是完全相同的。也就是,递归的结束条件一定是:原最小子问题的解!!!而这里,当递归到最后一步时候,子数组只剩一下一个元素,而这个元素本身就是有序的,所以直接return即可(在其他问题中没准需要你给出最小子问题的解)
递归结束条件讨论完了,我们该讨归并的第二步,将原数组均分,一分为二,再将子数组,并求解每一部分子数组的正确序列;再将子数组一分为二,并且求解每一部分子数组的正确序列....!这里面有很明显的递归的意味,请深入体会。
我们再复述一遍上述过程:
递归的
- 将数组平均一份二位
- 求解前半部分的正确顺序
- 求解后半部分的正确的顺序
- 将排序好的前半部分和排序好的后半部分合并成一个排序好的大数组。
怎么样,有内味了吧。。。可能你还是会问:道理我都懂,可是这样为何就能将原数组排序啊。问出这个问题说明,你对递归调用的过程并没有一个清晰的认识,所以还是一知半解的。这里,我将给出详细分析,仔细看下图:

下述,l与r的变化是对上述的解释:
l r 9 7 8 4 1 6;mid1 = 2;(length≠1,继续调用) l r 9 7 8 ;mid2 = 1;(length≠1,继续调用) l r 9 7 ;mid3 = 0; (length≠1,继续调用) l(r) 9 ;mid4 = 0;(length == 1,结束)结束
上述中,我故意将函数名字写成了MergeSort1...等等,目的是为了说明:递归函数和普通函数本质是一致的,并无本质区别,当发生自己调用自己的时候,你完全可以认为,它调用了一个其他函数,只是这个函数好像和自己长得一模一样,俗称双胞胎。并且和普通调用一样,每个调用都会生成一个独立的栈空间,因此,mid值并不是只有一个mid,而是在每个调用体里都有一个mid只存在自己的栈空间。
因此,这里说明关于递归调用的两点:
- 递归调用和普通函数调用并无区别,你可以把递归调用想成调用了一个和自己长得一样的其他函数;
- 既然是函数调用,栈空间就是独立的,哪怕它是递归调用,也是如此;
你可以按照我上面的思路,继续分析,到底是怎样完成排序的。我在此不作过多废话废话,非常建议画图领悟
下面贴出我的测试完整代码:
1 # include<iostream> 2 #include<vector> 3 using namespace std; 4 void Sort(vector<int>&,int ,int ,int ); 5 void MergeSort(vector<int>&,int ,int ); 6 int main() 7 { 8 vector<int> data; 9 for(int i = 1;i <= 8;i++) 10 data.push_back(8-i); 11 cout<<"the initial order:"; 12 for(int i = 0;i < 8;i++) 13 cout<<data[i]<<" "; 14 cout<<endl; 15 16 cout <<"strat sort..."<<endl; 17 MergeSort(data,0,7); 18 19 cout<<"the sorted order:"; 20 for(int i = 0;i < 8;i++) 21 cout<<data[i]<<" "; 22 cout<<endl; 23 24 system("pause"); 25 return 0; 26 } 27 void MergeSort(vector<int>&data,int l,int r){ //使用递归对数组data从索引i到索引j之间的元素排序。 28 cout<<"the process of digui:"<<l<<","<<r<<endl; 29 if(r-l+1 == 1)//递归结束条件 30 return; 31 int mid = l+(r-l)/2; 32 MergeSort(data,l,mid);// 对前半部分继续排序 33 MergeSort(data,mid+1,r);//对后半部分继续排序 34 Sort(data,l,mid,r);//将两个有序数组归并成一个有序数组 35 } 36 void Sort(vector<int>&data,int l,int mid,int r)//将两个有序数组合并成一个有序数组,这是归并排序的前提 37 { 38 vector<int> tmp(r-l+1);//一个临时的空间,存放排序好的数组,最后将这个数组赋值给data[l]到data[r] 39 int i = l;//数组1索引 40 int j = mid+1;//数组2索引 41 int k = 0; 42 while((i<=mid) && (j <= r))//两个索引都没有超出边界 43 { 44 if(data[i]<=data[j]) 45 tmp[k++] = data[i++]; 46 else 47 tmp[k++] = data[j++]; 48 } 49 while((i > mid) && (j <= r))//索引i超出数组1边界(数组1访问完毕),而索引j还未超出边界 50 { 51 tmp[k++] = data[j++]; 52 } 53 while((j > r) && (i <= mid))//索引j超出数组2边界(数组2访问完毕),而索引i还未超出边界
54 { 55 tmp[k++] = data[i++]; 56 } 57 for(int i = 0;i <r-l+1;i++) 58 data[l+i]= tmp[i]; //这一步对于data的索引极其容易出错,需要清楚的是tmp总是从0开始,而data则是从左边界l开始。 59 }
这里稍微对有序数组合并成大数组的函数Sort()做一个解释:
Sort(vector<int>&data,int l,int mid,int r)中data表示数组,表示已排序数组1的左边界,mid表示已经排序数组1的右边界(显然mid+1表示已排序数组2的左边界),r表示已经已排序数组的右边界。
因为这两个已经排序的数组其实都是原数组的一部分(地址空间没变),所以我们要想将这两个已经排好序的数组合并成一个数组,则需要一个额外的临时空间,临时空间用来缓存重新排序的数组。最后将这个数组赋值到原数组。
我们的输出结果是:
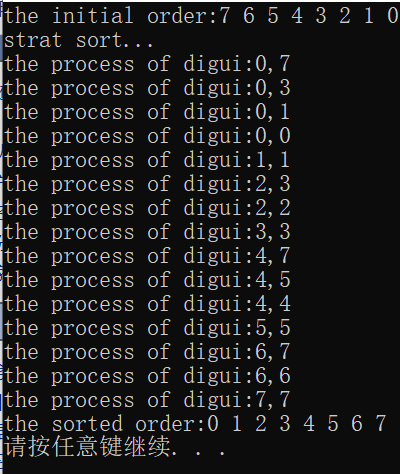
我在函数中设置了调用提醒,每次进行调用,我都会打印当前调用,从这里你也画出图形可以分析递归的过程。
最后我们再次做一下总结:
归并排序三大特点:
在“递”的过程中,对数组均等一分为二,再将子数组,一分为二....;
在“归”的过程中,将这两个有序的子数组合并成一个有序的子数组
“归过程每次合并数组的时候,要产生一个和原来两个数组同样大小空间的数组作为缓存”,因此归并排序的空间复杂度为O(n);
递归:
递归的结束返回永远是最小子问题的解
递归调用就是普通函数调用,并无本质区别(每次调用有自己独立的栈空间)
用递归思路解决问题,一定要实可提醒自己原问题是什么,那么子问题就是什么!!