关于hash_table讲解不错的网址:https://www.cnblogs.com/idreamo/p/7990860.html
在<<STL源码剖析>>中,vector封装了数组的数据结构,list封装了链表的结构,而set和map封装了二叉树的数据结构。那么hashtable,具有怎么的作用呢,其本质又是什么呢?本质就是查找表,既然是查找表,其查找效率自然就是O(1).下面来看看hashtable究竟是什么?


上述对hashtable的描述,表明了这样的观点:hashtable的引入其实就是相当于是一种字典,也就是查找表。当然了在内存空间十分富足的条件下,我们可以有多少元素,分配多大的内存空间,构成一一映射。但是这是不现实的,通常我们 分配的内存空间大小远小于元素个数。

可见我们可以通过hash函数来产生映射关系,这种函数叫做散列函数,那么这种条件下,必然会带来,有些元素被映射到了相同的内存空间,而这个就叫做哈希冲突或者哈希碰撞,如下图表述:

也就是说,只要分配空间小于元素数量,碰撞问题是无法避免的,但是我们可以采用有效策略来提高检索效率,使得存在很多元素时候,这些元素在内存中的分布尽量均衡(减少有些内存单元无元素,有些内存单元元素很多这种不平衡情况)。在STL中,采用的策略是开拉链法(想想拉链的形状,这是很想形象的表述),来领教一下开拉链法

我们来看一下STL中的开拉链法究竟是如何实现的:
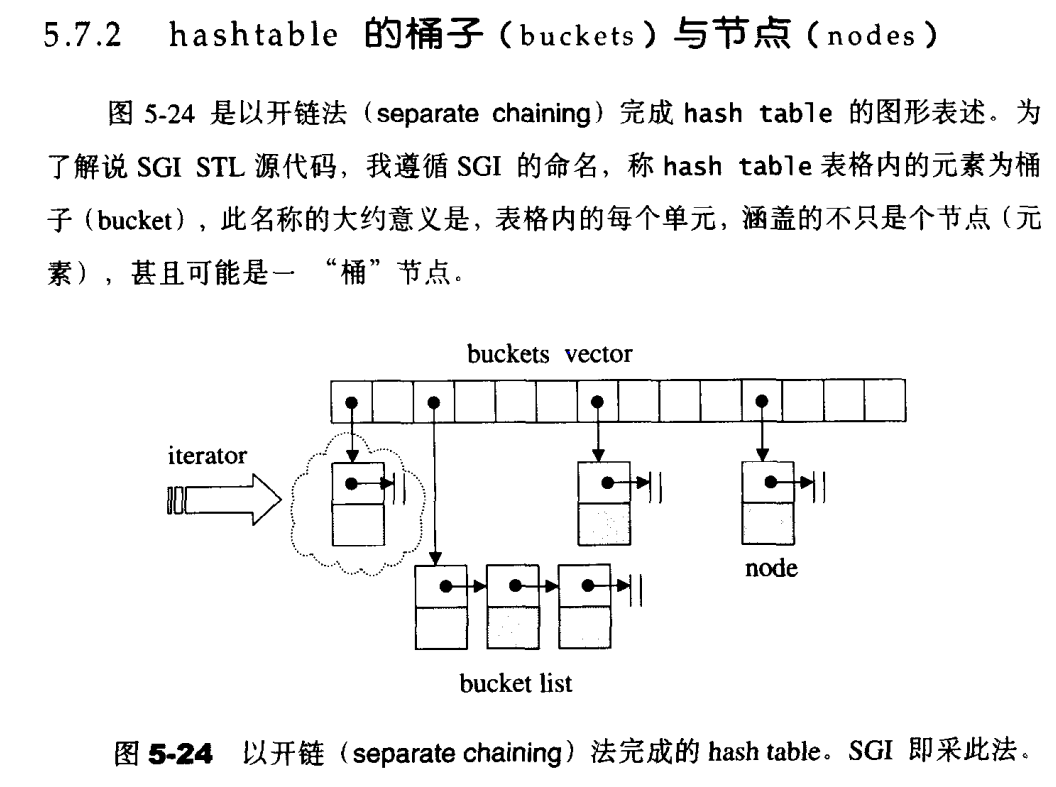
也就是,用一个vector存放所有bucket,vector的每一个内存单元存放一个bucket,而这个bucket究竟是什么呢?其本质就是其下面维护的链表的头节点!!!而每个bucket下面的链表,则存放了元素和指向下一个节点的地址。也就是每一个bucket维护一个list。这就是上面书中所说:表格内的每个单元,涵盖的不只是个节点,甚至可能是一桶节点。
我们可以从下图看到更加细节的东西:

这充分说明了:每个节点存放了我们要存放的元素以及指向下一个节点的指针。而bucket是存在于vector中的,而vector具有自动扩容的能力,说明hashtable在某种条件下是会扩容的。
我们来看一下hashtable迭代器具有怎样的性质:

可见,其迭代器指向的是节点,因此我们可以通过hashtable迭代器获得我们想要查找的元素。值得一提的是如果迭代器当前处于list的结尾,那么hash_table_node->指向了下一个桶子。再看看hashtable类型:

其实从上文我们也能看出hashtable迭代器是一个前向迭代器!!!
再来看看hashtable模板参数有哪些:

这里我还没全部理解所有的参数,先跳过这个地方的讲述。我们来看看hashtable的扩容规则:

我们可以看到:vecotor的大小是质数,当需要扩容时候,寻找最接近当前数,并大于当前数,为当前数约两倍的质数
关于插入行为,在hashtable中,有两种插入行为:insert_unique()(显然不能插入重复元素),insert_equal()(可以插入重复元素)。而不管是哪种插入行为,都要先判断插入元素之后,是否要扩容,也就是resize,如果需要,先resize,再insert。
那么什么时候执行resize呢???下图给出了答案:

可见,当所有list节点的总数的大于vector容量时,就要扩容了!
而hashtable具有获取元素所在bucket的功能:

关于hashtable所有的知识这里基本都介绍完毕了,下面我们来看一个例子:




我们先来看看结果:
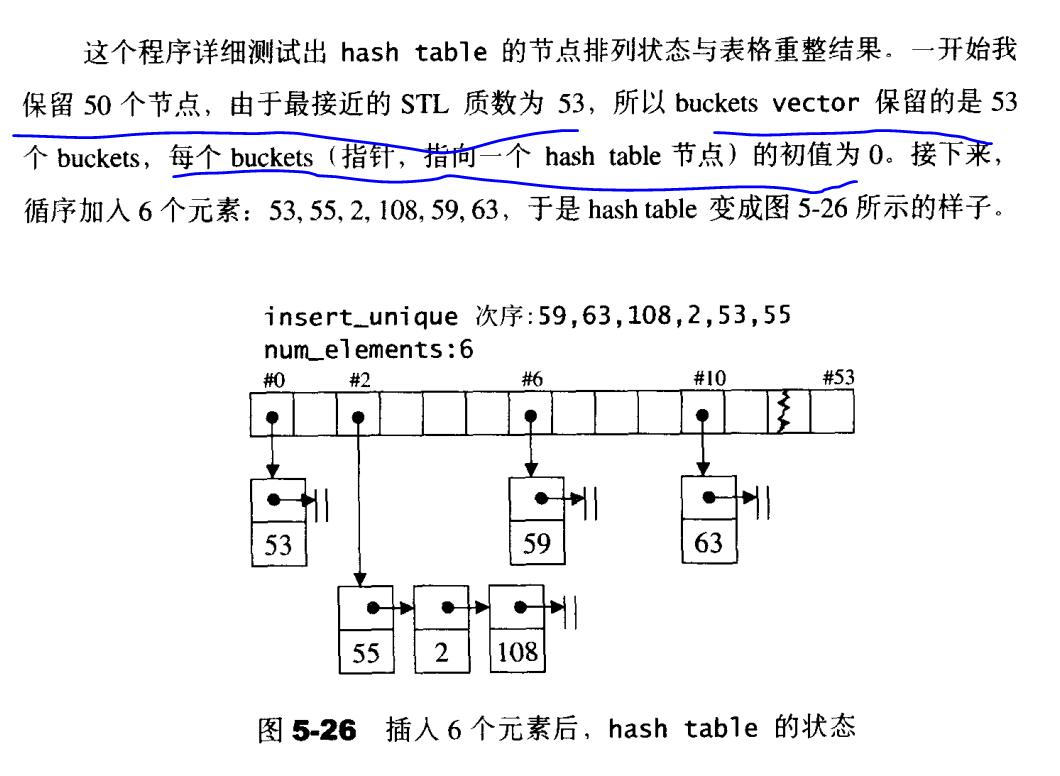
可见,当我们定义bucket集合vector大小的时候,会找与当前数字最接近的质数,同时每个bucket被初始化为空,同时我们也应该注意到:hashtable并不具备和set和map这样的自动排序功能!它只是按照散列函数的功能,将对应元素放到了对应的位置!
关于扩容
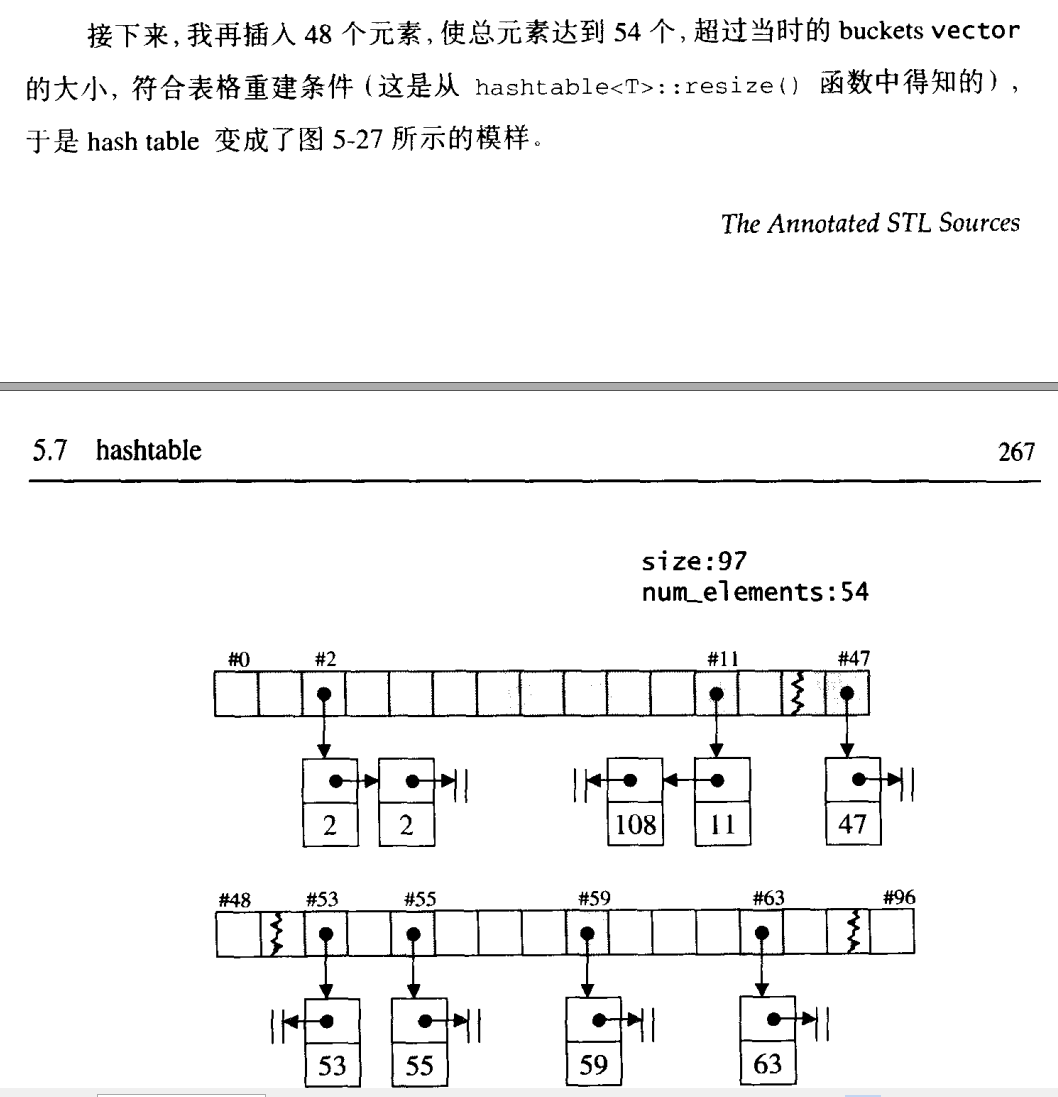
可见,当元素总数量超过vector的size的时候,那么就会产生扩容。
至此介绍完毕!