一、pyspider简介
1、通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
2、通过web化的脚本编写、调试环境。web展现调度状态
3、抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展


1、各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。 scheduler 负责整体的调度控制
2、任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
3、每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
二、安装
1、首先确保你已经安装了pip,若没有安装,请参照: http://pip-cn.readthedocs.io/en/latest/installing.html
2、PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它全面支持web而不需浏览器支持,其快速、原生支持各种Web标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可以用于页面自动化、网络监测、网页截屏以及无界面测试等。请参照:http://phantomjs.org/download.html
3、直接利用 pip 安装即可
pip install pyspider 或者下载:https://github.com/binux/pyspider/releases 后解压利用 python setup.py install进行安装
4、官方文档:http://docs.pyspider.org/en/latest/
三、测试
安装完成后在命令行输入:pyspider all

然后浏览器访问 http://localhost:5000
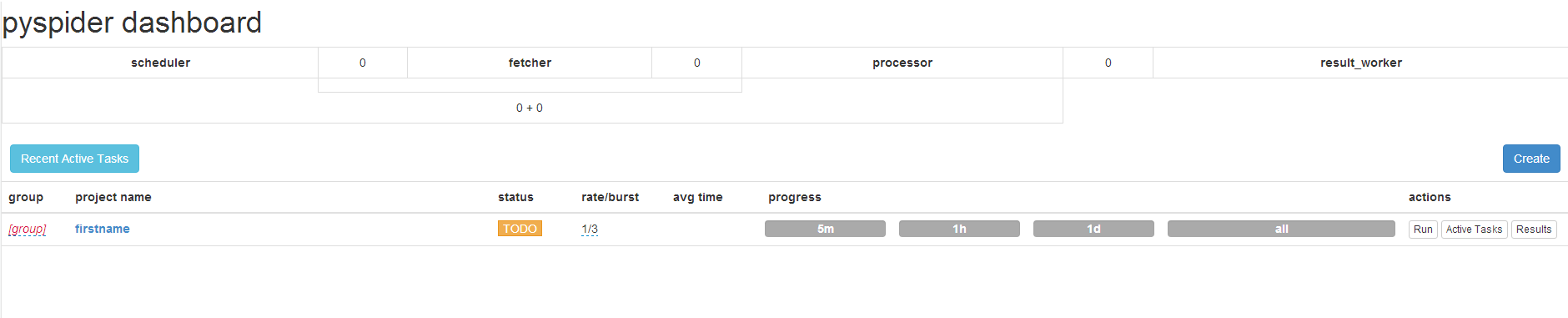
观察一下效果,如果可以正常出现 PySpider 的页面,那证明一切OK
在此附图一张,这是我写了几个爬虫之后的界面。