1、glob模块
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。跟使用windows下的文件搜索差不多。查找文件只用到三个匹配符:”*”, “?”, “[]”。”*”匹配0个或多个字符;”?”匹配单个字符;
”[]”匹配指定范围内的字符,如:[0-9]匹配数字。
glob.glob
返回所有匹配的文件路径列表。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。下面是使用glob.glob的例子:
例子1:

结果:
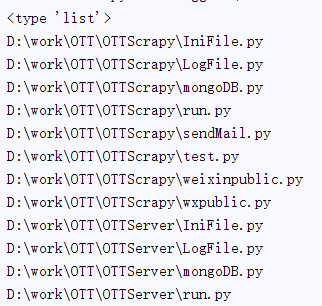
例子2

结果:
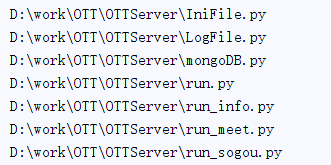
如果你想得到每个文件的绝对路径,你可以在返回值上调用realpath()函数:

结果:
glob.glob
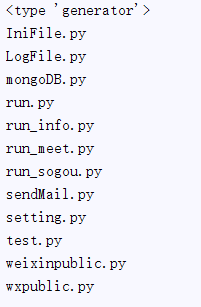
获取一个可编历对象,使用它可以逐个获取匹配的文件路径名。与glob.glob()的区别是:glob.glob同时获取所有的匹配路径,而glob.iglob一次只获取一个匹配路径。
这有点类似于.NET中操作数据库用到的DataSet与DataReader。下面是一个简单的例子:

结果:
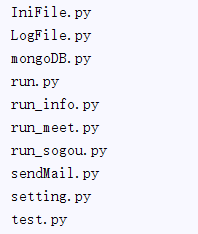
2、生成唯一ID
在有些情况下你需要生成一个唯一的字符串。我看到很多人使用md5()函数来达到此目的,但它确实不是以此为目的。其实有一个名为uuid()的Python函数是用于这个目的的。


3、序列化json


4、压缩字符
当谈起压缩时我们通常想到文件,比如ZIP结构。在Python中可以压缩长字符,不涉及任何档案文件。
import zlib string = """ Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nunc ut elit id mi ultricies adipiscing. Nulla facilisi. Praesent pulvinar, sapien vel feugiat vestibulum, nulla dui pretium orci, non ultricies elit lacus quis ante. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aliquam pretium ullamcorper urna quis iaculis. Etiam ac massa sed turpis tempor luctus. Curabitur sed nibh eu elit mollis congue. Praesent ipsum diam, consectetur vitae ornare a, aliquam a nunc. In id magna pellentesque tellus posuere adipiscing. Sed non mi metus, at lacinia augue. Sed magna nisi, ornare in mollis in, mollis sed nunc. Etiam at justo in leo congue mollis. Nullam in neque eget metus hendrerit scelerisque eu non enim. Ut malesuada lacus eu nulla bibendum id euismod urna sodales. """ print "Original Size: {0}".format(len(string)) compressed = zlib.compress(string) print "Compressed Size: {0}".format(len(compressed)) decompressed = zlib.decompress(compressed) print "Decompressed Size: {0}".format(len(decompressed))
5、OrderedDict
python中的字典是无序的,因为它是按照hash来存储的,但是python中有个模块collections(英文,收集、集合),里面自带了一个子类OrderedDict,实现了对字典对象中元素的排序。请看下面的实例:
普通字典,顺序不同,内容相同却是一个字典
dict1= {'z':3 ,'y':2, 'x':1}
dict2= {'z':3 , 'x':1,'y':2}
print dict1 == dict2
print dict1
print dict2
输出:
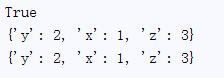
dict1 = OrderedDict() dict1['z'] = 3 dict1['y'] = 2 dict1['x'] = 1 dict2 = OrderedDict() dict2['z'] = 3 dict2['x'] = 1 dict2['y'] = 2 print dict1 == dict2 print dict1 print dict2
输出:
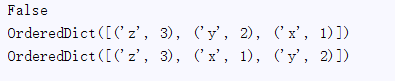
再看几个例子
dict1 = {'banana': 3, 'apple':4, 'pear': 1, 'orange': 2}
kd = OrderedDict(sorted(dict1.items(), key=lambda t: t[0]))
print kd
#按照value排序
vd = OrderedDict(sorted(dict1.items(),key=lambda t:t[1]))
print vd
#输出
# OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])
# OrderedDict([('pear', 1), ('orange', 2), ('banana', 3), ('apple', 4)])
6、sorted函数
python内置的排序函数sorted可以对list或者iterator进行排序,官网文档见:http://docs.python.org/2/library/functions.html?highlight=sorted#sorted,该函数原型为:
sorted(iterable[, cmp[, key[, reverse]]])
参数解释:
1、iterable指定要排序的list或者iterable,不用多说;
2、cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数,如:
students为类对象的list,没个成员有三个域,用sorted进行比较时可以自己定cmp函数,例如这里要通过比较第三个数据成员来排序,代码可以这样写:
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda student : student[2])
3、key为函数,指定取待排序元素的哪一项进行排序,函数用上面的例子来说明,代码如下:
sorted(students, key=lambda student : student[2])
key指定的lambda函数功能是去元素student的第三个域(即:student[2]),因此sorted排序时,会以students所有元素的第三个域来进行排序。
有了上面的operator.itemgetter函数,也可以用该函数来实现,例如要通过student的第三个域排序,可以这么写:
sorted(students, key=operator.itemgetter(2))
sorted函数也可以进行多级排序,例如要根据第二个域和第三个域进行排序,可以这么写:
sorted(students, key=operator.itemgetter(1,2)) 即先跟句第二个域排序,再根据第三个域排序。
7、分片
list1 = "0123456789" print("打印第0个元素:" ,list1[0]) print("负数表示倒数第N个元素,-1表示倒数第一个元素:" ,list1[-1]) print("分片操作,list1[start:end], start会包含在结果中而end却不会:" ,list1[1:5]) print("冒号后不写表示从start到末尾:" ,list1[5:]) print("表示从倒数第二个元素一直到末尾:" ,list1[-2:]) print("表示从倒数第六个元素到倒数第二个元素,但不包含倒数第二个元素:" ,list1[-6:-2]) print("start不写表示从开头开始到end, 但不包含end:" ,list1[:4]) print("start和end都不写表示整个列表:" ,list1[:]) print("支持步长,步长为正数表示从start到end每隔N个数打印一个:" ,list1[::2]) print("步长为负数表示从end到start每隔N个数打印一个:" ,list1[::-2]) print("若end比start小,则步长必须为负数否则会出错:" ,list1[-1:-6:-1]) print("两个序列相加会合并:" ,[1, 2, 3] + [4, 5, 6]) print("序列乘法相当于3个序列相加:" , [1, 2, 3] * 3)
修改删除和分片修改删除元素
list2 = [0,1,2,3,4,5,6,7,8,9] list2[1] = 'b' print(list2) #[0'b'23456789] del list2[1] print(list2) #[023456789] del list2[5:] print(list2) list2[5:] = [6,7,8,9] print(list2)