一、介绍
本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息
二、网站信息
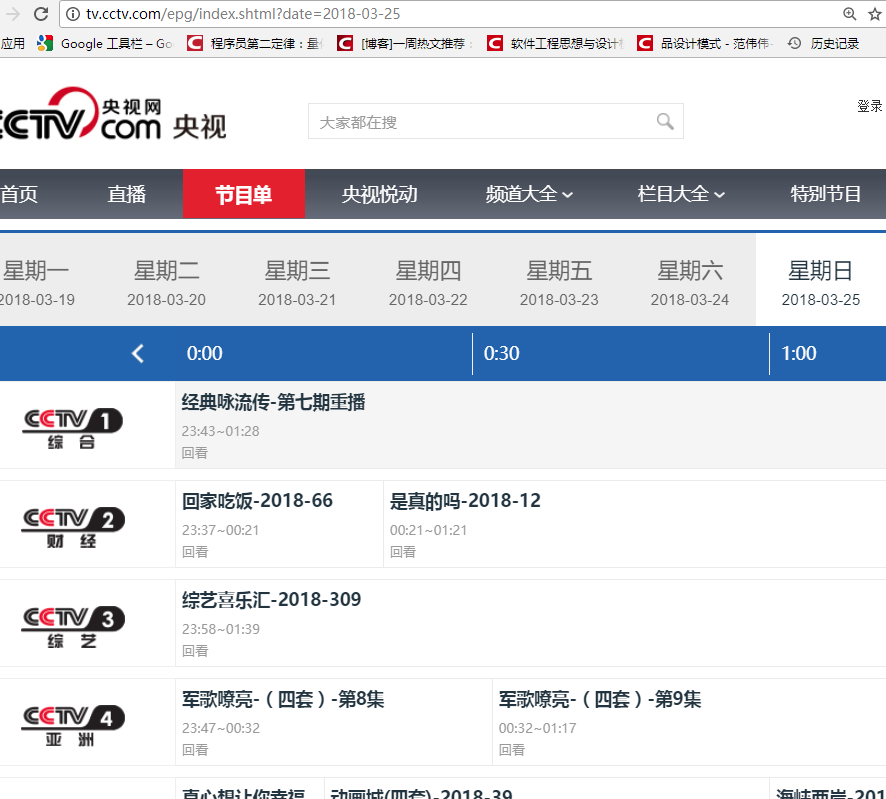
三、数据抓取
针对上面的网站信息,来进行抓取
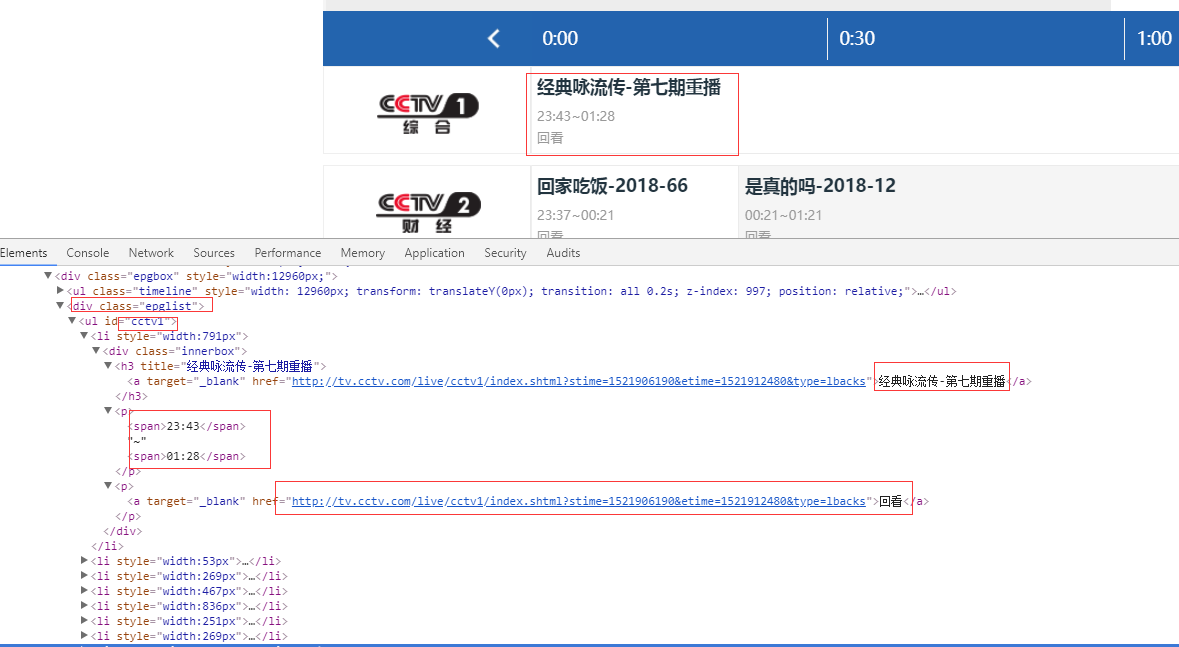
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="epglist"]').find('ul')
2、节目名称,链接,时间
title = subEle('div[class="innerbox"]').find('h3').text().encode('utf8')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8')
四,实现代码
# coding=utf-8 import os import re from selenium import webdriver from datetime import datetime,timedelta import selenium.webdriver.support.ui as ui import time from pyquery import PyQuery as pq class cctvDriver: def __init__(self,startDate,endDate): #通过配置文件获取IEDriverServer.exe路径 self.urls = self.getUrlsFromStartEndDate(startDate,endDate) IEDriverServer ='C:Program FilesInternet ExplorerIEDriverServer.exe' self.driver = webdriver.Ie(IEDriverServer) self.driver.maximize_window() self.fileName = time.strftime('%Y-%m-%d') def compareDate(self, startDate, endDate): start_Date = time.strptime(startDate, "%Y-%m-%d") end_Date = time.strptime(endDate, "%Y-%m-%d") totalSeconds = (end_Date - start_Date).total_seconds() if totalSeconds >= 0: print endDate return True else: print startDate return False def compareTime(self, startTime, endTime): st = int(startTime.replace(':',"")) et = int(endTime.replace(':',"")) if st>et: return True else: return False def getUrlsFromStartEndDate(self,startDate,endDate): urls = [] start_Date = datetime.strptime(startDate, "%Y-%m-%d") end_date = datetime.strptime(endDate, "%Y-%m-%d") ts = end_date-start_Date days = ts.days + 1 index = 0 for d in xrange(0,days): date = start_Date + timedelta(days=index) urls.append('http://tv.cctv.com/epg/index.shtml?date='+date.strftime("%Y-%m-%d")) index += 1 return urls def WriteLog(self, message,date): fileName = os.path.join(os.getcwd(), 'cctvInfo/'+date + '.txt') with open(fileName, 'a') as f: f.write(message) def CatchData(self): className = "//div[@class='epglist']/ul" for url in self.urls: date = url.split('=')[1] start_Date = datetime.strptime(date, "%Y-%m-%d") + timedelta(days=-1) predate = start_Date.strftime("%Y-%m-%d") self.driver.get(url) time.sleep(5) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) Elements = doc('div[class="epglist"]').find('ul') message = '' recount = 0 for element in Elements.items(): channel = element.attr('id') subElements = element.find("li") for subEle in subElements.items(): strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8').strip().replace( '回看', '').replace('直播','') if strTime: title = subEle('div[class="innerbox"]').find('h3').text().encode( 'utf8').strip().replace( ',', ',') link = subEle('div[class="innerbox"]').find('p').find('a').attr('href') if self.compareTime(strTime.split('~')[0],strTime.split('~')[1]): starttime = predate + " " + strTime.split('~')[0] else: starttime = date + " " + strTime.split('~')[0] endtime = date + " " + strTime.split('~')[1] mess = ' {0},{1},{2},{3},{4}'.format(channel, title, starttime, endtime, link) # print mess message += mess recount+=1 if len(message)>10: self.WriteLog(message.strip(),date) print recount self.driver.close() self.driver.quit() # #测试抓取微博数据 obj = cctvDriver('2018-01-01','2018-03-01') obj.CatchData()