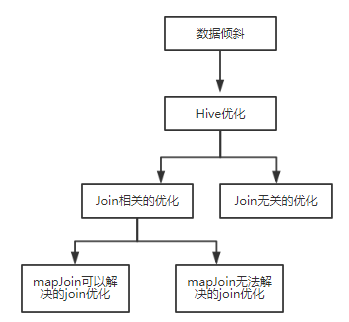
Hive SQL的各种优化方法基本 都和数据倾斜密切相关。
Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的优化又分为mapjoin可以解决的join优化和mapjoin无法解决的join优化。
1、数据倾斜
倾斜来自于统计学里的偏态分布。所谓偏态分布,即统计数据峰值与平均值不相等的频率分布,根据峰值小于或大于平均值可分为正偏函数和负偏函数,其偏离的程度可用偏态系数刻画。
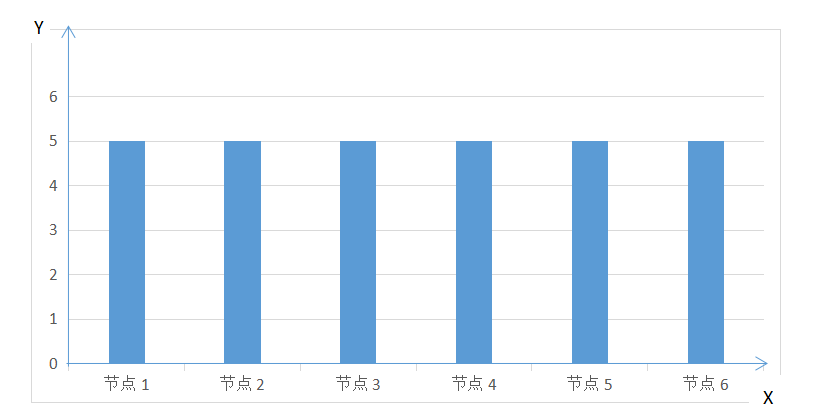
对应分布式数据处理来说,希望数据平均分布到每个处理节点。如果以每个处理节点为X轴,每个节点处理的数据为Y轴,我希望的柱状图如下:
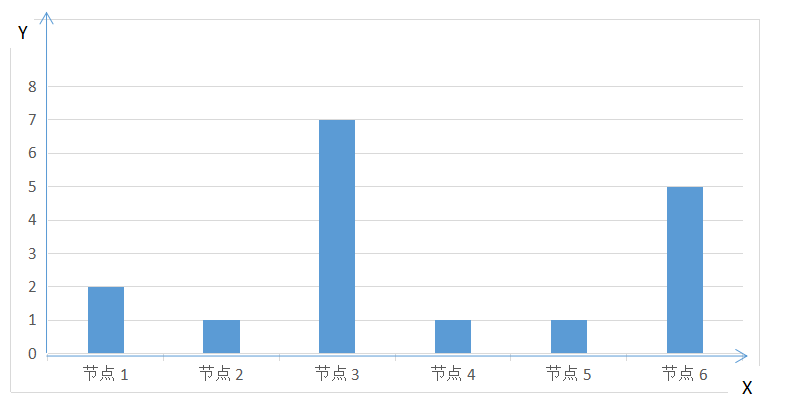
但是实际上由于业务数据本身的问题或者分布算法的问题,每个节点分配到的数据量很可能是下面的样式:
更极端情况出现下面的样式:
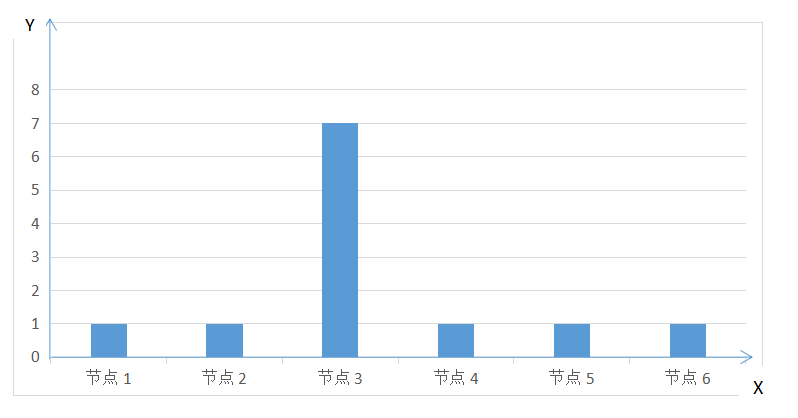
也就是说,只有待分到最多数据的节点处理完数据,整个数据处理任务才算完成,此时分布式的意义大大折扣了。实际上,即使每个节点分配到的数据量大致相同,数据仍然可能倾斜,
比如考虑统计词频的极端问题,如果某个节点分配的词都是一个词,那么显然此节点需要的耗时将很长。
Hive的优化正是采用各种措施和方法对上述场景的倾斜问题进行优化和处理。
2、Hive优化
在实际的Hive SQL开发的过程中,Hive SQL 性能的问题上实际上只有一小部分和数据倾斜有关,很多时候,Hive SQL运行慢是由于开发人员对于使用的数据了解不够以及一些不良的习惯引起的。
开发人员需要确定以下几点:
1、 需要计算的指标真的需要从数据仓库公共明细层来自行汇总吗? 是不是数据公共层团队开发公共汇总层已经可以满足自己的需求?对应大众的、KPI相关的指标等通常设计良好的数据仓库公共层
肯定已经包含了,直接使用即可。
2、真的需要扫描那么多分区吗,比如对于销售事务明细表来说,扫描一年的分区和扫描一周的分区所带来的计算、IO开销完全是两个数量级,所耗费时间肯定是不同的,所以开发人员要仔细考虑因为需求,
尽量不浪费计算和存储资源。
3、尽量不要使用select * from your_table这样的方式,用到哪些列就指定哪些列,另外WHERE条件中尽量添加过滤条件,以去掉无关的行,从而减少整个MapReduce任务宠需要处理、分发的数据量。
4、输入文件不要是大量的小文件,Hive默认的Input Split是128MB(可配置),小文件可先合并成大文件。
3、join无关的优化
Hive SQL性能问题基本上大部分都是和JOIN相关,对于和join无关的问题主要有group by相关的倾斜和count distinct相关的优化
3.1、group by引起的倾斜优化
group by引起的倾斜主要是输入数据行按照group by列分别布均匀引起的,比如,假设按照供应商对销售明细事实表来统计订单数,那么部分大供应商的订单量显然非常大,而多数供应商的订单量就一般,
由于group by 的时候是按照供应商的ID分发到每个Reduce Task,那么此时分配到大供应商的Reduce task就分配了更多的订单,从而导致数据倾斜。
对应group by引起的数据倾斜,优化措施非常简单,只需要设置下面参数即可:
set hive.map.aggr = true
set hive.groupby.skewindata = true
此时,Hive在数据倾斜的时候回进行负载均衡。
3.2、count distinct优化
在Hive开发过程中,应该小心使用count distinct,因为很容易引起性能问题,比如下面的SQL:
select count(distinct user) from some_table;
由于必须去重,因此Hive将会把Map阶段的输出全部分布到一个Reduce Task上,此时很容易引起性能问题,对于这种情况,可以通过先group by再count的方式优化,优化后的SQL如下:
select count(*)
from (select user from some_table group by user) temp;
其原理为:利用group by去重,再统计group by 的行数目。
参考资料:《离线和实时大数据开发实战》