Storm是一个分布式、高容错、高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义。Hadoop提供了Map和Reduce原语。同样,Storm也对数据的实时处理提供了简单的
spout和bolt原语。Storm集群表面上看和Hadoop集群非常像,但Hadoop上面运行的是MapReduce的Job,而Storm上面运行的是topology(拓扑),它们非常不一样,比如一个MapReduce的Job最终会结束,
而一个Storm topology永远运行(除非显式杀掉它)
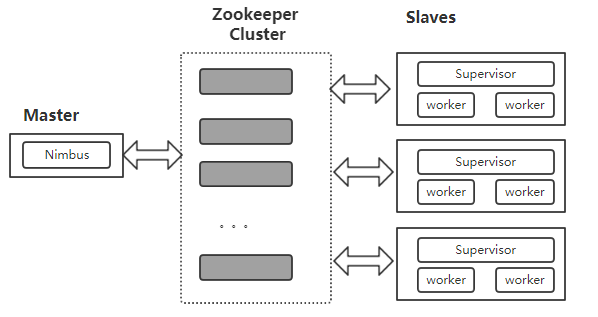
1、Storm集群的整体架构
2、Storm关键概念
topology
一个事实应用程序在Storm中称为一个拓扑(topology), Storm中的拓扑类似于Hadoop的MapReduce任务,不同之处是,一个MapReduce任务总会运行完成,而拓扑如果不显式结束则一直运行。
一个Storm拓扑一般由一个或者多个spout(负责发送消息)以及一个或者多个bol(负责处理消息)做组成。
tuple
Storm处理的基本消息单元为tuple(元组),Tuple是一个明明值列表,元组中的字段可以是任何类型的对象。Storm用元组作为其数据模型,元组支持所有基本类型、字符串和字节数组作为字段值,
只要实现类型的序列化接口,就可以使用该类型的对象。元组是一个值的列表。
流
流(Stream)在Storm中是一个核心抽象概念。一个流是由无数个元组序列构成,这些元组并行、分布式的被创建和执行。在stream的许多元组中,Streams被定义为以Fields区域命名的一种模式。
默认情况下,元组支持:Integers,longs,shorts,bytes,strings,doubles,floats,booleans,and byte arrays.
每一个Stream在声明的时候都会赋予一个id,单个Stream--spouts和bolts,可以使用OutputFieldsDeclarer的convenience方法声明一个stream.而不用指定一个id,但是这种方法会给一个模式的id: default。
spout
spout(喷口)是topology的流的来源,是一个topology中产生源数据流的组件。通常情况下,spout会从外表数据源(例如kafak队列或Tiwitter API)中读取数据,然后转为为topology 内部的源数据。
spout可以是可靠是,也可以是不可靠的。如果Storm处理元组失败,可靠的spout能够重新发射,不可靠的spout无法重新发射已经发出的元组。spout是一个主动的角色,其接口中有一个nextTuple()函数,
Storm框架会不停的调用此函数,用户只要在其中生成源数据即可。
spout可以发出超过一个的流。为此,使用OutputFieldsDeclarer类的declareStream方法来声明多个流,使用SpoutOutputCollector类的emit执行方法来进行流的提交。
spout的主要方法是nextTuple(),nextTuple()会发出一个新的tuple到拓扑,如果没有新的元组发出,则简单地返回。nextTuple()方法不阻止任何的spout的实现,因为stream在同一个线程调用所有
spout方法。
spout的其它主要方法是ack()和fail(). 当Storm监测到一个tuple从spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。ack()和fail()仅被可靠的spout调用。IRichSpout是 spout
必须实现的接口。
bolt
拓扑中所有处理逻辑都在bolt(螺栓)中完成,bolt是流的处理节点,从一个拓扑接收数据后执行进行出来的 组件。bolt可以完成过滤(filter)、业务处理。连接运算(join)、连接与访问数据库的等任何操作。
bolt是一个被动的角色,其接口中只有一个execute()方法,此方法在接收到消息后会被调用,用户可以在其中执行自己希望的操作。
bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个bolt。此外,bolt也可以发出超过一个的流。
bolt的主要方法是execute()方法,该方法将一个元组作为输入。bolt使用 OutputCollector对象发射新tuple。bolt必须为他们处理的每个元组调用OutputCollector类的ack()方法,以便Storm只是什么
时候元组会完成。
流分组
定义一个topology的步骤之一是定义每个bolt接收什么样的流作为输入。流分组(stream grouping)用来定义一个Strream应该如何分配数据给bolts上的多个任务。
在Storm中,有8种内置流分组方式,通过实现CustomStreamGrouping接口,用户可以实现自己的流分组方式。
shuffle grouping(随机分组):这种方式会随机分发tuple给bolt的各个任务,每个bolt实例接收相同数量的tuple。
fields grouping(字段分组):根据指定字段的值进行分组,例如,一个数据流根据“word”字段进行分组,所有具有相同"word"字段值的(tuple)会路由到同一个(bolt)的task中。
all grouping(全复制分组):将所有的tuple复制后分发给所有bolt task, 每个订阅数据流的task都会接收到所有的tuple的一份备份。
globle grouping(全局分组):这种分组方式将所有的tuples路由到唯一的任务上,Storm按照最小的taskID来接收数据的task,注意,当使用全局分组方式时,设置bolt的task并发度是没有意义的(spout并发有意义),
因为所有的tuple都转发到一个task上了,此外,因为所有的tuple都转发到一个JVM实例上,可能会引起Storm集群中某个JVM或服务器出现性能瓶颈或崩溃。
none grouping(不分组):在功能上和随机分组相同,是为将来预留的。
direct grouping(指向性分组):数据源会调用emitDirect()方法来判断一个tuple应该由哪个Storm组件来接收。
local or shuffle grouping(本地或随机分组):和随机分组类似,但是会将tuple分发给同一个worker内的bolt task(如果workder内有接收数据的bolt task),其它情况下,则采用随机分组的方式。本地或随机分组取决于
topology的并发度,可以减少网络传输,从而提高topology性能。
partial key grouping:与按字段分组类似,根据指定字段的一部分进行分组分发,能够很好的实现负载均衡,将元组发送给下游的bolt对应的任务,特别是存在数据倾斜的情况下,使用partial key grouping能够很好的
提高资源利用率。
3、Storm并发
Storm集群中真正运行topology的主要有三个实体:worker(工作进程),executor(线程)和task(任务)。
参考资料:《离线和实时大数据开发实战》