其实这个坑呢,说实话是非常的有意思,因为当时这个坑弄得我甚至是以为编译器坏了。
昨天我在写关于豆瓣的爬虫的时候,有这样一个需求:
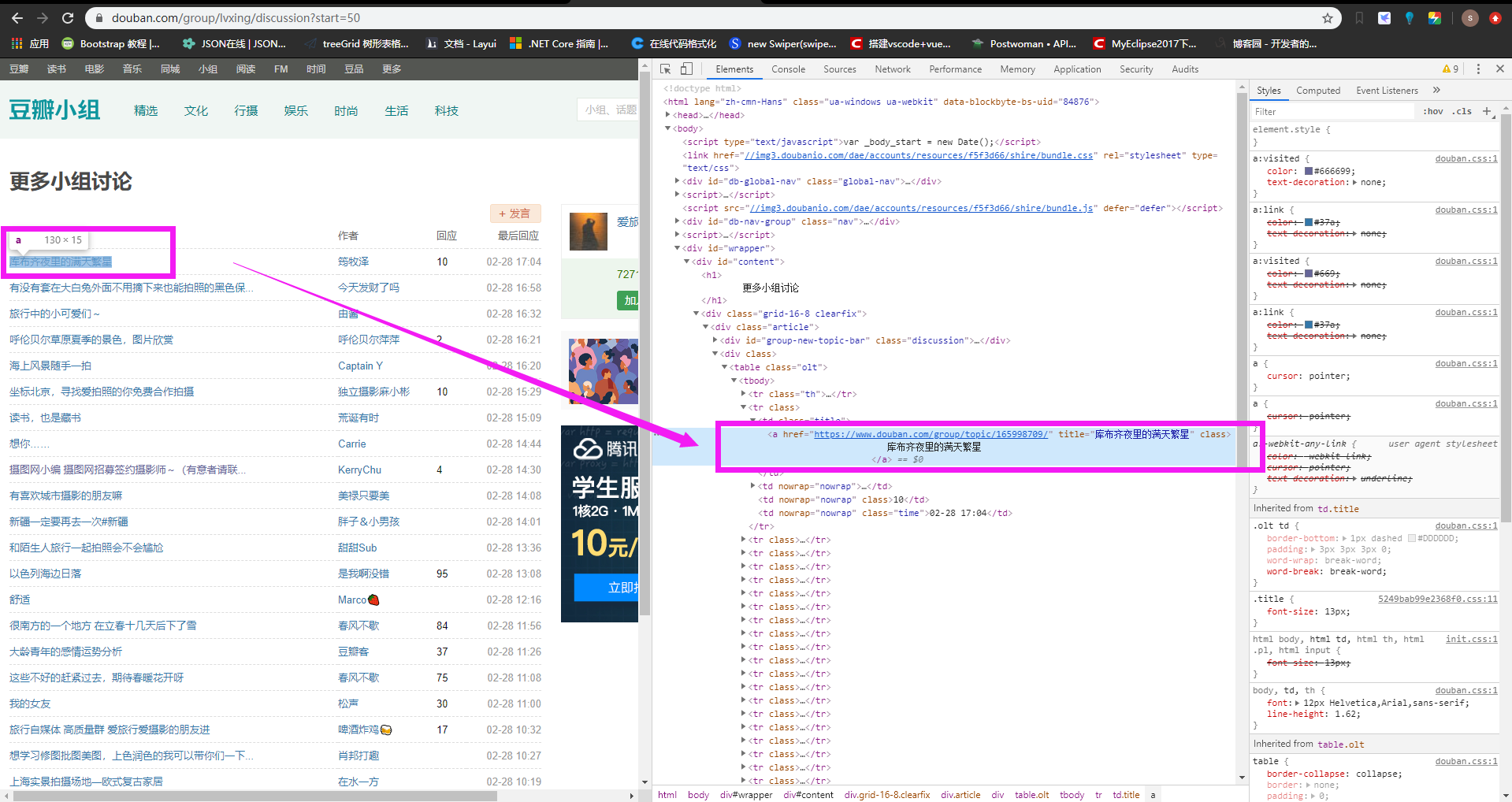
我想抓这个a标签,拿他的链接地址。这个时候在浏览器里右键该标签,复制其xpath结果如下:
//*[@id="content"]/div/div[1]/div[2]/table/tbody/tr[2]/td[1]/a
然后在代码中,则按照这个xpath路径去找,发现根本就没用,什么都找不到。
然后后面在调试的时候,我故意在即时窗口里,这样子去试验这条xpath路径:
我先检测 //*[@id="content"] 这样能不能找到内容,然后发现可以;
然后检测 //*[@id="content"]/div 发现也可以;
一直到 //*[@id="content"]/div/div[1]/div[2]/table/tbody 这个的时候,发现返回 null ,找不到?
最后我尝试把 tbody 去掉,直接用 //*[@id="content"]/div/div[1]/div[2]/table/tr[2]/td[1]/a (把tbody删了)
发现终于得到了我想要的那个标签节点。
总结
其实这个坑就是说,xpath里面不能带 tbody ,碰到这个节点,直接跳过,进行到下一节点去