0. 说明
RDD 概述 && 创建 RDD 的方式 && RDD 编程 API(Transformation 和 Action Operations) && RDD 的依赖关系
1. RDD 概述
Spark 围绕弹性分布式数据集(RDD)的概念展开,RDD 是可以并行操作的容错的容错集合。
resilient distributed dataset,弹性分布式数据集。
不可变集合,可以进行并行操作的分区化数据集合。
该类包含了 RDD 常见操作,比如 map、filter、persist 等。
对于 key-value 的 RDD,会自动转换成(隐式转换)PairRDDFunction,该类提供了所有的 ByKey 操作。
内部,每个 RDD 主要含有 5 个主要属性:
- 分区列表(轻量级数据集合,没有实际数据)
- 计算每个切片的计算函数
- 和其他RDD的依赖列表
- 针对 K-V 类型 RDD,还有一个分区类(可选)
- 计算每个切片的首选位置列表(可选)
2. 创建 RDD 的方式
创建 RDD 有两种方法
【方法一】
并行化 驱动程序中的现有集合。
例子如下

【方法二】
引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase 或提供 Hadoop InputFormat 的任何数据源。
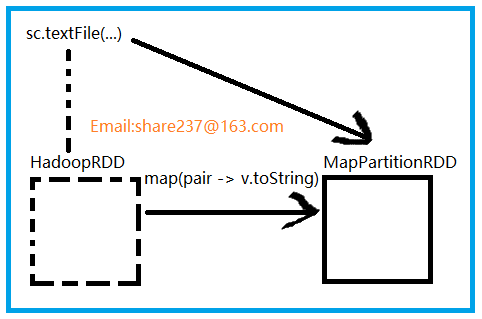
textFile() 方法最初创建的是 HadoopRDD,HadoopRDD 提供了读取 HDFS 文件核心功能。
sc.textFile()
产生了两个 RDD
HadoopRDD -> MapPartitionRDD
3. RDD 编程 API(Transformation 和 Action Operations)
【变换 Transformation】
返回值为新的 RDD
map
flatMap
filter()
reduceByKey()
【动作 Actions】
返回值为具体的值
collect()
save()
reduce()
count()
4. RDD 的依赖关系
【依赖】
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
【说明】
构造 RDD 时使用的是 One2OneDependency