0. 说明
编写 MapReduce 程序实现年度最高气温统计
1. 气温数据分析
气温数据样例如下:
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999 0029029070999991901010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9-00721+99999102001ADDGF104991999999999999999999 0029029070999991901010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00941+99999102001ADDGF108991999999999999999999 0029029070999991901010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9-00611+99999101831ADDGF108991999999999999999999 0029029070999991901010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00561+99999101761ADDGF108991999999999999999999
对气温数据进行分析可以得出以下的结论
1. 年份的索引为 15-19 ,以此作为 Key
2. 气温的索引为 87-92 ,以此作为 Value
【思路】
在 Map 阶段将原始数据映射成满足要求的 K-V 对,在 Reduce 阶段对相同 Key 的值进行比较,得到最大值
2. 代码编写
[2.1 MaxTempMapper.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper 类 */ public class MaxTempMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 获得年份 String year = line.substring(15, 19); // 获得温度 int temp = Integer.parseInt(line.substring(87, 92)); // 存在脏数据 9999,所以要将其过滤 if (temp != 9999) { // 输出年份与温度 context.write(new Text(year), new IntWritable(temp)); } } }
[2.2 MaxTempReducer.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer 类 */ public class MaxTempReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { Integer max = Integer.MIN_VALUE; // 得到最大值 for (IntWritable value : values) { max = Math.max(max, value.get()); } // 输出年份与最大温度 context.write(key, new DoubleWritable(max / 10.0)); } }
[2.3 MaxTempApp.java]
package hadoop.mr.maxtemp; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * max Temp APP */ public class MaxTempApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("max Temp"); // job 入口函数类 job.setJarByClass(MaxTempApp.class); // 设置 mapper 类 job.setMapperClass(MaxTempMapper.class); // 设置 reducer 类 job.setReducerClass(MaxTempReducer.class); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); // 新建输入输出路径 Path pin = new Path("E:/file/temp"); Path pout = new Path("E:/test/wc/out"); // 打包后自定义输入输出路径 // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); // 设置输入路径和输出路径 FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job job.waitForCompletion(true); } }
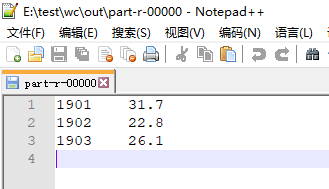
3. 测试
本地模式下运行代码的结果如下
4. 部署到集群上
【4.1 修改代码 MaxTempApp.java】


【4.2 打包程序】


【4.3 运行程序】
开启 Hadoop 集群,然后将 temp 数据文件上传到 HDFS 中,过程略
运行以下命令
hadoop jar myhadoop-1.0-SNAPSHOT.jar hadoop.mr.maxtemp.MaxTempApp /testdata/temp /testdata/out
【查看结果】
命令行下可以看到结果,Web UI 查看 http://s101:8088
