早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了。现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbase原理。
首先来点实在的东西,假如我们已经在服务器上部署好了Hbase应用,作为客户端或者说的具体点,本地开发环境如何编写程序和服务端的Hbase进行交互了?
下面我将展示这些,首先看工程的结构图,如下图所示:

接下来我们将hbase应用下lib文件夹里所有jar包都导入到工程lib目录下,还要把conf目录下的hbase-site.xml下载下来放置在conf目录里,这里我还将hbase项目里的log4j.properties文件放置到了项目的根目录下,这样在我们运行程序时候,控制台打印的日志也会更加的详细,下面是HBaseStudy.java的源代码:
package cn.com.hbasetest;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HBaseStudy {
public final static Logger logger = LoggerFactory.getLogger(HBaseStudy.class);
/* 构建Configuration,这里就是hbase-site.xml解析出来的对象,这里我还指定了本地读取文件的方式 */
static Configuration hbaseConf = HBaseConfiguration.create();
static {
hbaseConf.addResource("conf/hbase-site.xml");
}
/**
* 插入数据
* @throws IOException
*/
public void putTableData() throws IOException {
HTable tbl = new HTable(hbaseConf, "xsharptable001");
Put put = new Put(Bytes.toBytes("xrow01"));
put.add(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol01"), Bytes.toBytes("xvalue01"));
put.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"), Bytes.toBytes("xvalue02"));
put.addImmutable(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol03"), Bytes.toBytes("xvalue03"));
tbl.put(put);
}
/**
* 插入多行数据
* @throws IOException
*/
public void putTableDataRow() throws IOException {
HTable tbl = new HTable(hbaseConf, "xsharptable001");
Put put = new Put(Bytes.toBytes("xrow02"));
put.add(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol01"), Bytes.toBytes("xvalue012"));
put.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"), Bytes.toBytes("xvalue022"));
put.addImmutable(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"), Bytes.toBytes("xvalue032"));
tbl.put(put);
put = new Put(Bytes.toBytes("xrow03"));
put.add(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol01"), Bytes.toBytes("xvalue0213"));
put.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"), Bytes.toBytes("xvalue0123"));
put.addImmutable(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol03"), Bytes.toBytes("xvalue0223"));
tbl.put(put);
put = new Put(Bytes.toBytes("xrow04"));
put.add(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol01"), Bytes.toBytes("xvalue0334"));
put.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"), Bytes.toBytes("xvalue0224"));
put.addImmutable(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol03"), Bytes.toBytes("xvalue0334"));
put.addImmutable(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol04"), Bytes.toBytes("xvalue0334"));
tbl.put(put);
}
/**
* 查询hbase表里的数据
* @throws IOException
*/
public void getTableData() throws IOException {
HTable table = new HTable(hbaseConf, "xsharptable001");
Get get = new Get(Bytes.toBytes("xrow01"));
get.addFamily(Bytes.toBytes("xcolfam01"));
Result result = table.get(get);
byte[] bs = result.getValue(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"));
// ============查询结果:xvalue02
logger.info("============查询结果:" + Bytes.toString(bs));
}
/**
* 创建hbase的表
*
* @throws MasterNotRunningException
* @throws ZooKeeperConnectionException
* @throws IOException
*/
public void createTable() throws MasterNotRunningException, ZooKeeperConnectionException, IOException {
HBaseAdmin admin = new HBaseAdmin(hbaseConf);
if (admin.tableExists(Bytes.toBytes("xsharptable001"))) {
logger.info("===============:表已经存在!failure!");
} else {
TableName tableName = TableName.valueOf(Bytes.toBytes("xsharptable001"));
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
HColumnDescriptor hcol = new HColumnDescriptor(Bytes.toBytes("xcolfam01"));
tableDesc.addFamily(hcol);
admin.createTable(tableDesc);
logger.info("==============:表创建成功了!Success!");
}
}
/**
* 通过scan扫描数据,相当于关系数据的游标
*
* @throws IOException
*/
public void scanTableData() throws IOException {
HTable tbl = new HTable(hbaseConf, "xsharptable001");
Scan scanAll = new Scan();
ResultScanner scannerAll = tbl.getScanner(scanAll);
for (Result resAll : scannerAll) {
/*
* 打印出来的结果: 2016-06-14 15:46:10,723 INFO [main]
* hbasetest.HBaseStudy: ======ScanAll
* :keyvalues={xrow01/xcolfam01:xcol01/1465885252556/Put
* /vlen=8/seqid=0,
* xrow01/xcolfam01:xcol02/1465885252556/Put/vlen=8/seqid=0,
* xrow01/xcolfam01:xcol03/1465885252556/Put/vlen=8/seqid=0}
* 2016-06-14 15:46:10,723 INFO [main] hbasetest.HBaseStudy:
* ======ScanAll
* :keyvalues={xrow02/xcolfam01:xcol01/1465887392414/Put
* /vlen=9/seqid=0,
* xrow02/xcolfam01:xcol02/1465887392414/Put/vlen=9/seqid=0}
* 2016-06-14 15:46:10,723 INFO [main] hbasetest.HBaseStudy:
* ======ScanAll
* :keyvalues={xrow03/xcolfam01:xcol01/1465887392428/Put
* /vlen=10/seqid=0,
* xrow03/xcolfam01:xcol02/1465887392428/Put/vlen=10/seqid=0,
* xrow03/xcolfam01:xcol03/1465887392428/Put/vlen=10/seqid=0}
* 2016-06-14 15:46:10,723 INFO [main] hbasetest.HBaseStudy:
* ======ScanAll
* :keyvalues={xrow04/xcolfam01:xcol01/1465887392432/Put
* /vlen=10/seqid=0,
* xrow04/xcolfam01:xcol02/1465887392432/Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol03/1465887392432/Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol04/1465887392432/Put/vlen=10/seqid=0}
*/
logger.info("======ScanAll:" + resAll);
}
scannerAll.close();
Scan scanColFam = new Scan();
scanColFam.addFamily(Bytes.toBytes("xcolfam01"));
ResultScanner scannerColFam = tbl.getScanner(scanColFam);
for (Result resColFam : scannerColFam) {
/*
* 2016-06-14 15:50:54,690 INFO [main] hbasetest.HBaseStudy:
* ======scannerColFam
* :keyvalues={xrow01/xcolfam01:xcol01/1465885252556
* /Put/vlen=8/seqid=0,
* xrow01/xcolfam01:xcol02/1465885252556/Put/vlen=8/seqid=0,
* xrow01/xcolfam01:xcol03/1465885252556/Put/vlen=8/seqid=0}
* 2016-06-14 15:50:54,690 INFO [main] hbasetest.HBaseStudy:
* ======scannerColFam
* :keyvalues={xrow02/xcolfam01:xcol01/1465887392414
* /Put/vlen=9/seqid=0,
* xrow02/xcolfam01:xcol02/1465887392414/Put/vlen=9/seqid=0}
* 2016-06-14 15:50:54,690 INFO [main] hbasetest.HBaseStudy:
* ======scannerColFam
* :keyvalues={xrow03/xcolfam01:xcol01/1465887392428
* /Put/vlen=10/seqid=0,
* xrow03/xcolfam01:xcol02/1465887392428/Put/vlen=10/seqid=0,
* xrow03/xcolfam01:xcol03/1465887392428/Put/vlen=10/seqid=0}
* 2016-06-14 15:50:54,690 INFO [main] hbasetest.HBaseStudy:
* ======scannerColFam
* :keyvalues={xrow04/xcolfam01:xcol01/1465887392432
* /Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol02/1465887392432/Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol03/1465887392432/Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol04/1465887392432/Put/vlen=10/seqid=0}
*/
logger.info("======scannerColFam:" + resColFam);
}
scannerColFam.close();
Scan scanRow = new Scan();
scanRow.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol02"))
.addColumn(Bytes.toBytes("xcolfam01"), Bytes.toBytes("xcol04")).setStartRow(Bytes.toBytes("xrow03"))
.setStopRow(Bytes.toBytes("xrow05"));
ResultScanner scannerRow = tbl.getScanner(scanRow);
for (Result resRow : scannerRow) {
/*
* 2016-06-14 15:57:29,449 INFO [main] hbasetest.HBaseStudy:
* ======scannerRow
* :keyvalues={xrow03/xcolfam01:xcol02/1465887392428/
* Put/vlen=10/seqid=0} 2016-06-14 15:57:29,449 INFO [main]
* hbasetest.HBaseStudy:
* ======scannerRow:keyvalues={xrow04/xcolfam01
* :xcol02/1465887392432/Put/vlen=10/seqid=0,
* xrow04/xcolfam01:xcol04/1465887392432/Put/vlen=10/seqid=0}
*/
logger.info("======scannerRow:" + resRow);
}
scannerRow.close();
}
public static void main(String[] args) {
HBaseStudy hb = new HBaseStudy();
/*try {
hb.createTable();
hb.putTableData();
} catch (Exception e) {
e.printStackTrace();
}*/
try {
// hb.getTableData();
// hb.putTableDataRow();
hb.scanTableData();
} catch (Exception e) {
e.printStackTrace();
}
}
}
这段代码写得匆忙,示例并没有好好设计,不过代码我是测试过,完全可以正常运行,下面几站截图是我通过hbase shell查询测试结果,如下图所示:
图一:

这里我通过describe命令查看表的基本信息。
图二:

这里我使用scan命令进行全表扫描。
图三:
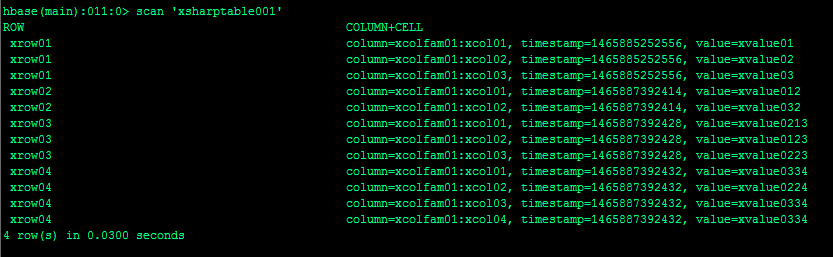
当我插入更多数据时候使用scan命令进行全表扫描。
本篇文章不会着重讲解hbase的javaAPI,其实本实例里也只是使用了少量的API,不过在我选择的API里我想体现的是hbase里表(table),行(rowkey),列族(family)和列(column)之间的关系。
创建表我们要先定义好表名,列族,插入数据我们首先是插入行,然后根据列族定义列接下来添加数据,这些都是按照hbase设计规范进行操作的,下面就是关键所在了:我们是如何查询数据的。
对于查询的Get操作,我们构造Get对象时候就是使用rowkey进行,scan可以进行全表扫描,也可以根据列族查询,还可以使用rowkey的范围限定scan扫描数据的范围,不管从什么角度进行查询,我们可以总结出hbase做查询时候都会跟rowkey和列族相关,hbase的javaAPI并没有再去提供更多查询手段,因此我们可以得出在提升hbase查询效率的因素里rowkey和列族必然承担了很重要的作用。
大数据时代的数据量是超大规模的,传统的关系数据库已经很难存储和管理这些数据了,为了存储海量数据,我们有了HDFS,它可以把成千上万台服务器上的硬盘聚集成一块超级大的硬盘,为了让这些数据产生价值,我们有了mapreduce,它可以计算这个超大硬盘的数据,面对这么大的数据量我们还有一个迫切的需求那就是如何快速检索出我们想要的数据,而这个功能就是由hbase来承担。
那么如此海量数据快速检索技术原理又是怎样的呢?我觉得原理很简单就是索引技术。Hbase通过rowkey来区别不同类型数据,通过列族把经常需要一起被查询出来的数据放在一起,例如我们如果要做一个电商平台的交易记录业务表设计,对于电商平台下的商户他其实只需要查询出自己的交易信息,而不会去关心其他商户的交易信息,那么我们就可以把商户号作为rowkey,每一个商户的交易的信息我们就放在一个列族里,商户号这样的信息就像数据在硬盘上的门牌号,我们一传入这个值做查询,hbase就能快速找到数据存储的位置,这就是hbase能快速检索到数据的原理。
上面讲到的原理只是业务抽象的角度来说,在hbase底层它就是根据上面说到的这些原理来设计的,hbase里面有region的概念,region是一个数据集合,那么什么样的数据会放置到某一个region里呢?hbase是根据rowkey来把同一类的数据放置在一个region里,rowkey下面就是列族,列族对应的底层存储就是hfile,hfile放置在rowkey对应的region下,所以当我们查询时候我们很容易通过业务规则找到我们设计好的rowkey,找到了rowkey就找到region,那么region下存储的hfile列族信息也就可以全部查询出来了。
Rowkey其实就是hbase的索引,也可以说是hbase官方给出的唯一索引,因此很多资料里说hbase只有一级索引,这个一级索引就指的就是rowkey,因此如何设计rowkey就是一门大学问了,时常我们一行数据不能满足我们复杂的查询要求,我们需要跨行就像scan那么扫描多行数据,而region里的行都是按照一定顺序排列的,这个顺序就是字典顺序,这个我在以前一篇文章里提到过,所以碰到这种情况,我们一般会通过md5将key散列,这样相邻的数据行会排列在一起,底层存储数据时候也会存储在同一个地方(相同region)或者是相互靠近的地方(相邻region),这样也就可以提升查询的效率。
Hbase内部有两张表一个是-ROOT-表和.META.表,客户端程序就是像我上面给出的示例程序首先访问zookeeper,通过zookeeper获取含有-ROOT-的region服务器名,通过-ROOT-的region服务器可以查询到.META.表里行键rowkey对应的region位置,而-ROOT-和.META.客户端访问后就会缓存起来。
其实hbase的表设计本身非常简单,对外接口也没有关系数据库那么丰富,我最近学习hbase,觉得hbase基本都没有关系数据库里那些计算函数,可见hbase只是提供一种能快速检索海量数据的一种计算模型而已。
本文就到此为止了,好记性不如烂笔头,写写文章是对自己学习的总结,也是留一个备忘和将来的遗忘做斗争了。