最近在看《mysql技术内幕》一些笔记记录在这里。
1. Innodb 关键特性
其实存储引擎优化思想就是想方设法地去解决cpu速度和磁盘速度不匹配的问题,以及怎么样防止数据库宕机导致的数据丢失。
那么为了解决cpu和磁盘速度不匹配的问题,数据库设置了一个缓冲池:当要修改数据时,想磁盘中的数据拷贝到内存的缓冲池中,然后修改缓冲池中的数据,最后再在某一时刻刷回磁盘。
为了防止刷回磁盘的过程中意外宕机的数据丢失,innodb中,采用使用日志的方式:Write Ahead Log策略。通过先写日志再写数据的方式:但事务提交时,先写重做日志,再修改页。然后再次开机恢复数据库时,可以通过重做日志来恢复以及提交的事务,继续完成上次的事务。但是还可能是数据库宕机时事务还未提交,这时候就需要回滚日志undo log来回滚事务到事务开始前的状态。
1.重做日志redo log
用于在实例故障恢复时,继续那些已经commit但数据尚未完全回写到磁盘的事务。
2.回滚日志undo log
用于在实例故障恢复时,借助undo log将尚未commit的事务,回滚到事务开始前的状态。
总结: Redo日志记录某数据块被修改后的值,可以用来恢复未写入data file的已成功事务更新的数据;Undo日志记录某数据被修改前的值,可以用来在事务失败时进行rollback
redo log 可以保证事务的原子性和持久性,undo log可以保证事务的一致性 (事务的隔离性是由锁来实现的)
redo和undo都可以视作一种恢复操作,redo恢复提交事务修改的页操作,记录的内容是物理日志,记录的是页的物理修改操作;而undo回滚行记录到某个特定的版本,记录的是逻辑日志,根据每行记录进行记录。
AUTOCOMMIT
MySQL 默认采用自动提交模式。也就是说,如果不显式使用START TRANSACTION语句来开始一个事务,那么每个查询都会被当做一个事务自动提交。
2.数据库索引
1)b+树 数据结构:高度平衡的多叉树,叶子节点保存所有数据。(注意b+树的非聚集索引的叶子节点并不是直接存放的给定键值的行,而是数据行所在的页,然后数据库通过把页读入内存,再在内存中查找)
2)b+树数据结构应用在数据库的索引实现中,具有高度的扇出性,一般b+树的高度都在2~4层,也就是说查找某一键值的行记录时最多只需要2~4次IO。
b+树索引可以分为聚集索引(就是主键索引,以主键作为key的索引)和辅助索引(非聚集索引)。
- 聚集索引的叶子节点保存的是数据,即行记录;
- Inoodb的主键索引的排序查找和范围查找非常快;
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。
一个例子:创建索引对查询性能的显著提升:
对于可以使用where查询的列point_num: 创建索引前,使用explain进行分析一条查询语句的执行计划:
mysql> explain select * from smart_geohashpickupplace where point_num = 2;
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | smart_geohashpickupplace | NULL | ALL | NULL | NULL | NULL | NULL | 26434 | 10.00 | Using where |
+----+-------------+--------------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
差不多是进行了全表扫描;
未使用索引时的type是all:
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
type
表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
创建索引:(因为该列上有重复值,所以就创建一个普通索引:)
mysql> create index point_key on smart_geohashpickupplace (point_num); Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0
再执行相同的语句看看变化:
mysql> explain select * from smart_geohashpickupplace where point_num = 2;
+----+-------------+--------------------------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | smart_geohashpickupplace | NULL | ref | point_key | point_key | 4 | const | 3754 | 100.00 | NULL |
+----+-------------+--------------------------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
type变为了ref
看到没有,查询这条语句扫描的行数仅仅只需要3754行了!
3.数据库锁
4.数据库事物
所谓事物就是符合ACID特性的一系列操作的组合。这些操作必须是原子性的,即一个事物要么成功,要么失败,不可能处于进行到一半的状态。
结合Spring事物管理。Transactional注解。
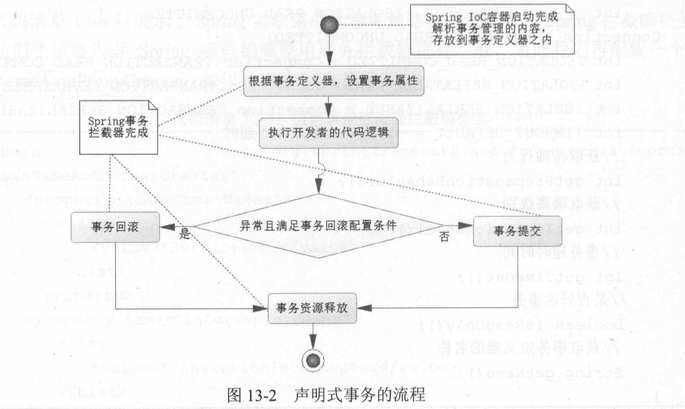
Transactional的事物配置项:隔离级别和传播行为
transactional的实现原理:AOP,而AOP的实现原理是动态代理,
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别
1. 事物的隔离级别:

选择哪种隔离级别,需要根据实际场景的并发量和性能考虑。从未提交读到可串行化读,系统性能直线下降。
mysql默认的隔离级别是可重复复读。