可变不可变
| 可变or不可变 | 数据类型 |
|---|---|
| 可变 | 列表,字典,集合 |
| 不可变 | 数字,字符串,元组 |
万能异常捕捉
try:
# 逻辑代码
1/0
except Exception as e:
print(e)
division by zero
拷贝、浅拷贝、深拷贝
深浅拷贝 拷贝 new = old ,old 任何数据类型的变化,new都会随着变化
浅拷贝 new = copy.copy(old),old中可变元素变化,new变;old中不可变元素变化,new不变;
深拷贝 new = copy.deepcopy(old),new不随old改变
PyCharm快捷键
ctrl + c 复制(默认复制整行)
ctrl + v 粘贴
ctrl + d 复制粘贴选中到下一行(默认整行)
ctrl + z 撤销
ctrl + shift + z 反撤销
ctrl + x 剪切(默认剪切整行)
ctrl + a 全选
ctrl + f 查找;选中批量修改
ctrl + shift + r 全局搜索
ctrl + y 删除整行
ctrl + w 选中一个单词
shift + enter 换行
shift + f10 执行上一次文件
ctrl + shift + f10 执行当前文件
ctrl + alt + l 格式化代码
ctrl + / 整体注释
home/end 回到行首/行尾
whilefor +else
当whilefor没有被break、正常循环完,执行else里的代码,否则不执行
字符串内置方法
'''
字符串 不可变数据类型 有序(有索引)
因为是不可变数据类型,字符串的内置方法需要重新赋值给变量名
s = 'nick handsome'
s_1 = s[1] #字符串索引
s[head:end:step] #索引切片(顾头不顾尾),head和end不写表示顶头
s[4:0:-1] #step为负数表示从后往前切
for i in s: #i取到s内的每一个字符
in/not in #成员运算
strip(str) #默认去除两端空格,可以指定多个字符
split(str, num) #按照指定内容切割,切割num次,返回一个列表
len(str) #获取字符串长度
lstrip()/rstrip() #去除左右空格
lower()/upper() #全部变大写/全部变小写
capitalize() #第一个字母变大写,其他变小写
title() #每个单词第一个字母变大写,其他变小写
startswiht()/endswith() #是否以指定字符开头/结尾,返回布尔值
rspit(str, num) #从后往前切割,切割num次,再前面不切割,视作一个字符串,返回一个列表
str.join(lis) #以str拼接列表lis内每一个元素,返回一个字符串
str.join(str1) #str1的每两个字符间插入str,如果len(str1)==1,则结果是str1
replace(old, new, num) #用新的字符new替换原有字符old, num为替换次数,默认全部替换
isdigit()/isalpha()/isalnum() #判断字符串是否只由数字/字母/字母和数字组成,返回布尔值
find(str)/rfind(str) #返回str在字符串中的索引,如果返回-1表示str不存在于字符串中
index(str) #找到str返回索引,找不到报错,所以推荐使用find()
count(str, start, end) #在[start,end)范围内统计str的次数,默认查找整个字符串
center(num, str)/ljust()/rjust() #居中/居左/居右输出字符串,num为输出长度,str为填充内容
zfill(width) #在前面填充0,在进制中用到,width为填充后的长度
#缩进
expandtabs(num) #控制每个缩进 的空格长度,
swapcase() #大写变小写,小写变大写
'''
列表内置方法
'''
列表 可变数据类型 有序(有索引)
因为是可变数据类型,列表的内置方法不需要重新赋值给变量名
lis = [11, 22, 33, 44]
lis_1 = lis[1] #索引取值
lis[1] = 55 #索引修改值
lis[1:3] #切片
for i in lis: #i循环取到lis中的每一个值
in/not in #成员运算
len(lis) #返回列表长度
append(new) #在列表末尾增加一个新元素
del lis[num] #按索引删除列表中的某个元素
insert(index, obeject) #在索引位置为index的前面,插入新元素object
pop(index) #按索引删除列表中的某个值,可以得到删除的值
remove(object) #按值删除列表元素
count(object) #按值统计次数
clear() #清空列表,返回一个空列表[]
copy() #拷贝列表,拷贝得到的新列表的地址与原列表不同
extend(lis1) #在列表后插入lis1中的元素
reverse() #反转列表
sort() #升序排序
sort(reverse = True) #降序排序
sorted() #升序排序,返回一个新列表,也就是可以保留原列表
'''
字典内置方法
'''
字典内置方法 可变数据类型 (key为不可变数据类型)
dic = {'name':'slk', 'age':18, 'height':180}
按key取值/修改值
len() #返回字典长度
in/not in #成员运算
del dic[key] #删除某个键值对
keys()/values()/items() #取到字典的键/值/键值对
for循环
get(key, new_value) #如果key in dic,返回dic[key];如果key not in dic,返回new_value,默认返回 None
update(dic_new) #在字典后增加字典(键值对)
fromkeys({key1,key2,key3},values) #新建一个字典,但初始化的值都是一样的
setdefault(key, values1) #当key in dic时,返回dic[key];当key not in dic时,返回values1,并增 加新的键值对
copy() #复制
pop(key) #取出值,并删除键值对
popitem() #不需要传值,默认删除最后一个键值对
'''
集合内置方法
'''
集合内置方法 可变数据类型 元素为不可变数据类型 乱序(数字不乱序)
主要作用: 去重
| #并集
& #交集
- #差集
^ #交叉补集
add() #增加一个元素
pop() #随机删除
update(set1) #在后面加入set1中的元素
clear() #清空
remove(n) #按值删除指定元素,如果没有该元素,则报错,因此推荐使用discard()
discard(n) #按值删除指定元素,如果没有该元素,则返回None
set1.issubset(set2) #判断set1是不是set2的子集
set1.issuperset(set2) #判断set1是不是set2的父集
set1.difference_update(set2) #去掉set1中set1和set2的交集
set1.isdisjoint(set2) #判断set1,set2中是否有相同元素,返回布尔值
可变长参数
形参中*的会将溢出的位置实参全部接收,然后存储元组的形式,然后把元组赋值给*后的参数
实参中的*,会将*后参数的值循环取出,打散成位置实参
形参中的**,**会将溢出的关键字实参全部接收,然后存储字典的形式,然后把字典赋值给后的参数
实参中的**,**会将**后参数的值循环取出,打散成关键字实参
名称空间和作用域
内置名称空间:数据类型自带内置方法;python解释器自带内置方法
全局名称空间:除了内置和局部都叫全局
局部(本地)名称空间:函数内部定义
加载顺序:内置命名空间->全局命名空间->本地命名空间
查找顺序:本地命名空间->全局命名空间->内置命名空间 (不可逆)
*作用域关系在函数定义阶段就固定死了,与函数的调用无关
默认形参
当默认形参是不可变数据类型时,如果没有给默认参数传值,则每次调用函数默认参数的初始值都是默认值;
当默认形参是可变数据类型时,如果没有给默认参数传值,则调用函数时默认参数可以随着函数内代码的运行改变
global关键字
修改全局作用域中的变量
nonlocal关键字
修改局部作用域中的变量,是变量成为顶层局部的变量
- 在局部想要修改全局的可变类型(内置方法,不开辟新的空间就可以),不需要任何声明,可以直接修改。
- 在局部如果想要修改全局的不可变类型,需要借助global声明,声明为全局的变量,即可直接修改。
内置函数
# bytes(str, enconding) 解码字符,转成二进制(pycharm终端打印16进制)
# bytes(str, encoding = 'utf-8')
# str.encode(''utf-8)
# chr()/ord() 参考Ascii码表,chr():数字转字符,ord()字符转数字
# divmod(a, b) 返回元组(a//b, a%b)
# enumerate(iterable) 返回带索引的迭代
# eval(str) 将字符串转成对应数据类型,也可以返回字符串中的结果('3*7'->21)
# hash(object) 返回对象object的hash值
# abs(i) 返回绝对值
# all(iterable) 可迭代对象内元素全为真,则返回真; *空元组、空列表返回值为True
# any(iterable) 可迭代对象中有一元素为真,则为真; *空元组、空列表返回值为False
# bin()/oct()/hex() 转二进制/八进制/十六进制
# dir() 返回模块的所有功能
# frozenset() 返回一个不可变集合(强制类型转换)
# globals/locals 以字典形式返回所有全局/当前位置的变量
# pow(x,y,z=1) 返回(x**y)%z
# round(float,n=0) 返回浮点数的四舍五入值,n是舍入的小数位数,默认是0,即返回整数
# slice(start, stop, step) 设置切片(print(lis[slice(1, 5, 1)]))
# sum(iterable) 求和
# __import__() 动态导入模块?
软件开发目录规范
ATM/
|-- core/
| |-- src.py # 业务核心逻辑代码
|
|-- api/
| |-- api.py # 接口文件
|
|-- db/
| |-- db_handle.py # 操作数据文件
| |-- db.txt # 存储数据文件
|
|-- lib/
| |-- common.py # 共享功能
|
|-- conf/
| |-- settings.py # 配置相关
|
|-- bin/
| |-- run.py # 程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤
|
|-- log/
| |-- log.log # 日志文件
|
|-- requirements.txt # 存放软件依赖的外部Python包列表,详见https://pip.readthedocs.io/en/1.1/requirements.html
|-- README # 项目说明文件
异或运算
'''
与运算& A、B均为1,结果才为1,否则为0
或运算| A或B为1时,结果才为1,否则为
异或运算^ A和B不同为1时,结果才为,否则为
按位取反~ 二进制取反
'''
进制转化
| 进制转换 | 2进制 | 8进制 | 10进制 | 16进制 |
|---|---|---|---|---|
| 2进制 | - | oct(int(x, 2)) | int(x, 2) | hex(int(x, 2)) |
| 8进制 | bin(int(x, 8)) | - | int(x, 8) | hex(int(x, 8)) |
| 10进制 | bin(int(x, 10)) | oct(int(x, 10)) | - | hex(int(x, 10)) |
| 16进制 | bin(int(x, 16)) | oct(int(x, 16)) | int(x, 16) | - |
列表示转换前, 行表示转换后, x是字符串
uuid模块
import uuid
#基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性
res = uuid.uuid1()
print(res, type(res))
isinstance
#判断对象是否是class的一个实例
isinstance(obj, class)
issubclass
#判断cls1是否是cls2的子类
issubclass(cls1, cls2)
OS库的使用
对文件操作
| 方法 | 注释 |
|---|---|
| os.path.file(path) | 判断是否为文件 |
| os.remove(path) | 删除文件 |
| os.remove(old_path, new_path) | 重命名文件 |
| os.getcwd() | 返回当前文件所在文件夹路径 |
| file | 当前文件所在的具体路径 |
| os.path.dirname() | 返回上一层目录 |
对文件夹操作
| 方法 | 注释 |
|---|---|
| os.path.isdir() | 判断是否为文件夹 |
| os.mkdir() | 创建文件夹 |
| os.rmdir() | 删除文件夹 |
| os.listdir() | 列出文件夹内所有的文件 |
| 方法 | 注释 |
|---|---|
| os.path.join() | 拼接文件路径 |
| os.path.exists() | 判断路径是否存在 |
json库
| 方法 | 注释 |
|---|---|
| json.dump(object, f) | 序列化 |
| json.load(f) | 反序列化 |
pickle库
| 方法 | 注释 |
|---|---|
| pickle.dump(object, f) | 序列化 |
| pickle.load(f) | 反序列化 |
random库
| 方法 | 注释 |
|---|---|
| random() | (0,1)的随机数 |
| randint(start,end) | [start, end]的随机数 |
| shuffle(lis) | 乱序 |
| choice(lis) | 随机选一个 |
| seed(num) | 随机种子,默认随机,当有固定的种子数时,输出固定 |
| sample(lis, n) | n表示取n个数随机组合 |
hashlib库
import hashlib
'''
对字符加密
'''
#叠加性
m = hashlib.md5()
m.update(b'say')
m.update(b'hello')
print(m.hexdigest())
垃圾回收机制
垃圾回收机制(简称GC)是Python解释器自带的一种机制,专门用来回收不可用的变量值所占用的内存空间
作用
程序运行过程中会申请大量的内存空间,而对于一些无用的内存如果不及时清理的话会导致内存溢出,导致程序崩溃,python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来
原理分析
Python的GC模块主要运用了‘引用计数’来跟踪和回收垃圾。在引用计数的基础上,还可以通过’标记清除‘解决容器对象可能产生的循环引用的问题,并且通过’分代回收‘以空间换时间的方式来进一步提高垃圾回收的效率
引用计数
引用计数就是变量值被变量名关联的次数
引用计数增加的情况:
- 对象被创建
- 对象被引用
- 对象作为参数,传入到一个函数中
- 对象作为一个元素,存储在容器中
引用计数减少的情况:
- 对象的别名被显式销毁(例:del a)
- 对象的别名被赋予新的对象
- 对象离开它的作用域,例如函数执行完毕时,函数中的局部变量(全局变量不会)
- 对象所在的容器被销毁,或从容器中删除对象
对象的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
缺点
变量值被关联次数的增加或减少,都会引发引用计数机制的执行,存在明显的效率问题
循环引用问题
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
循环引用会导致:值不再被任何名字关联,但是值的引用计数不为0,应该被回收但不能被回收
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1
>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1
此时只剩下列表1和列表2之间的相互引用,两个列表的引用计数均不为0,但是两个列表不再被任何其他对象关联,没有任何人可以再引用到他们,所以他们占用的内存空间应该被回收,但是由于相互引用的存在,每个对象的引用计数都不为0,所以他们占用的内存永远都不会被释放,
所以,Python引入了‘标记清除‘和’分代回收’来分别解决引用计数的循环引用与效率低的问题
标记清除
解决容器类对象可能产生的循环引用问题(注意:只有容器类对象才会产生循环引用的情况,比如列表、字典、用户自定义类的对象、元组等;像数字字符串这类简单类型不会出现循环引用;作为一种优化策略,对于只包含简单类型的元组,也不在标记清除算法的考虑之列)
在python中,关于变量的存储,内存中有两块区域:堆区和栈区,在定义变量时,变量名与值内存地址的关联关系存放在栈区,变量值存放于堆区,内存管理回收的是堆区的内容
当定义行x=10,y=20时,
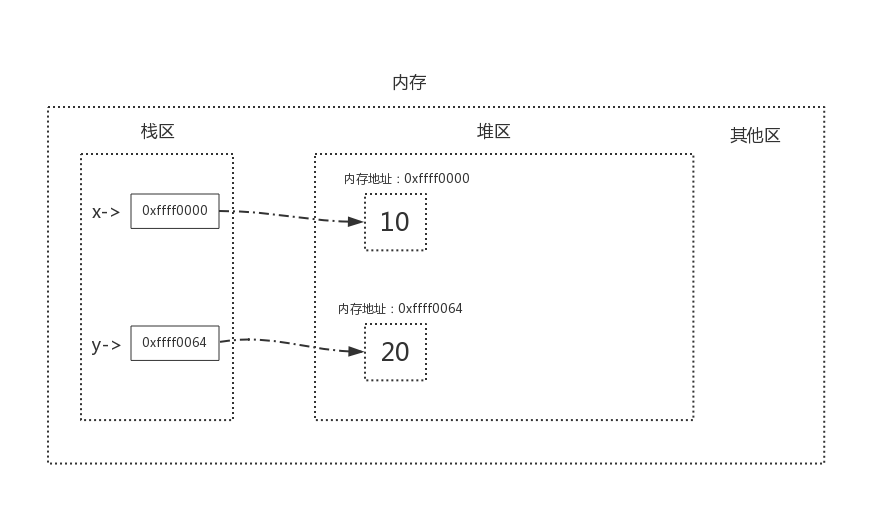
当执行x=y时,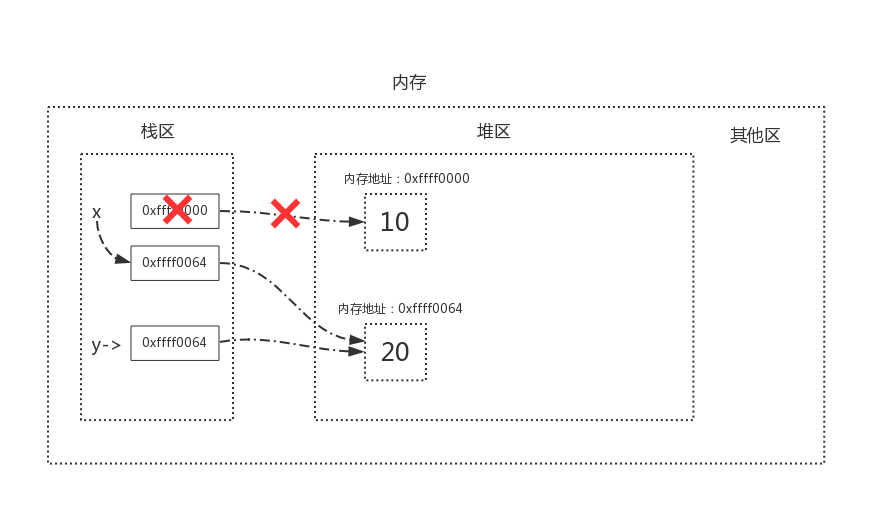
标记清除算法的做法是当应用程序可用的内存空间被耗尽时,就会停止整个程序,然后进行两项工作,一是标记,二是清除
#1、标记
标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
#2、清除
清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
直接引用指的是从栈区出发直接引用到的内存地址,间接引用指的是从栈区出发引用到堆区后再进一步引用到的内存地址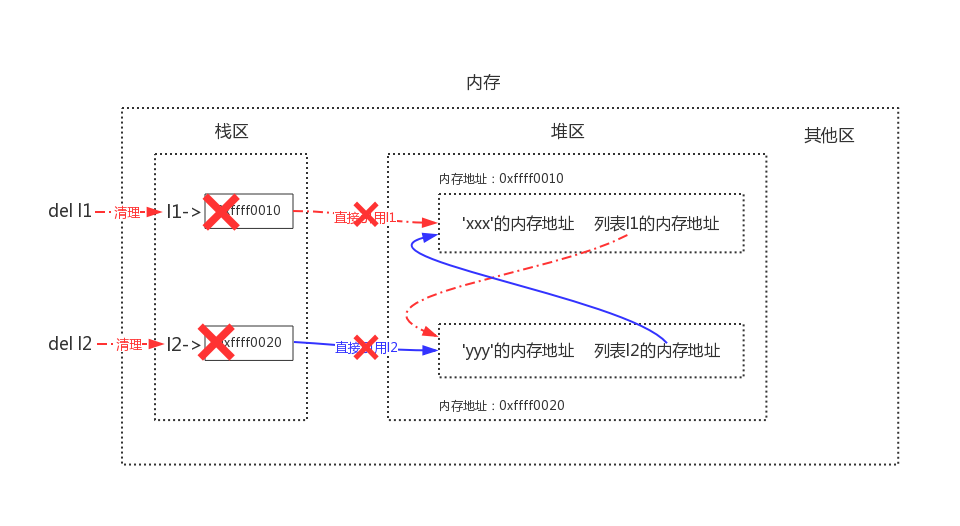
这样在启用标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
分代回收
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
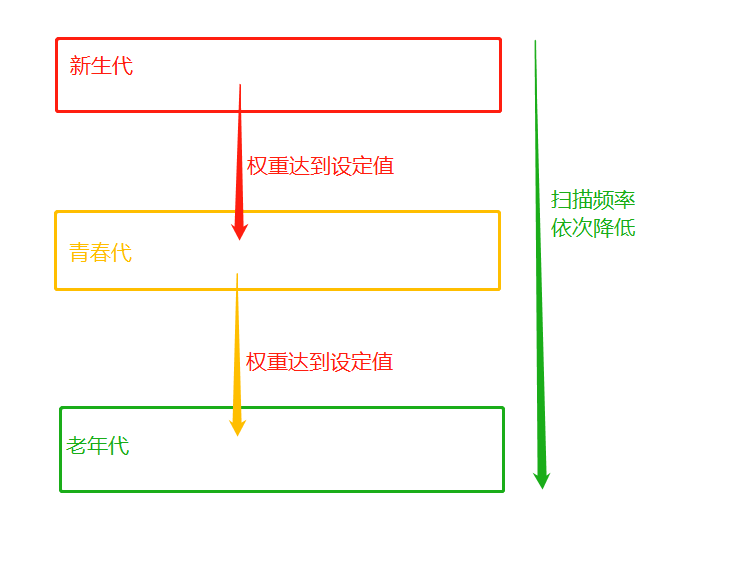
缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。
三次握手和四次挥手
当应用程序想通过TCP协议实现远程通信时,彼此之间必须先建立“双向”通信通道,基于该双向通道实现数据的远程交互,该双向通道直道任意一方主动断开才会失效
三次握手
首先服务端和客户端都处于close状态,服务端进程先创建传输控制块tcp,服务端就进入listen状态,监听客服端发送的请求;
客户端主动想要和服务端建立连接,创传输控制块tcp,向服务端发送请求,即能否建立客户端向服务端的通道,然后客户端就进入了SYN-SENT(同步已发送)状态;
服务端接受到客服端的请求后,同意客户端建立通道的请求,并请求建立服务端向客服端的通道,服务端将回复信息和请求一次发送给客户端,然后服务端就进了SYN-RCVD(同步已接受)状态;
客户端接收到服务端的回复和请求后,客户端向服务端的通道就建立了,并处理请求,回复同意建立服务端向客服端的通道,然后客服端就进入了ESTABLISHED(已建立连接)状态;
服务端接收到客服端的回复后,服务端向客服端的通道就建立了,此时双向管道都已建立,服务端进入ESTABLISHED(已建立连接)状态,然后双方就可以进行远程通信了。

四次挥手
客服端和服务端都处于ESTABLISHED状态,双方正常通信;
客户端主动想要断开连接,向服务端发送连接释放报文,此时客服端就不在向服务端发送数据了,然后客户端就进去了FIN-WAIT-1状态;
服务端收到连接释放请求后,同意请求,此时服务端就进入了CLOSE-WAIT(关闭等待)状态,并发出确认报文,然后客服端向服务端的通道就断开了,这时候就处于半连接状态(只剩下服务端向客服端的通道),但是服务端可能还有未发送完的数据;
客服端接收到服务端的确认请求,进入FIN-WAIT-2状态,等待服务端发送连接释放请求;
(数据传输。。。)
服务端在最后的数据发送完成后,会向客服端发送连接释放请求,此时服务端进入LAST-ACK(最后确认)状态,等待客服端的最后确认;
客服端接收到服务端的连接释放请求后,必须返回确认信息,此时客户端进入TIME-WIAT(时间等待)状态,但此时tcp连接还没有释放,需要等待2个最长报文段寿命的时间后,撤销tcp控制块,进入CLOSE状态;
服务端接收到客户端的确认信息后,立即进入CLOSE状态,撤销tcp,结束连接。

常见面试题
-
为什么客户端最后还要等待2MSL?
在服务端发送完数据后,会向客服端发送连接释放请求,但是这个请求可能会丢失,服务端就不会接收到客服端返回的确认信息,那么服务端就会重新发送请求,客户端就能在2MSL的时间内接收到连接释放请求
-
为什么建立连接是三次,断开连接是四次?
建立连接时,服务端接收到客户端发送的建立连接请求时,确认信息和建立通道请求是一次发送的;
断开连接时,因为可能会有为发送完的数据要发送,所以确认信息和断开连接请求是分开发送的,就比建立连接时多了一个。
-
如果已经建立了连接,但是客户端出了故障怎么办?
服务端会有一个计时器,每收到客户端的一个请求,计时器就会重置;
如果2小时没收到客服端的任何数据,就会每隔75s发送一个探测报文;
如果连发10个探测报文,都没有得到回复,服务端就会确认客户端发生了故障,并断开连接。
-
为什么不能两次握手建立连接?
为了方式已经失效的请求突然来到而产生的错误。
假设,客服端向服务端发送了建立连接的请求,但是因为某些原因在某个网络节点卡了很久,那么客服端就会重新发送一个连接请求,此时服务端正常接收,并建立连接,完成数据传输。
但这之后,服务端突然就接收到了刚才卡住的连接请求,如果是两个握手,那么就会建立连接,服务端就会一直等待客服端发送数据,造成资源浪费;如果是三次握手,因为这并不是真正客户端发送的连接请求,客服端也就不回等待服务端的确认,而服务端因为没有接收到客户端的确认请求,也就不会建立连接。
GIL锁
GIL不是python的特性,它是在实现python解释器时所引入的一个概念
GIL锁保证了同一时刻只有一个线程在运行,解决了线程间数据一致和状态同步的问题,确保了数据的安全
执行方式:
- 设置GIL锁
- 切换到一个线程去执行
- 线程运行了一定的时间或者遇到IO操作
- 设置线程状态为睡眠
- 释放GIL
- 循环以上
MYSQL引擎
- innodb:
- MyIsam:默认
- InnoDB支持事务,MyIsam不支持事务
- InnoDB可以回滚还原,MyIsam不可以
- InnoDB支持外键,MyIsam不支持
- InnoDB适合频繁修改和涉及到安全性较高的应用,MyIsam适合查询以及插入为主的应用
单例模式
-
类的绑定方法
class File: __instance = None # 单例方式1: @classmethod def singleton(cls, *args,**kwargs): if not cls.__instance: obj = cls(*args,**kwargs) cls.__instance = obj return cls.__instance -
new
class File: __instance = None # 单例方式2: def __new__(cls, *args, **kwargs): # cls.__new__(cls, *args, **kwargs) if not cls.__instance: cls.__instance = object.__new__(cls) return cls.__instance -
装饰器
def singleton(cls): cls.__instance = cls(*args,**kwargs) def wrapper(*args, **kwargs): if len(args) == 0 and len(kwargs) == 0: return cls.__instance return cls(*args, **kwargs) return wrapper