1,字符串(String)
···String为特殊的引用类型,不可变。
···常用实例方法:
获取子串:substring(start, end);
获取索引:indexOf(char);
获取字符:charAt(index);
···常用静态方法:
格式字符串:String.format("%s", 12);
转为字符串:String.valueOf();
格式拼接:String.join(", ", list);
···扩展:
StringBuilder:可变对象,用来高效拼接字符串。
StringBuffer:是StringBuilder的线程安全版。
··· 注意:
· String.valueOf()比str.toString()安全;
· 常量池默认只会在编译期对字符串字面量和常量进行优化;可以通过"".intern()方法在运行期将堆中的字符串放入常量池。
2,数组
···可以通过索引访问,初始化必须指定大小,并且不可改变。
···常用方法:
排序:Arrays.sort(int[]);
转list:Arrays.asList(int[]); // 返回的list是固定长度的,不能改变。最好用for一个个转。
扩容:Arrays.copyOf(int[], newlenght);
填充:Arrays.fill(int[], int);
···转Set:
Set<T> set = new HashSet<>(Arrays.aslist(int[]));
由于Set构造方法的参数必须继承自Collection接口,所以要先把数组转list。
···逆序排序:
Integer[] a = new Integer[5];
Comparator<Integer> cmp = new Comparator<>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
};
Arrays.sort(a, cmp);
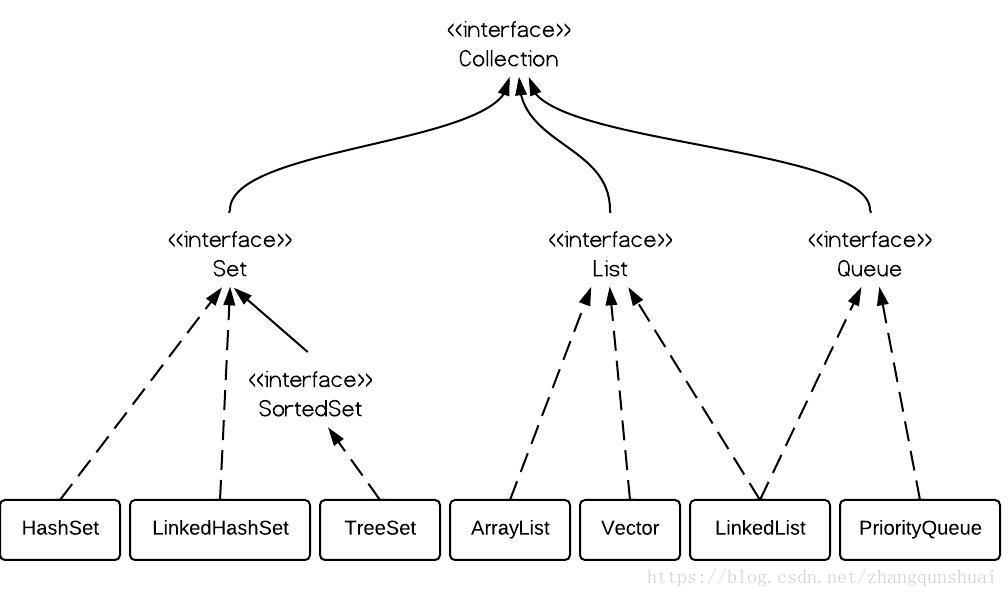

3,列表(List)
···实现类:
ArrayList:数组实现;LinkedList:链表实现;Vector:线程安全;
···常用实例方法:
根据索引查找:get(index);
判断是否存在:contains(obj);
查找索引:indexOf(obj);
排序:sort(Comparator);
合并两个list:addAll(list);
转数组:toArray(new Obj[]{});
···常用静态方法:
排序:Collections.sort(list,Comparator);
逆序:Collections.reverse(list);
求最值:Collections.max(list); Collection.min(list);
浅拷贝:Collections.copy(dest, src); // dest的实际长度必须大于或等于src
···List的stream方法:
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3));
List<Integer> a = list.stream().map(x-> x*2).collect(Collectors.toList());
4,集合(Set)
···实现类:
HashSet:数组实现,无序(有规律);TreeSet:自动排序;LinkedHashSet:链表实现,保持原序;
···注意:
由于Set也继承自Collection接口,所以其他方法与List类似,底层实现也是Hash,相当于是没有value的Map。
5,键值对(Map)
···实现类:
HashMap:数组实现,无序;TreeSet:根据Key排序;LinkedHashMap:保持原序;
···常用实例方法:
获得所有Key:KeySet(),返回值为Set类型;
获得所有Value:values();
···排序:
先把map.entrySet()放入list,再用Collection.sort(list, Compartor);对list的value排序,再把list放入LinkedHashMap中即可。
···注意:
HashMap中的key和value都可以为null。而Hashtable不可以。
··· *底层理解*:
·大致实现:HashMap底层使用的是哈希表加链表。输入的key是对象的hashCode;哈希函数是hashCode & (lenght - 1);哈希冲突的解决办法是使用链表保存哈希值相同的对象。当链表长度大于8时使用红黑树保存(jdk1.8开始);查询时先通过对象的hashCode找到对象在数组的位置,然后通过equals()遍历链表,找到目标对象。
·细节优化: 哈希函数hashCode & (lenght-1)是位运算, 比模运算快很多;由于哈希函数是hashCode & (lenght-1),所以当哈希表的长度lenght是2的幂次方时哈希表的利用率最高,哈希冲突也就越小,比如:当lenght为15时hashCode & 14,hashCode & 1110 时第一位0与上任何数都为0,所以哈希函数的结果永远不会出现第一位为1的情况,即0001、0011等位置上永远不会存值,导致实际利用长度变小,也就越容易出现哈希冲突。
·扩容:由于数组的长度固定(默认是16),所以当实际长度超过最大长度的75%时,需要对哈希数组进行扩容,增大为原最大长度的2倍,并将旧哈希表的元素重新计算哈希值放入新的哈希表中,非常消耗性能,所以在初始化时尽量指定长度,以避免扩容。例如:需要存放1000个元素时,指定初始化大小为2048(1024*75%<1000所以还会扩容,因此选择2048)。
6,包装类型
···概念:包装类型是把基本类型包装为引用类型,把基本类型转为引用类型称为装箱,反之为拆箱。
···优点:
· 与基本类型相比,包装类型提供了大量实用的方法。
· 在项目中尽量使用包装类型,因为包装类型的null和0可以区分有值和没值。
注意事项
· a=a+12 与 a+=12 的区别:当a为short时,使用会把12当成int类型;而使用 += 时,会把右边的字面量12转为左边变量的类型。
· 进制显示:二进制(0b):int b=0b101; 八进制(0):int e=032; 十六进制(0x):int h=0xf1;
· Boolean类型:boolean类型可以进行 位运算,并且运算符优先级:>, &, &&,且位运算符与逻辑运算符的效果一样,但是不会短路。