变量的定义,变量的命名规则,python中变量的具体命名方式,python中变量的存储、赋值与深浅拷贝
一、变量的定义
字面意思,即可变的量,与之相对的有常量。(在python中未明确定义常量,变量名全大写代指常量)
常见的编程语言,在实用变量之前,必须先声明(包括变量名,数据类型等),但python中,可以在未声明情况下直接定义,和调用。
二、python的变量命名规则
- 有描述性,简单、概括、通用
- 只能是数字、字母、下划线组成,不能有特殊字符,数字不能在首位
- 不能使用特殊的保留字符(如for,print等)
- 不能使用中文或者拼音,虽然目前,python3.x版本支持中文作为变量名。
- 推荐下划线为间隔的命名方式,不建议变量名过长
- 习惯上,当命名时全都大写的时候,认为是一个常量,可以作为一个常量来用。但在python中默认是不区分常量的。即,如果强制修改常量,python不会报错。
- 永远不要使用 'l'(小写的L),'O'(大写的O),或者'I'(大写的I)作为单字变量名。主要是由于在某些字体中,这些字很难和数字的0 和 1 区分。所以当打算用'l'的时候,用'L'来代替。
- 其他规则:
- xx:公有变量
- _xx:单前置下划线,私有化属性或方法,类对象和子类可以访问,from somemodule import *禁止导入
- __xx:双前置下划线,私有化属性或方法,只有类对象自己可以调用访问,无法在外部直接访问,子类也不行。
- __xx__:双前后下划线,系统定义名字(严禁自定义)
- xx_:单后置下划线,用于避免与Python关键词的冲突
三、变量的命名方式 (扩展摘抄)
总体,英文字母大小写、数字、下划线 _、及部分可用的特殊字符的有序组合,也能见到用中文的,避免出现此操作。变量名首字母必须为字母(a-z A-Z),下划线(_),也有用美元符号($)开始的情况。
目前,业界共有四种命名法则:驼峰命名法(变量一般用小驼峰法标识。)、匈牙利命名法、帕斯卡命名法(常用于类名,函数名,属性,命名空间)和下划线命名法(python官方推荐的命名方式),其中前三种是较为流行的命名法。
1,三种是较为流行命名法则
(1)驼峰命名法(C语言等常见)。正如它的名称所表示的那样,是指混合使用大小写字母来构成变量和函数的名字。例如,下面是分别用骆驼式命名法和下划线法命名的同一个函数:
printEmployeePaychecks();
print_employee_paychecks();
第一个函数名使用了驼峰命名法,函数名中的每一个逻辑断点都有一个大写字母来标记。第二个函数名使用了下划线法,函数名中的每一个逻辑断点都有一个下划线来标记。
驼峰命名法近年来越来越流行了,在许多新的函数库和Microsoft Windows这样的环境中,它使用得当相多。另一方面,下划线法是C出现后开始流行起来的,在许多旧的程序和UNIX这样的环境中,它的使用非常普遍。
(2)匈牙利命名法。广泛应用于象Microsoft Windows这样的环境中。Windows 编程中用到的变量(还包括宏)的命名规则为匈牙利命名法,这种命名技术是由一位能干的 Microsoft 程序员查尔斯-西蒙尼(Charles Simonyi) 提出的。
匈牙利命名法通过在变量名前面加上相应的小写字母的符号标识作为前缀,标识出变量的作用域、类型等。这些符号可以多个同时使用,顺序是先m_(成员变量)、再指针、再简单数据类型、再其它。这样做的好处在于能增加程序的可读性,便于对程序的理解和维护。
例如:m_lpszStr, 表示指向一个以0字符结尾的字符串的长指针成员变量。
匈牙利命名法关键是:标识符的名字以一个或者多个小写字母开头作为前缀;前缀之后的是首字母大写的一个单词或多个单词组合,该单词要指明变量的用途。
(3)帕斯卡(pascal)命名法(大驼峰命名法)。与驼峰命名法类似,二者的区别在于:驼峰命名法是首字母小写,而帕斯卡命名法是首字母大写。所以有时也称之为大驼峰命名法,如:
DisplayInfo();
stringUserName;
二者都是采用了帕斯卡命名法。
(4)三种命名规则的小结:MyData就是一个帕斯卡命名的示例;myData是一个驼峰命名法,它第一个单词的第一个字母小写,后面的单词首字母大写,看起来像一个骆驼;iMyData是一个匈牙利命名法,它的小写的i说明了它的型态,后面的和帕斯卡命名相同,指示了该变量的用途。
2 命名的基本原则
(1)标识符的命名要清晰、明了,有明确含义,同时使用完整的单词或大家基本可以理解的缩写,避免使人产生误解——尽量采用采用英文单词或全部中文全拼表示,若出现英文单词和中文混合定义时,使用连字符“_”将英文与中文割开。较短的单词可通过去掉“元音”形成缩写;较长的单词可取单词的头几个字母形成缩写;一些单词有大家公认的缩写。例如:temp->tmp、flag->标志寄存器、statistic->stat、increment->inc、message->msg等缩写能够被大家基本认可。
(2)命名中若使用特殊约定或缩写,则要有注释说明。应该在源文件的开始之处,对文件中所使用的缩写或约定,特别是特殊的缩写,进行必要的注释说明。
(3)自己特有的命名风格,要自始至终保持一致,不可来回变化。个人的命名风格,在符合所在项目组或产品组的命名规则的前提下,才可使用。(即命名规则中没有规定到的地方才可有个人命名风格)。
(4)对于变量命名,禁止取单个字符(如i 、j 、k... ),建议除了要有具体含义外,还能表明其变量类型、数据类型等,但i 、j 、k 作局部循环变量是允许的。变量,尤其是局部变量,如果用单个字符表示,很容易敲错(如i写成j),而编译时又检查不出来,有可能为了这个小小的错误而花费大量的查错时间。
(5)除非必要,不要用数字或较奇怪的字符来定义标识符。
(6)命名规范必须与所使用的系统风格保持一致,并在同一项目中统一。
(7)在同一软件产品内,应规划好接口部分标识符(变量、结构、函数及常量)的命名,防止编译、链接时产生冲突。对接口部分的标识符应该有更严格限制,防止冲突。如可规定接口部分的变量与常量之前加上“模块”标识等。
(8)用正确的反义词组命名具有互斥意义的变量或相**作的函数等。
下面是一些在软件中常用的反义词组。
add / remove begin / end create / destroy
insert / delete first / last g et / release
increment / decrement put / get
add / delete lock / unlock open / close
min / max old / new start / stop
next / previous source / target show / hide
send / receive source / destination
cut / paste up / down
示例:
int min_sum;
int max_sum;
int add_user( BYTE *user_name );
int delete_user( BYTE *user_name );
(9)除了编译开关/ 头文件等特殊应用,应避免使用_EXAMPLE_TEST_ 之类以下划线开始和结尾的定义。
3 关于命名规则的其他内容
(1)变量的命名规则要求用“匈牙利法则”。(比较难以掌握)
即开头字母用变量的类型,其余部分用变量的英文意思、英文的缩写、中文全拼或中文全拼的缩写,要求单词的第一个字母应大写。
即: 变量名=变量类型+变量的英文意思(或英文缩写、中文全拼、中文全拼缩写)
对非通用的变量,在定义时加入注释说明,变量定义尽量可能放在函数的开始处。
见下表:
bool 用b开头 b标志寄存器
int 用i开头 iCount
short int 用n开头 nStepCount
long int 用l开头 lSum
char 用c开头 cCount
unsigned char 用by开头
float 用f开头 fAvg
double 用d开头 dDeta
unsigned int(WORD) 用w开头 wCount
unsigned long int(DWORD) 用dw开头 dwBroad
字符串 用s开头 sFileName
用0结尾的字符串 用sz开头 szFileName
(2)指针变量命名的基本原则为:
对一重指针变量的基本原则为:“p”+变量类型前缀+命名,如一个float*型应该表示为pfStat。对二重指针变量的基本规则为:“pp”+变量类型前缀+命名。对三重指针变量的基本规则为:“ppp”+变量类型前缀+命名。
(3)全局变量用g_开头,如一个全局的长型变量定义为g_lFailCount。
即:变量名=g_+变量类型+变量的英文意思(或缩写)。此规则还可避免局部变量和全局变量同名而引起的问题。
(4)静态变量用s_开头,如一个静态的指针变量定义为s_plPerv_Inst。
即: 变量名=s_+变量类型+变量的英文意思(或缩写)
(5)对枚举类型(enum)中的变量,要求用枚举变量或其缩写做前缀。并且要求用大写。如:
enum cmEMDAYS
{
EMDAYS_MONDAY;
EMDAYS_TUESDAY;
……
};
(6)对struct、union变量的命名要求定义的类型用大写。并要加上前缀,其内部变量的命名规则与变量命名规则一致。
结构一般用S开头,如:
struct ScmNPoint
{
int nX;//点的X位置
int nY; //点的Y位置
};
联合体一般用U开头,如:
union UcmLPoint
{
LONG lX;
LONG lY;
}
(7)对常量(包括错误的编码)命名,要求常量名用大写,常量名用英文表达其意思。
当需要由多个单词表示时,单词与单词之间必须采用连字符“_”连接。
如:#define CM_FILE_NOT_FOUND CMMAKEHR(0X20B) 其中CM表示类别。
(8)对const 的变量要求在变量的命名规则前加入c_。即:c_+变量命名规则;示例:const char* c_szFileName;
4 函数的命名规范
(1)函数的命名应该尽量用英文(或英文缩写、中文全拼、中文全拼缩写)表达出函数完成的功能——函数名应准确描述函数的功能。遵循动宾结构的命名法则,函数名中动词在前,并在命名前加入函数的前缀,函数名的长度不得少于8个字母。函数名首字大写,若包含有两个单词的每个单词首字母大写。如果是OOP 方法,可以只有动词(名词是对象本身)。示例:
LONG GetDeviceCount(……);
void print_record( unsigned int rec_ind ) ;
int input_record( void ) ;
unsigned char get_current_color( void ) ;
(2)避免使用无意义或含义不清的动词为函数命名。如使用process、handle等为函数命名,因为这些动词并没有说明要具体做什么。
(3)必须使用函数原型声明。函数原型声明包括:引用外来函数及内部函数,外部引用必须在右侧注明函数来源: 模块名及文件名;内部函数,只要注释其定义文件名——和调用者在同一文件中(简单程序)时不需要注释。
应确保每个函数声明中的参数的名称、类型和定义中的名称、类型一致。
5 函数参数命名规范(1)参数名称的命名参照变量命名规范。
(2)为了提高程序的运行效率,减少参数占用的堆栈,传递大结构的参数,一律采用指针或引用方式传递。
(3)为了便于其他程序员识别某个指针参数是入口参数还是出口参数,同时便于编译器检查错误,应该在入口参数前加入const标志。
如:……cmCopyString(const CHAR * c_szSource, CHAR * szDest)
6 文件名(包括动态库、组件、控件、工程文件等)的命名规范文件名的命名要求表达出文件的内容,要求文件名的长度不得少于5个字母,严禁使用象file1,myfile之类的文件名。
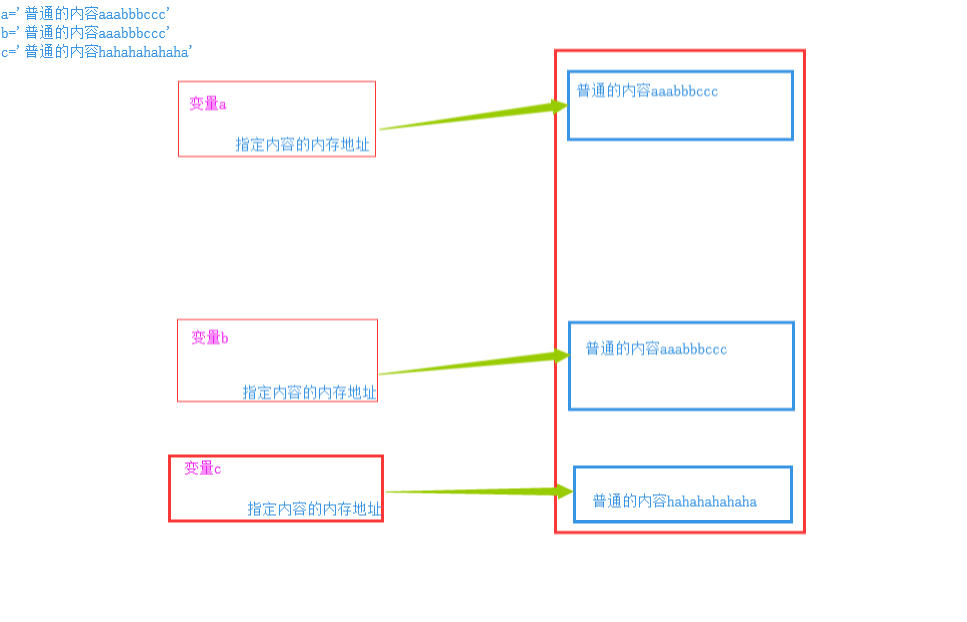
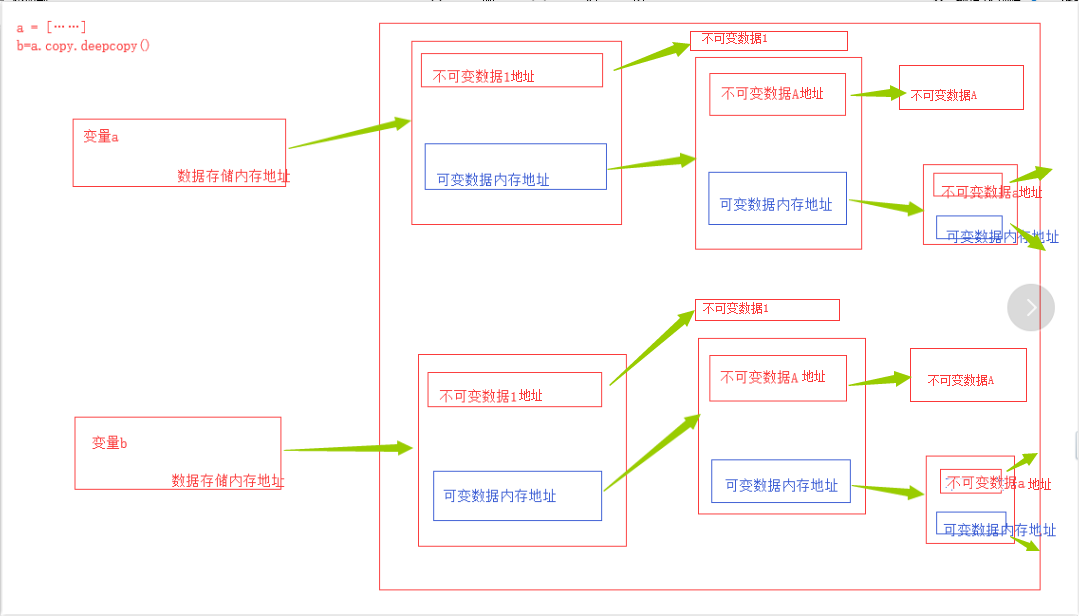
python中,所有的变量本身就是对象,而变量采用了引用语义的方式进行存储,本质上,变量存储的并非实际内容,而是实际内容所在的内存地址,存储过程即形成了变量和存储内容的内存地址之间的对应关系。python中的赋值,深浅拷贝本质上是对这种对应关系的操作。
查询变量内容的存储内存地址, id(内容)
变量的指向关系
先补充几个简单概念——
语义,数据所对应的现实世界中的事物所代表的概念的含义,以及这些含义之间的关系,是数据在某个领域上的解释和逻辑表示。(简单点讲就是,数据的含义)
值语义,
引用语义,
值语义中是直接将实际内容存储到变量的存储空间,而引用语义,在变量存储数据是,只是存储了变量所在的内存地址。
赋值过程,变量的修改或初始化过程,本质上是给变量指定对应存储内存空间和其对应关系(内存地址)。根据数据存储的类型,进行内容和队形关系的修改。 如果修改的是不可变数据类型,则实际上是根据新的数据内容重新划分的内存空间,并修改变量存储的数据内存地址。如果修改的是可变的数据类型,则变量存储的内存空间不变,只是内存空间中存储的内容发生了变化。
语法方式:a = 具体内容
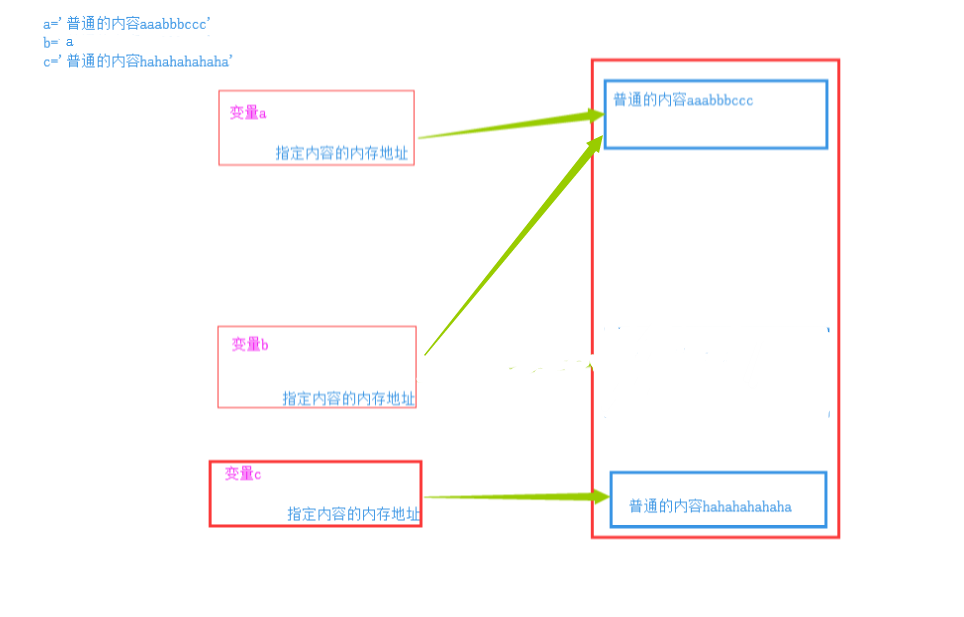
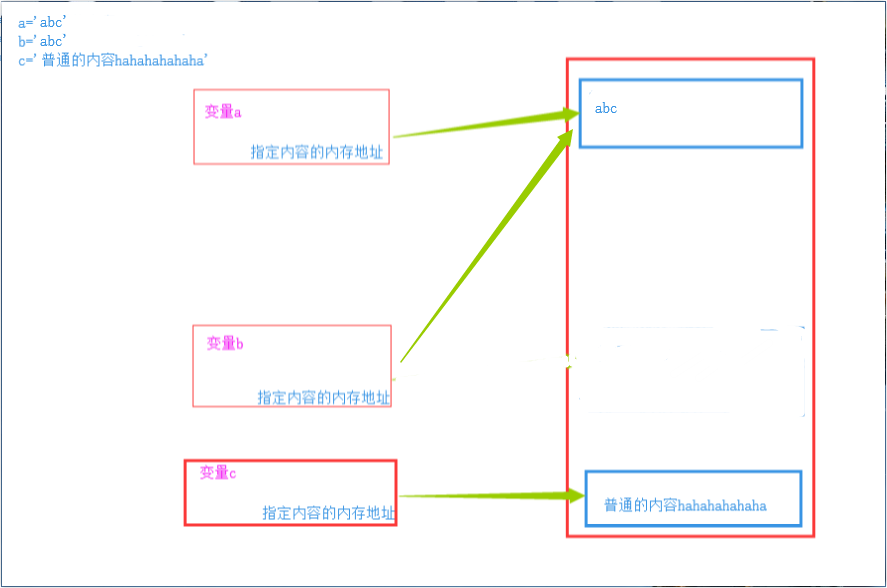
值得注意的是,对于 a = b,处理起来,python有一种智能识别,就是为了节省空间,对于短字符或者常用内容,python单独开辟了一段内存空间,内容相同时,python不再重复开辟空间进行存储,而是,直接将对应关系引到这段已经存储好内容的的内存空间。
浅copy,对变量单层存储内容进行了复制并在新的内存空间中进行了存储,对于可变数据类型的深层次对应关系和内容,不操作。得到的结果,浅层次独立,多层对应共享。
语法方式: 1 copy() ,2 copy.copy()
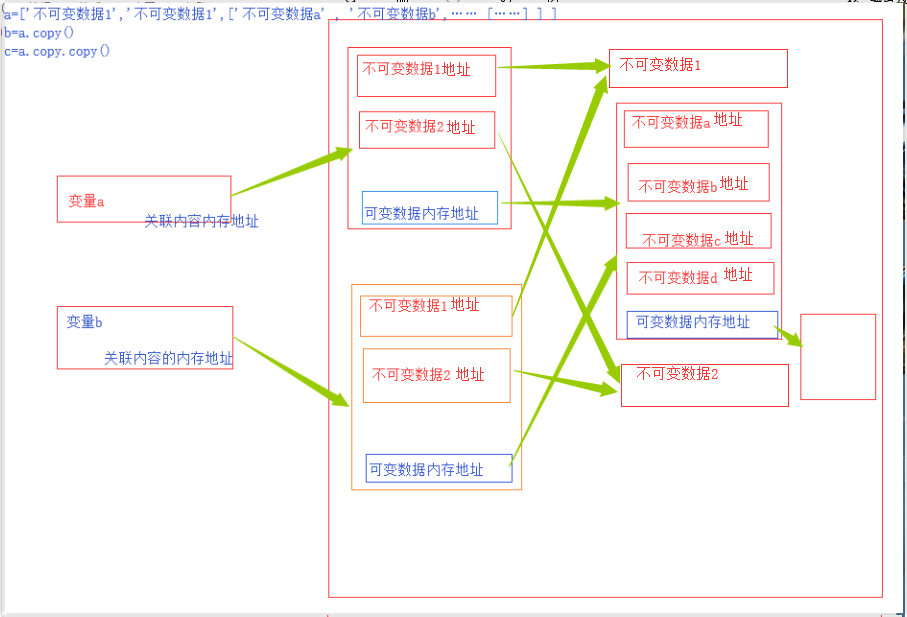
深copy,对变量所有的存储内容,包括可变类型数据产生的多层次对应关系,全复制。得到的结果完全独立
语法方式: copy.deepcopy()
None的简介
表示值为空。常用作占位符。
注意,None和空字符“”是有区别的。None在本质上是对象类型,而“”是一个空的字符串。
如果在判断的时候,推荐用身份运算符,is 进行判断。 例如 if name is None: ……