1.数据结构
数据结构:互相之间存在着一种或者多种关系的数据元素的集合和该集合中数据元素之间关系的组成.
简单说:数据结构就是设计数据以何种方式组织并存储在计算机中.(列表,字典,集合,都是一种数据结构)
数据结构分类:
①线性结构:
数据结构中的元素存在一对一的相互关系
②树结构:
数据结构中的元素存在一对多的相互关系
③图结构:
数据结构中的元素存在多对多的相互关系
2.列表(python)
注意:32位机器一个整数占4个字节,一个内存地址也是占4个字节
python时间复杂度
pop:O(1)
append:O(1)
indert:O(n)插入一个得把其他的先挪走,再插入
remove:O(n) 删一个得把其他的挪过来
数组与列表的不同:
1.一个数组内的元素类型要相同,列表可以不同(数组搜索时时间复杂度是O(1),他要确保每个元素固定长度才能直接取),数组存的是具体的值,列表存的是地址
2.数组长度固定,列表长度不固定,python列表长度不够时,他会重新开辟一块内存,比原来的长一些,再把原来的内容复制过来
3.栈
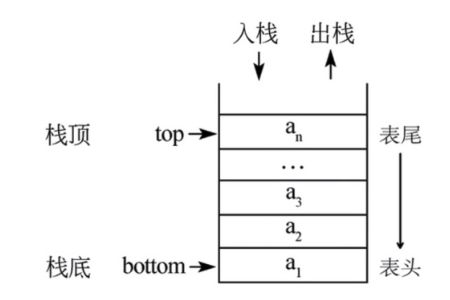
代码:
#用列表实现栈的功能 class Stack: def __init__(self): self.stack = [] def push(self, element): #进栈 self.stack.append(element) def pop(self):#出栈 if len(self.stack) > 0: return self.stack.pop() else: return None def get_top(self):#取栈顶 if len(self.stack) > 0: return self.stack[-1] else: return None def is_empty(self): #判断栈是不是空的 return len(self.stack) == 0 stack=Stack() print(stack.push(1)) print(stack.get_top()) print(stack.pop()) print(stack.pop())
栈的应用:
判断括号匹配问题:
给你一些括号(小括号,中括号,大括号),看看格式是不是对的
#栈的应用: # 思路:遇到左括号就往栈里添加,遇到右括号就取出(但是左右括号要是一对才行) # 这里只判断字符串里全是括号的情况,如有其他符号或者文字则不适用,需改代码 class Stack: def __init__(self): self.stack = [] def push(self, element): #进栈 self.stack.append(element) def pop(self):#出栈 if len(self.stack) > 0: return self.stack.pop() else: return None def get_top(self):#取栈顶 if len(self.stack) > 0: return self.stack[-1] else: return None def is_empty(self): #判断栈是不是空的 return len(self.stack) == 0 def brace_match(s): match = {'}':'{', ']':"[", ')':'('} #造字典用右括号直接取左括号 stack = Stack() for ch in s: if ch in {'(','[','{'}: stack.push(ch) else: #ch in {'}',']',')'},此时遇到了右括号 if stack.is_empty(): #如果栈里为空,直接来个右括号,那就是不对了 return False elif stack.get_top() == match[ch]:#如果当前栈顶存的括号与你遇到的括号匹配,那就把栈顶的括号取出,然后继续匹配下一个 stack.pop() else: # stack.get_top() != match[ch]#如果当前栈顶的括号与你遇到的括号不匹配就报错 return False if stack.is_empty(): return True else: return False print(brace_match('[{()}(){()}[]({}){}]')) print(brace_match('[]}'))
4.队列
队列是个数据集合,仅允许在列表的一端进行插入,另一端进行删除
队尾:可以进行插入的一端(插入称为:进队/入队)
队头:可以进行删除的一端(删除动作称为:出队)
队列的性质:先进先出(first-in first-out)FIFO
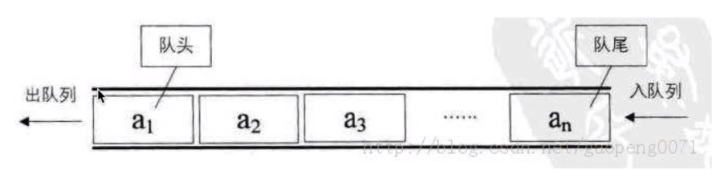
队列手动实现方式:环形队列
不能用列表,因为你要删除时(pop(0))操作时间复杂度是o(n)太大了,删一个其他的要补上来
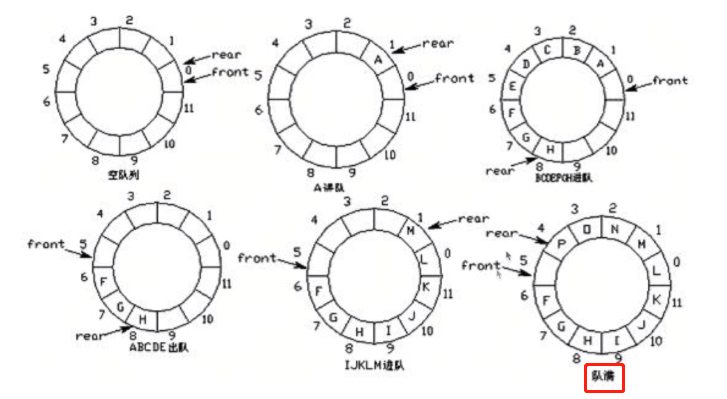
队首指针:front
队尾指针:rear
环形队列总长度为:maxsize(这里是12)
当队尾指针rear=maxsize-1时(这时rear=11)再向前一步就到了0
此时可以用%maxsize的方法取余数,就知道在队列的哪个位置了
队首指针前进1:front=(front+1)%maxsize
队尾指针前进1:rear=(rear+1)%maxsize
队空:其实就是队首和队尾相等,rear=front
队满:其实就是front比rear大1,(rear+1)%12=front
class Queue: def __init__(self, size=100): self.queue = [0 for _ in range(size)] self.size = size self.rear = 0 # 队尾指针 self.front = 0 # 队首指针 def push(self, element):#入队 if not self.is_filled(): self.rear = (self.rear + 1) % self.size self.queue[self.rear] = element else: raise IndexError("Queue is filled.") def pop(self):#出队 if not self.is_empty(): self.front = (self.front + 1) % self.size return self.queue[self.front] else: raise IndexError("Queue is empty.") # 判断队空 def is_empty(self): return self.rear == self.front # 判断队满 def is_filled(self): return (self.rear + 1) % self.size == self.front q = Queue(51) #长度为51的队列,只能容纳50个数字,因为自己设定的,队首和队尾之间要保持一个空格,否则无法判断是空还是满 for i in range(50): q.push(i) print(q.pop()) print(q.pop()) print(q.pop()) print(q.pop()) q.push(4)
双向队列(python内置模块deque)
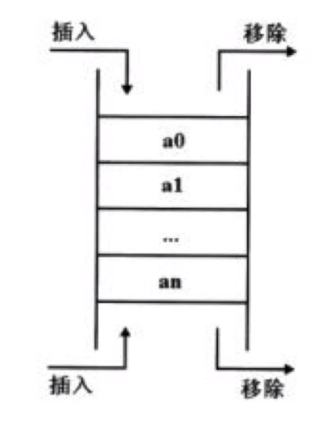
两端都支持进队和出队的队列
引用模块:
from collections import deque
创建队列:
队尾进队:append()
队首出队:popleft()
双向队列队首进队:appendleft()
双向队列队尾出队:pop()
代码:
from collections import deque # q = deque()#建空队列 q = deque([1,2,3,4,5], 5) #第一个参数,建队列,里面传5个值(1,2,3,4,5),第二个参数5,表示队列长度, # 如果超了,再入队就会把队首的值踢出去,如果是从队首添加,就会将队尾的值踢出去 q.append(6) # 队尾进队 print(q.popleft()) # 队首出队 # 用于双向队列 # q.appendleft(1) # 队首进队 # print(q.pop()) # 队尾出队
小应用:利用队列读取文件最后n行内容,类似linux的tail命令
def tail(n): with open('test.txt', 'r') as f: q = deque(f, n) #直接一行一行读,你取几行,我就建多长的队列,读到最后队列里就剩最后那几行 return q for line in tail(5): print(line, end='')
迷宫问题:

用栈来实现:
回溯法(深度优先法):起点开始每一点都从上右下左这四个方向试,能走就走,一条道走到黑,如果不行了,就原路返回,一个一个退,直到有叉路可以走就不退了,继续走.
走过的路径用栈来存储.
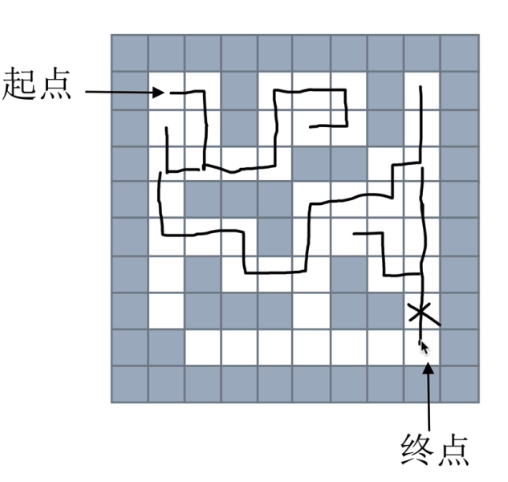
代码:这种并不是最优的方法,只能找到一种,但是不一定是最短的路径
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] dirs = [ lambda x,y: (x+1,y),#下 lambda x,y: (x-1,y),#上 lambda x,y: (x,y-1),#左 lambda x,y: (x,y+1) #右 ] def maze_path(x1,y1,x2,y2):#x1,y1是起点位置,x2,y2是终点位置 stack = [] stack.append((x1, y1))#起点坐标,列表存了个元组 while(len(stack)>0):#栈如果空了那么就认为是没有方法了,所有路都堵死了(注意:如果没有路可走,他就会退一格) curNode = stack[-1] # 当前的节点 if curNode[0] == x2 and curNode[1] == y2: # 走到终点了 for p in stack: print(p) return True # x,y 四个方向 上:x-1,y;下 x+1,y;左: x,y-1;右: x,y+1 for dir in dirs: nextNode = dir(curNode[0], curNode[1])#找下一个能走的节点 # 如果下一个节点能走 if maze[nextNode[0]][nextNode[1]] == 0:#0是路,1是墙 stack.append(nextNode) maze[nextNode[0]][nextNode[1]] = 2 # 2表示为已经走过 break else: maze[nextNode[0]][nextNode[1]] = 2 stack.pop() else: print("没有路") return False maze_path(1,1,8,8)
用队列实现:
队列:广度优先,
思路:起始点开始走,与到分岔路,所有的岔路同时一起走,直到有一条路先到了重点,这条路一定是最近的。
代码:
from collections import deque maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1) ] def print_r(path):#将你走过的路径打印出来 curNode = path[-1] realpath = []#存的是真实的路径 while curNode[2] != -1: realpath.append(curNode[0:2])#取节点0和1两个位置的坐标,不要最后2索引上的内容 curNode = path[curNode[2]] realpath.append(curNode[0:2]) # 起点 realpath.reverse()#倒序打印,就是从起点开始 for node in realpath: print(node) def maze_path_queue(x1, y1, x2, y2): queue = deque() queue.append((x1, y1, -1))#存的是x和y的值和带这个点进来的点的坐标(索引), # 第一个点默认就是-1坐标带他进来的,不是列表的最后一个,而是列表最左侧再出去一个的位置上 path = [] while len(queue) > 0: curNode = queue.popleft()#将队列头部的点弹出去,而不是结尾刚进来的点弹出去 path.append(curNode) if curNode[0] == x2 and curNode[1] == y2: # 此时到了终点 print_r(path) return True for dir in dirs:#循环dirs,找当前这个点的四个方向是否有能前进的点 nextNode = dir(curNode[0], curNode[1]) if maze[nextNode[0]][nextNode[1]] == 0:#如果该点能前进,那么就把该点加到队列中去 queue.append((nextNode[0], nextNode[1], len(path) - 1)) # 后续节点进队,记录哪个节点带他来的 maze[nextNode[0]][nextNode[1]] = 2 # 标记为已经走过 else: print("没有路") return False maze_path_queue(1, 1, 8, 8)#注意每一行或者每一列都是从0开始的
5.链表
链表是一系列节点组成的元素集合。每个节点包含两部分,数据域item和指向下一个节点的指针next。通过节点之间的互相连接,最终串连成一个链表。

创建链表有两种方法:头插法,尾插法
头插法:
# 头插法 class Node:#链表的类 def __init__(self,item): self.item=item self.next=None def create_linklist(li):#在head前面创建新的节点 head=Node(li[0]) for element in li[1:]: node =Node(element) node.next=head head=node return head def print_linklist(lk):#打印整个链表 while lk: print(lk.item,end=',') lk=lk.next lk=create_linklist([1,2,3,4]) print_linklist(lk)
尾插法:
# 尾插法 class Node:#链表的类 def __init__(self,item): self.item=item self.next=None def create_linklist_tail(li): head=Node(li[0]) tail=head #就一个元素,既是head,又是tail for element in li[1:]: node =Node(element) tail.next=node tail=node #结尾tail就指向自己刚建的这个节点 return head def print_linklist(lk):#打印整个链表 while lk: print(lk.item,end=',') lk=lk.next lk=create_linklist_tail([1,2,3,4,7,8,9]) print_linklist(lk)
完整链表代码:
class LinkList:#链表类(支持for循环,插入和查找节点) class Node:#链表里的节点 def __init__(self,item=None): self.item=item self.next=None class LinkListIterator: #迭代器,支持for循环(因为这个类有next方法) def __init__(self,node): #传进来的头节点,先定义一个node self.node=node def __next__(self): if self.node: #如果node不是空 cur_node=self.node self.node=cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self,iterable=None):#传个列表进来 self.head=None #头节点 self.tail=None #尾节点 if iterable: #如果有列表传进来 self.extend(iterable) def append(self,obj): #尾插法 s=LinkList.Node(obj) #做出个节点 if not self.head: #如果head为空 self.head=s self.tail=s else: #如果head不是空 self.tail.next=s self.tail=s def extend(self,iterable): #传进来列表,插到链表后面 for obj in iterable: self.append(obj) #将传进来的列表一个一个加到原来的链表后面 def find(self,obj):#查询某个节点是否存在 for n in self: if n==obj: return True else: return False def __iter__(self):#写迭代器,让链表支持for循环 return self.LinkListIterator(self.head) #把头节点传进去 def __repr__(self):#转换成字符串打印出来 return '<<' + ','.join(map(str,self))+'>>' #join-->把self里面每个元素都用逗号隔开 # return '<<' + ','.join(self) + '>>' 如果写成这样会报错,因为self里面全是int类型, # 而join要str类型,所以上面用map把self每一个元素都转成str类型,并且map自身就可以迭代 lk=LinkList([1,2,3,4,5,6]) print(lk) # 输出:<<1,2,3,4,5,6>> for i in lk: print(i) # 输出:1,2,3,4,5,6 print(lk.find(4)) #True print(lk.find(7)) #False
链表的插入:
复杂度:O(1)
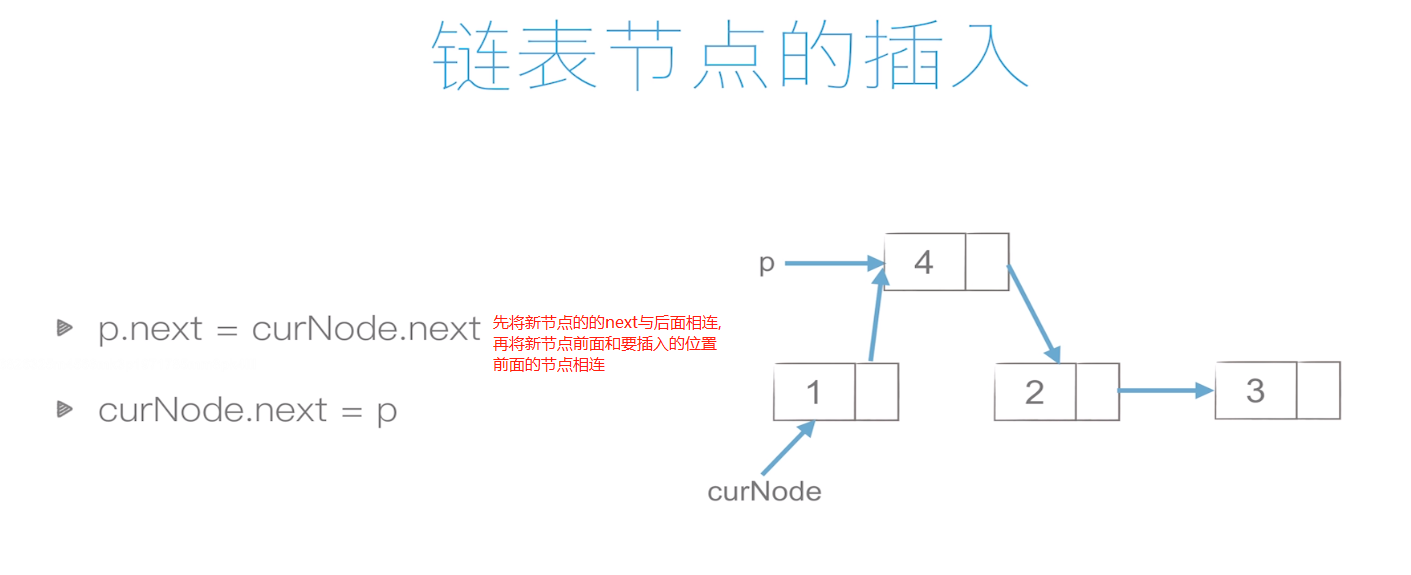
链表的删除:
复杂度:O(1)
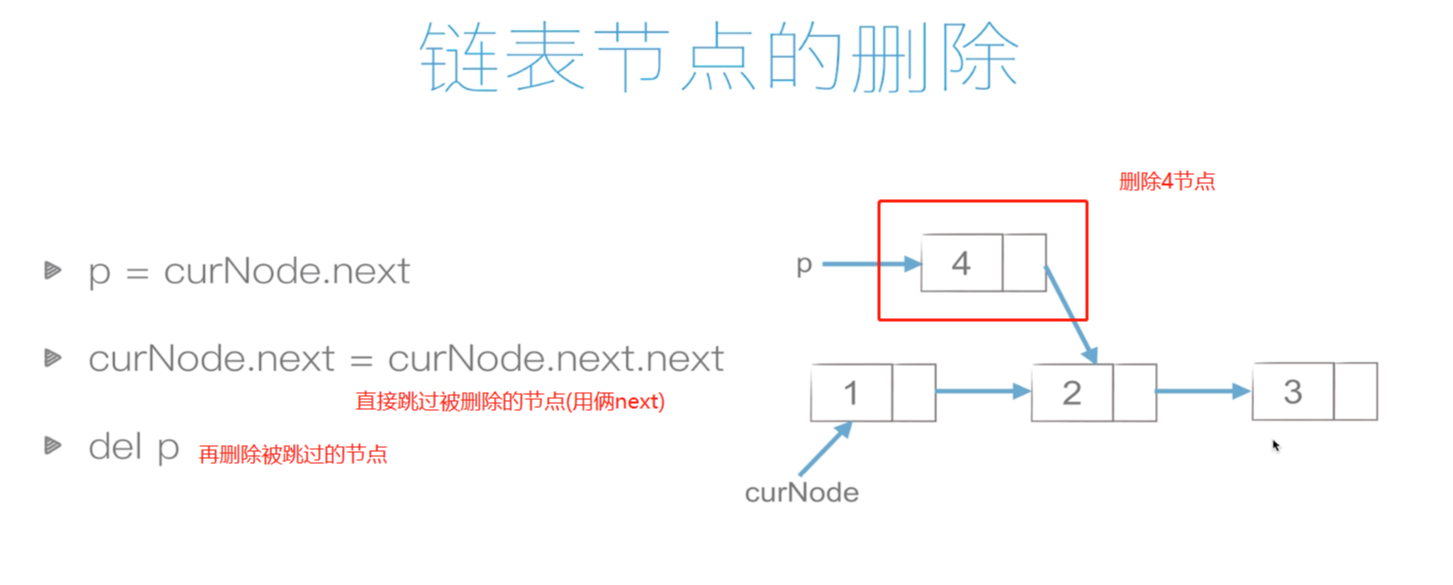
双向链表:
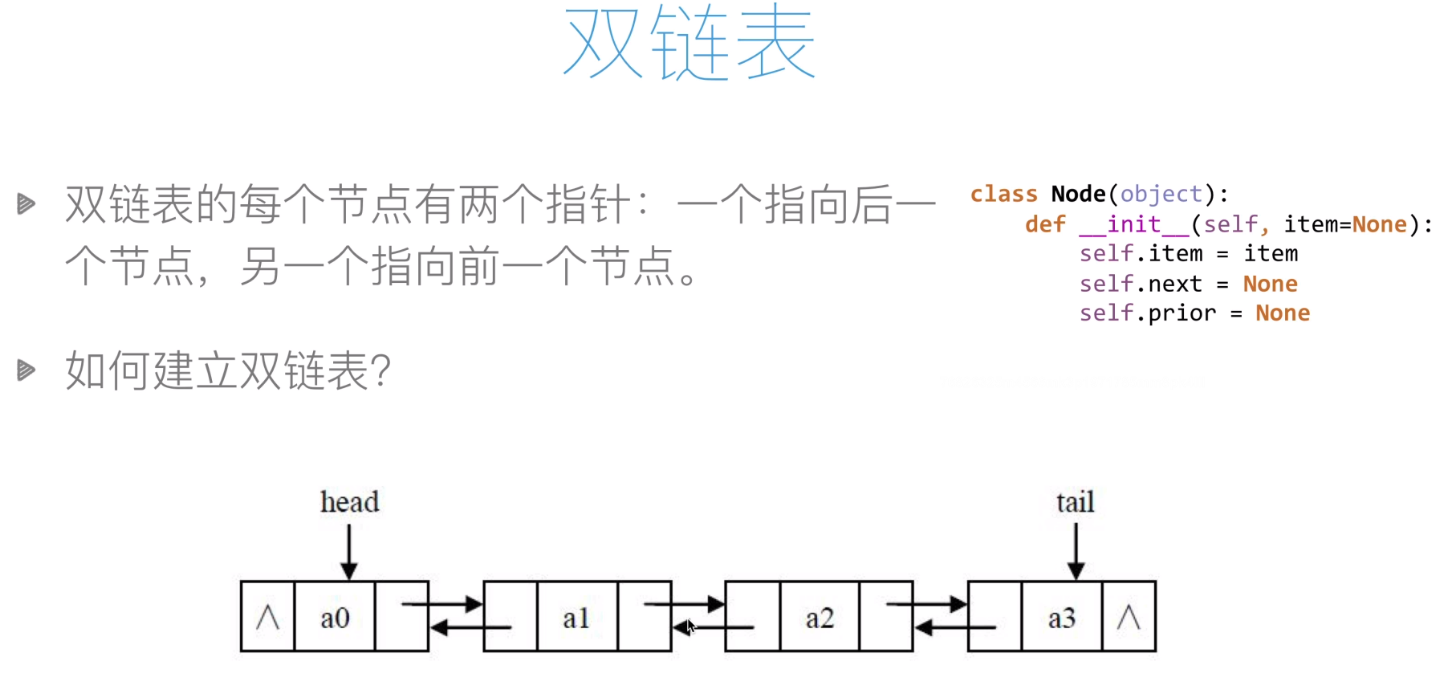
插入:
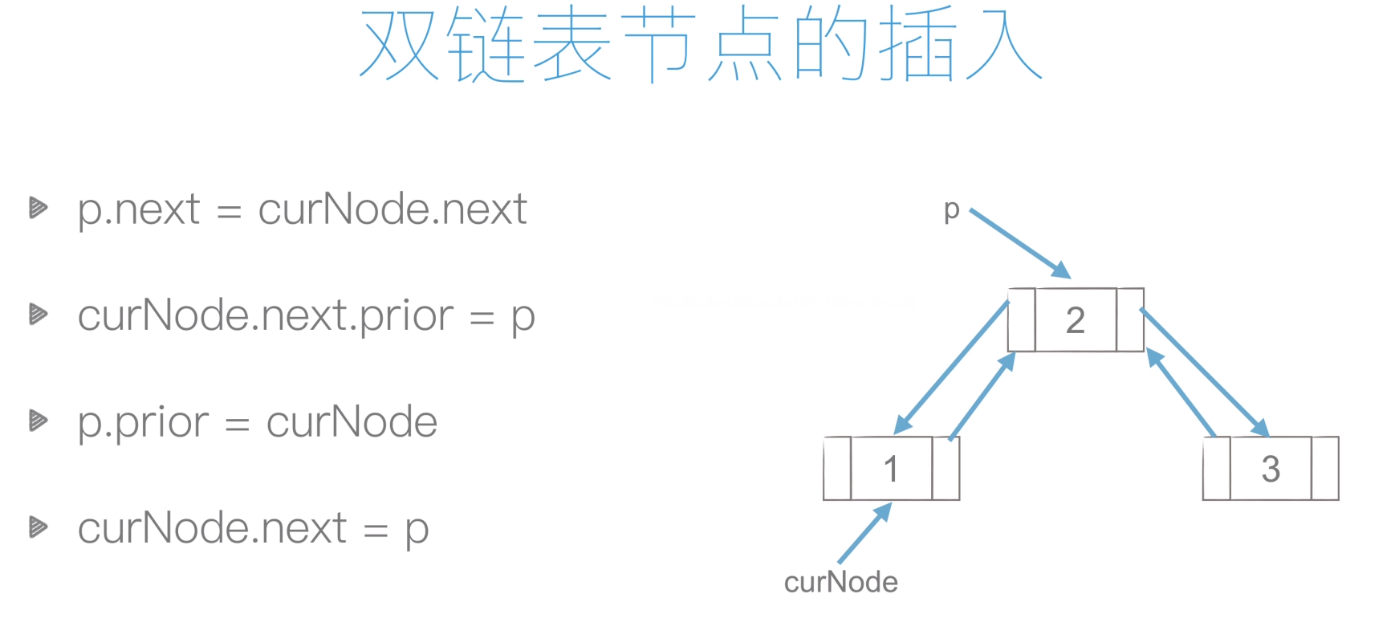
删除:

6.哈希表:
哈希表又叫散列表,是一种线性表的存储结构。
python中的字典和集合都是通过它来实现的。
哈希表是通过哈希函数来计算数据存储位置的数据结构。
哈希表是由一个直接寻址表和一个哈希函数组成。
哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
一般来说会支持:
①insert(key,value):插入键值对(key,value).
②get(key):如果存在键为key的键值对则返回其value,否则返回空值.
③delete(key):删除键为key的键值对.

哈希冲突:
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,这种情况叫做哈希冲突。

解决哈希冲突:
一、开放寻址法(不推荐):
如果哈希函数返回的位置已经有值,那就向后找新的空的位置来存放这个值。
①线性探查:如果位置m被占用,那就找m+1,m+2...
②二次勘探:如果位置m被占用,那就找m+1²,m-1²,m+2²,m-2²...
③二度哈希:有n个哈希函数,当第一个哈希函数h1发生冲突,就使用h2哈希函数,h3,h4...直到没冲突为止
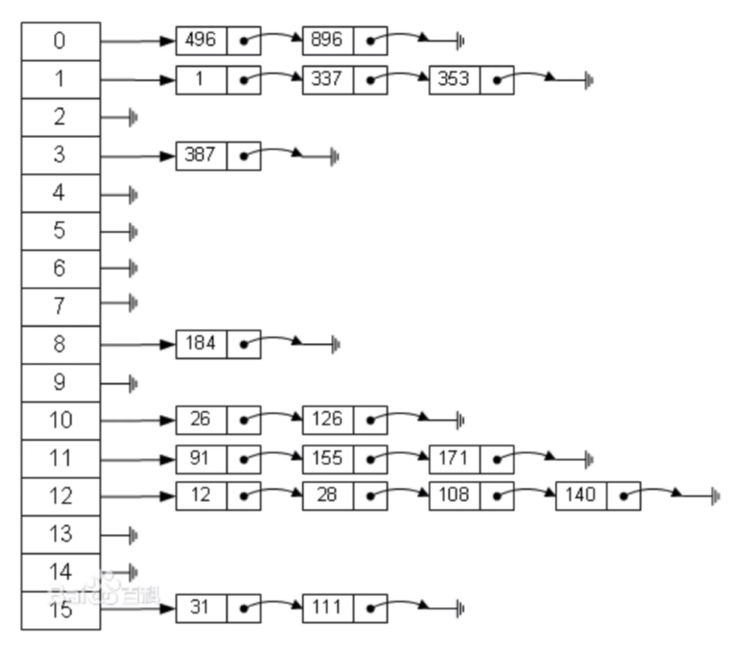
二、拉链法:
哈希表每个位置都连接一个链表,当发生冲突时,冲突的元素将被加到该位置链表的最后。
如图:
常见的哈希函数:
①除法哈希(比较常见):
h(k)=k%m (m是哈希表的长度)
②乘法哈希:
h(k)=floor(m*(A*key%1)) (floor向下取整,不会四舍五入,A是个小数,%1就是取整)
③全域哈希法:
ha,b(k)=((a*key) % p) % m (a,b=1,2,3,4,5….p-1) a和b是俩常数
用哈希表写个集合:
#集合:这里的功能有增和查,没有删除 class LinkList:#链表类 class Node:#链表里的节点 def __init__(self,item=None): self.item=item self.next=None class LinkListIterator: #迭代器,支持for循环(因为这个类有next方法) def __init__(self,node): #传进来的头节点,先定义一个node self.node=node def __next__(self): if self.node: #如果node不是空 cur_node=self.node self.node=cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self,iterable=None):#传个列表进来 self.head=None #头节点 self.tail=None #尾节点 if iterable: #如果有列表传进来 self.extend(iterable) def append(self,obj): #尾插法 s=LinkList.Node(obj) #做出个节点 if not self.head: #如果head为空 self.head=s self.tail=s else: #如果head不是空 self.tail.next=s self.tail=s def extend(self,iterable): #传进来列表,插到链表后面 for obj in iterable: self.append(obj) #将传进来的列表一个一个加到原来的链表后面 def find(self,obj):#查询某个节点是否存在 for n in self: if n==obj: return True else: return False def __iter__(self):#写迭代器,让链表支持for循环 return self.LinkListIterator(self.head) #把头节点传进去 def __repr__(self):#转换成字符串打印出来 return '<<' + ','.join(map(str,self))+'>>' #join-->把self里面每个元素都用逗号隔开 # return '<<' + ','.join(self) + '>>' 如果写成这样会报错,因为self里面全是int类型, # 而join要str类型,所以上面用map把self每一个元素都转成str类型,并且map自身就可以迭代 class HashTable:#哈希表--类似于集合的结构(内容不重复) def __init__(self,size=101):#建哈希表时,一起建链表(多个)放在每个索引的后面用来存值 self.size=size #size就是哈希表长度 self.T=[ LinkList() for i in range(self.size)] #LinkList()新建空链表,哈希表多长,就在里面新建多少个空链表 def h(self,k):#调用哈希函数,返回的是哈希表的索引 return k% self.size def find(self,k):#查找 i = self.h(k) return self.T[i].find(k)#这个find调用的是LinkList里面的find, # 而不是递归一直调用自己的find,这里返回True或者False def insert(self,k):#插入 i=self.h(k) if self.find(k):#如果里面找到了,那就不插入,这是集合 print("Duplicated Insert(表中存在,重复插入)") #重复插入 else: #如果没找到,那就插入进去 self.T[i].append(k) ht=HashTable() ht.insert(0) ht.insert(1) ht.insert(4) ht.insert(102)#1和102都在一个链表中 # ht.insert(0)#会告诉你重复插入 print(','.join(map(str,ht.T)))#打印一下整个哈希表 # 输出:<<0>>,<<1,102>>,<<>>,<<>>,<<4>>,<<>>,一共101个<<>>, # 每个<<>>都是一个链表,加起来就是整个哈希表 print(ht.find(102)) #True print(ht.find(6)) #False
哈希表应用:
①字典和集合
python中字典和集合用的是哈希表,他的查询要比列表速度快
字典的键映射成哈希表的下标(某种方法,将字符串变成数字用到下标上),而字典的值就存在哈希表中,这样查键就能找到值了
如果发生哈希冲突,就用拉链法或者开放寻址方法解决.
②md5
(128位,已经被清华的一个老师破解了)现在安全较重要的场合不要用md5加密

③文件的哈希值

④SHA2算法

⑤比特币
