kafka:基于发布/订阅的分布式消息系统、数据管道;最初用来记录活动数据--包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容和运营数据--服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。Kafka是一个分布式流数据系统,使用Zookeeper进行集群的管理。kafka自己做为Broker Server
- scala编写
- 水平扩展
- 高吞吐率
1、安装:
- 下载:去官网 https://kafka.apache.org/downloads 下载二机制版本 https://www.apache.org/dyn/closer.cgi?path=/kafka/1.1.0/kafka_2.12-1.1.0.tgz
直接网页下载或者命令行下载 wget -c http://mirrors.shu.edu.cn/apache/kafka/1.1.0/kafka_2.12-1.1.0.tgz
- 解压:把二机制包放到某个linux centos机器下解压tar -zxvf kafka_2.12-1.1.0.tgz
- 启动zk:kafka依赖zookeeper,需要先启动zookeeper。安装包自带zookeeper,可以直接启动,如果已经单独安装zookeeper的话,就不需要重启启动,如果需要再启动一个zookeeper,修改下zookeeper的配置文件,修改端口,不要造成端口冲突,zk的默认端口是2181。 启动命令:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties - 启动kafka:需要先修改kafka配置文件:修改 kafka-server 的配置文件 config/server.properties,修改其中的broker.id和log位置。然后启动kafak服务。启动命令:bin/kafka-server-start.sh config/server.properties ,kafka默认端口9092。后台启动:bin/kafka-server-start.sh -daemon config/server.properties。配置broker.id必须是一个整数,且不可以和其他的kafak代理节点的值重复,即每个kafka节点为一个broker,拥有唯一的id值。
broker.id=1
|
-
单机多BROKER 集群配置:新生成几个配置文件config/server1.properties、config/server2.properties。然后,修改里面的配置文件broker.id、 log.dir、 listeners分别指定不同的broker、日志文件位置、监听端口。然后分别使用这些配置文件启动即可。
2、使用:
-
创建 TOPIC:使用
kafka-topics.sh创建单分区单副本的 topic test:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看 topic 列表:
bin/kafka-topics.sh --list --zookeeper localhost:2181
|
-
产生消息:使用
kafka-console-producer.sh发送消息:bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
echo "The first record" | kafka-console-producer.sh --broker-list localhost:9092 --topic test-
消费消息:使用
kafka-console-consumer.sh接收消息并在终端打印:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
或者bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning将消息的key也输出kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning --property print.key=true --property key.separator=, - 查看consumer group列表,使用--list参数:bin/kafka-consumer-groups.sh --bootstrap-server host:9092 --list
查看特定consumer group 详情,使用--group与--describe参数
bin/kafka-consumer-groups.sh --bootstrap-server HOST:9292 --group YOUR_GROUP_ID --describe -
看指定topic上每个partition的offset,是用于查看指定topic上相应分区的消息数,并不是consumer消费的偏移量
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list host:9092 --topic topic
-
查看描述 TOPICS 信息
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
|
3、错误处理:Caused by: java.net.UnknownHostException: hostname: unknown error
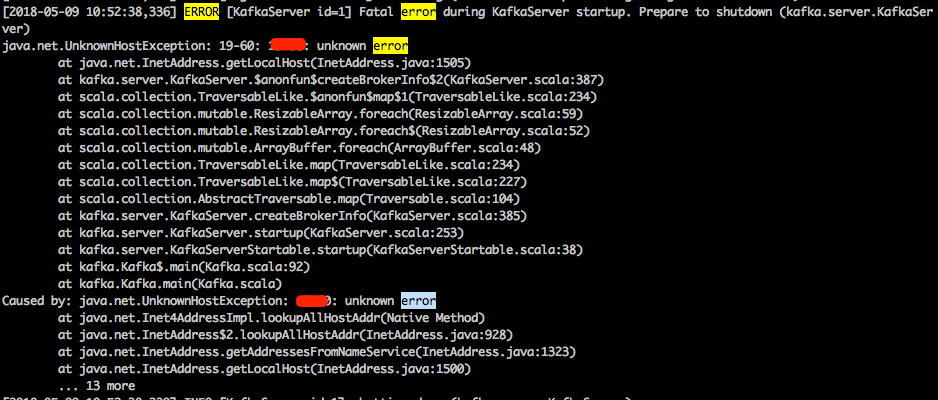
在/etc/hosts里添加下hostname和127.0.0.1的映射就可以了:比如 127.0.0.1 localhost
启动时错误:[2018-05-14 21:40:33,305] ERROR There was an error in one of the threads during logs loading: kafka.common.KafkaException: Found directory /home/admin/kafka_2.12-1.1.0/bin, 'bin' is not in the form of topic-partition or topic-partition.uniqueId-delete (if marked for deletion).
错误原因:server.properties里的配置log.dir路径不对
4、认证和加密
使用ssl加密和认证,这样使用kafka的时候,必须使用证书进行连接
https://blog.csdn.net/Regan_Hoo/article/details/78770058
https://apereo.github.io/cas/4.0.x/installation/JAAS-Authentication.html#jaas-configuration-file
python客户端使用方法
1、首先安装客户端:pip install kafka-python [--user] :https://github.com/dpkp/kafka-python
2、注意mac和部分linux使用kafka-pyhton,需要指定api_version,参考:https://github.com/dpkp/kafka-python/issues/1308 和 https://github.com/dpkp/kafka-python/pull/1411,正确用法:api_version可以先不指定,不行的话再指定
#! /usr/bin/env python import time
from kafka import KafkaProducer
producer=KafkaProducer(bootstrap_servers="10.5.9.6:9092")
i=0
while True:
ts = int(time.time()*1000)
producer.send("test",value=str(i),key=str(i),timestamp_ms=ts,partition= 0)
#第1个参数为 topic名称,必须指定
#key : 键,必须是字节字符串,可以不指定(但key和value必须指定1个),默认为None
#value : 值,必须是字节字符串,可以不指定(但key和value必须指定1个),默认为None
#partition : 指定发送的partition,由于kafka默认配置1个partition,固为0
producer.flush()
print i
i=i+1
time.sleep(1)
#! /usr/bin/env python from kafka import KafkaConsumer
consumer=KafkaConsumer("test",bootstrap_servers=["10.5.9.6:9092"])
# consumer=KafkaConsumer("test",group_id='test_group',bootstrap_servers=["10.5.9.6:9092"],consumer_timeout_ms=1000) # 为topic:test创建group:test_group
# topic可以写到KafkaConsumer的参数里,也可以是下面的写法。group_id:指定此消费者实例属于的组名;若不指定 consumer_timeout_ms,默认一直循环等待接收,若指定,则超时返回,不再等待.consumer_timeout_ms : 毫秒数
#consumer.subscribe(pattern= '^my.*') 使用正则表达式订阅多个topic
#consumer.subscribe(topics= ['my_topic', 'topic_1']) 订阅多个topic
for message in consumer:
print message
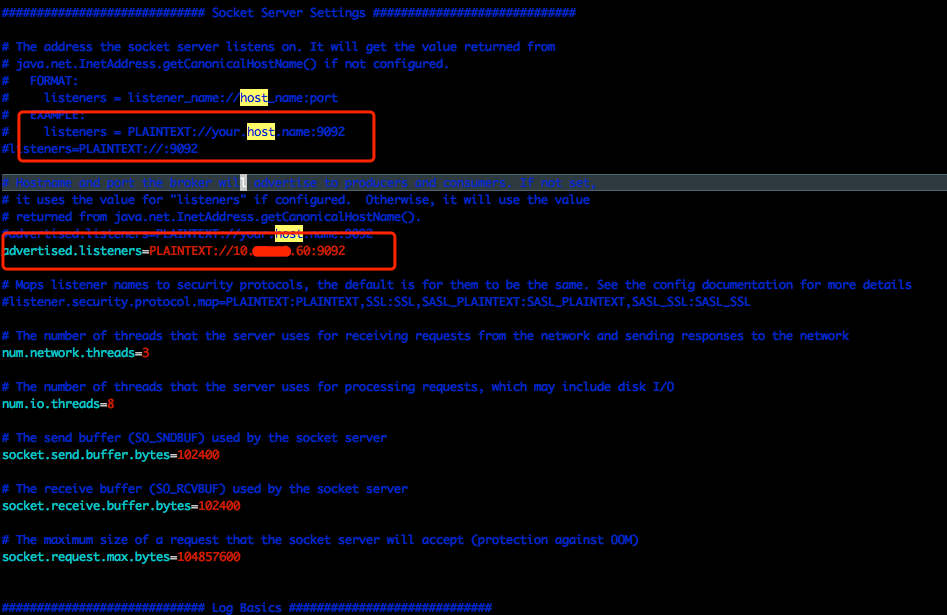
注意config/config/server.properties,一定要设置为本机的大网IP,不然其他机器的producer和consumer无法访问这个机器的broker,参见参考4的说明
Kafka架构
术语:
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。可以在一个机器上部署多个broker,也可以在不同的机器上部署多个broker。物理概念,指服务于Kafka的一个node。
- Topic:可以理解为是一个queue序列
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic 的 消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition。是Kafka下数据存储的基本单元。同一个topic的数据,会被分散的存储到多个partition中,这些partition可以在同一台机器上,也可以是在多台机器上。为了做到均匀分布,通常partition的数量通常是Broker Server数量的整数倍。
- Producer
负责发布消息到Kafka broker
- Consumer
消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则会创建默认的group)。同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
为了便于实现MQ中的多播,重复消费等引入的概念。如果ConsumerA以及ConsumerB同在一个UserGroup,那么ConsumerA消费的数据ConsumerB就无法消费了。
即:所有usergroup中的consumer使用一套offset。
- 什么是消费者组(Consumer Group)
consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。理解consumer group记住下面这三个特性就好了:
1)consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
2)group.id是一个字符串,唯一标识一个consumer group
3)consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group) -
Offset
Offset专指Partition以及User Group而言,记录某个user group在某个partiton中当前已经消费到达的位置。
- 查看group信息:test1234、test_group是主动创建的
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list

- group如何创建?cousumer消费时,为topic指定group名字,就会创建相应的group
- 一个topic可以同属于多个group,topic会广播给所有包含它的group
- 一个group可以包含多个topic,这个group会收到所有它包含的topic的信息
- 属于同一个group的多个客户端(或者线程、进程),其中只有一个可以收到相同topic的信息,其他收不到
- 默认从上次的最后一次消费继续消费(这样保证不会重复消费),也可以通过设置从头开始消费
- 一个topic中partition的数量,就是每个user group中消费该topic的最大并行度数量。
Python Kafka的几个客户端对比基准测试:https://www.ctolib.com/topics-103354.html
kafka-python文档地址:https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
使用参考:https://zhuanlan.zhihu.com/p/38330574
更多操作kafka的python三方包比较参考:https://github.com/muscledreamer/Kafka_Demo
查看Topic的分区和副本情况
命令:
bin/kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic test0
运行结果:
Topic:test0 PartitionCount:16 ReplicationFactor:3 Configs:
Topic: test0 Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 1,0,2
Topic: test0 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,0,2
Topic: test0 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 1,0,2
Topic: test0 Partition: 3 Leader: 1 Replicas: 1,2,0 Isr: 1,0,2
Topic: test0 Partition: 4 Leader: 2 Replicas: 2,0,1 Isr: 1,0,2
Topic: test0 Partition: 5 Leader: 0 Replicas: 0,1,2 Isr: 1,0,2
Topic: test0 Partition: 6 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test0 Partition: 7 Leader: 2 Replicas: 2,1,0 Isr: 1,0,2
Topic: test0 Partition: 8 Leader: 2 Replicas: 2,0,1 Isr: 0,1,2
Topic: test0 Partition: 9 Leader: 0 Replicas: 0,2,1 Isr: 0,1,2
Topic: test0 Partition: 10 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test0 Partition: 11 Leader: 2 Replicas: 2,1,0 Isr: 1,0,2
Topic: test0 Partition: 12 Leader: 0 Replicas: 0,2,1 Isr: 0,1,2
Topic: test0 Partition: 13 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test0 Partition: 14 Leader: 2 Replicas: 2,1,0 Isr: 1,0,2
Topic: test0 Partition: 15 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
结果分析:
第一行显示partitions的概况,列出了Topic名字,partition总数,存储这些partition的broker数
以下每一行都是其中一个partition的详细信息:
leader
是该partitons所在的所有broker中担任leader的broker id,每个broker都有可能成为leader
replicas
显示该partiton所有副本所在的broker列表,包括leader,不管该broker是否是存活,不管是否和leader保持了同步。
isr
in-sync replicas的简写,表示存活且副本都已同步的的broker集合,是replicas的子集
举例:
比如上面结果的第一行:Topic: test0 Partition:0 Leader: 0 Replicas: 0,2,1 Isr: 1,0,2
Partition: 0
该partition编号是0
Replicas: 0,2,1
代表partition0 在broker0,broker1,broker2上保存了副本
Isr: 1,0,2
代表broker0,broker1,broker2都存活而且目前都和leader保持同步
Leader: 0
代表保存在broker0,broker1,broker2上的这三个副本中,leader是broker0
leader负责读写,broker1、broker2负责从broker0同步信息,平时没他俩什么事
当producer发送一个消息时,producer自己会判断发送到哪个partiton上,如果发到了partition0上,消息会发到leader,也就是broker0上,broker0处理这个消息,broker1、broker2从broker0同步这个消息
如果这个broker0挂了,那么kafka会在Isr列表里剩下的broker1、broker2中选一个新的leader
Kafka入门之六:Kafka的Consumer实验:https://blog.yaodataking.com/2016/11/13/kafka-6/
参考:
1、http://www.54tianzhisheng.cn/2018/01/04/Kafka/
2、http://www.infoq.com/cn/articles/kafka-analysis-part-1
3、http://www.infoq.com/cn/profile/%E9%83%AD%E4%BF%8A
4、https://blog.csdn.net/cysdxy/article/details/52337364
5、https://www.jianshu.com/p/51a6789b9d39
6、https://www.jianshu.com/p/ede62642a438
7、http://windrocblog.sinaapp.com/?p=1860
8、https://blog.csdn.net/weixin_40596016/article/details/79562023
9、http://alexstocks.github.io/html/kafka.html