开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(MOLAP)能力以支持超大规模数据,能在亚秒内查询巨大的Hive表;
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
MR Hive
M(多维)OLAP连接分析处理的引擎
Hive--->Kylin--->Hbase
1. Kylin架构

第一部分:
Metadata(元数据)和Cube Build Engine构建引擎(做分析运算),离线-提前算-预计算
第二部分:对外查询(实时)输出:
REST Server(接收请求)-->
Query Engine(sql语法解析)
Routing(连接HBase)
需要调用使用的场景:
第三方App REST-API-->基于http协议
BI tools:Tableau..企业级商业智能-可视化界面-->基于jdbc、ODBC(windows/ linux)
2. Kylin工作原理
本质上是MOLAP(Multidimension On-Line Analysis Processing)Cube,也就是多维立方体分析;
Kylin的工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询:
1)指定数据模型,定义维度和度量;
2)预计算Cube,计算所有Cuboid并保存为物化视图;
预计算过程是Kylin从Hive中读取原始数据,按照我们选定的维度进行计算,并将结果集保存到Hbase中,默认的计算引擎为MapReduce,可以选择Spark作为计算引擎。一次build的结果,我们称为一个Segment。构建过程中会涉及多个Cuboid的创建,具体创建过程由kylin.cube.algorithm参数决定,参数值可选 auto,layer 和 inmem, 默认值为 auto,即 Kylin 会通过采集数据动态地选择一个算法 (layer or inmem),如果用户很了解 Kylin 和自身的数据、集群,可以直接设置喜欢的算法。
3)执行查询,读取Cuboid,运行,产生查询结果。
确定分析角度-即维度(观察数据的角度)
具体聚合运算:count, avg, sum-即度量(被聚合(观察)的统计值,也就是聚合运算的结果)
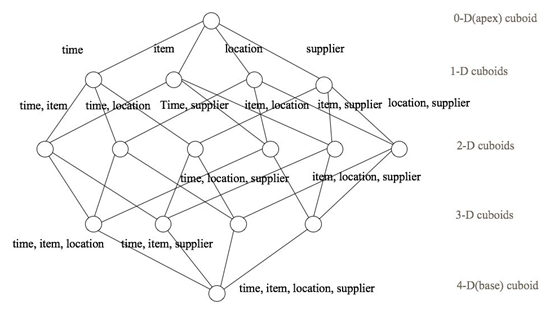
4个维度组合: abcd abc abc bcd ab cd ac bd a b c d 零维... n个维度---组合--->2^n个cuboid
一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成
每种维度组合--->cuboid
所有维度组合的cuboid作为一个整体---->cube(立方体)
核心算法
①分层算 MR--逐层构建算法(layer)

高维---->低维; 数据基于高维,递进过程
缺点:每层都有mr; 每层都要从hdfs读取,大量IO; 简单繁琐
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
②快速构建
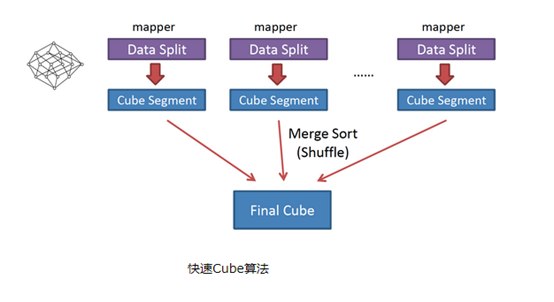
需要算所有维度,一次mr即可; 多个切片-->多个map数; 做所有keyboid运算; 所有map汇总及cube结果
省去mr资源调度;减少了io; map已经没重复的key,reducer只需对每个map去重减少了reducer的工作量;
与旧算法相比,快速算法主要有两点不同:
1) Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
2)一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
关于这两个算法麒麟会自动选择;
3. Kylin环境搭建
/etc/profile


#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #HIVE_HOME export HIVE_HOME=/opt/module/hive export PATH=$PATH:$HIVE_HOME/bin ##HBASE_HOME export HBASE_HOME=/opt/module/hbase-1.3.1 export PATH=$PATH:$HBASE_HOME/bin #KYLIN_HOME export KYLIN_HOME=/opt/module/kylin export PATH=$PATH:$KYLIN_HOME/bin
1)将apache-kylin-2.5.1-bin-hbase1x.tar.gz上传到Linux 2)解压apache-kylin-2.5.1-bin-hbase1x.tar.gz到/opt/module [kris@hadoop101 sorfware]$ tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /opt/module/ 注意:需要在/etc/profile文件中配置HADOOP_HOME,HIVE_HOME,HBASE_HOME并source使其生效。 3)启动 [kris@hadoop101 kylin]$ bin/kylin.sh start
启动Kylin之前要保证HDFS,YARN,ZK,HBASE相关进程是正常运行的。
http://hadoop101:7070/kylin 查看Web页面
用户名为:ADMIN,密码为:KYLIN(系统已填)
4. 创建项目
employee实事表才会参与真正运算,dept维表不参与
model模型分以下2种:
① 当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星形模型
星状模型是直接关联;
② 当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
雪花模型是主从间接关联;
创建分区表:
create table emp_partition(empno int, ename string, job string, mgr int, sal double, comm double, deptno int) partitioned by(hire_date string) row format delimited fields terminated by ' ';
动态分区应该手动开启:
set hive.exec.dynamic.partition.mode=nonstrict;
动态插入数据
insert into table emp_partition partition(hire_date) select empno, ename, job, mgr, sal, comm, deptno, hiredate from emp;
① 创建module项目名称:project_partition
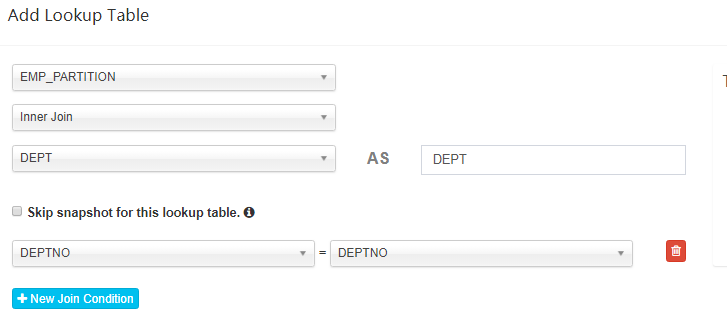
主表--FactTable: default.emp_partition
从表--Add Lookup Table:emp_partition inner join dept
维度--Select dimension columns:EMP_PARTITION-->job,mgr,hire_date ; DEPT-->dname
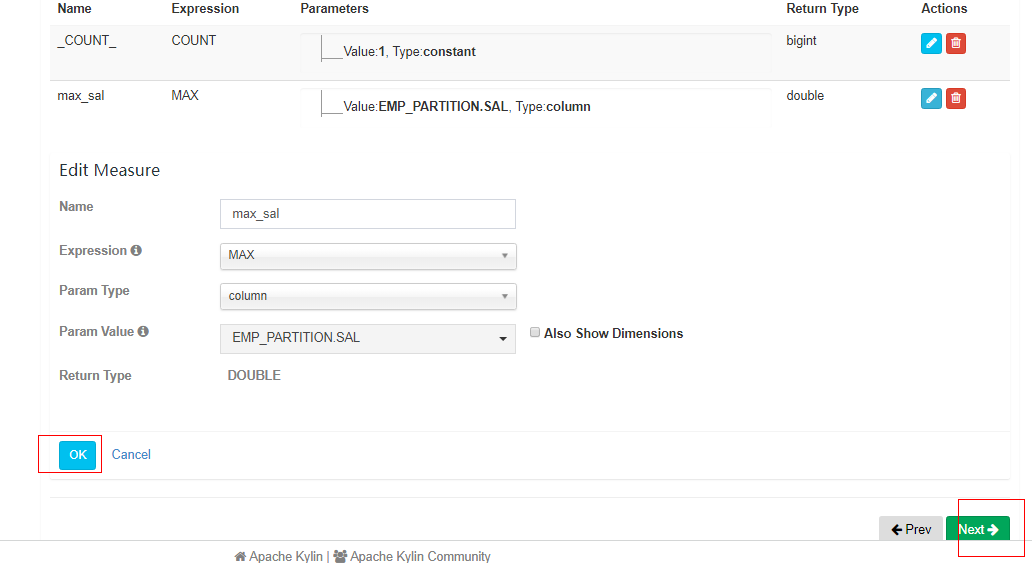
度量--Select measure columns: EMP_PARTITION--->sal
② 创建Cube
Cube Designer
合并
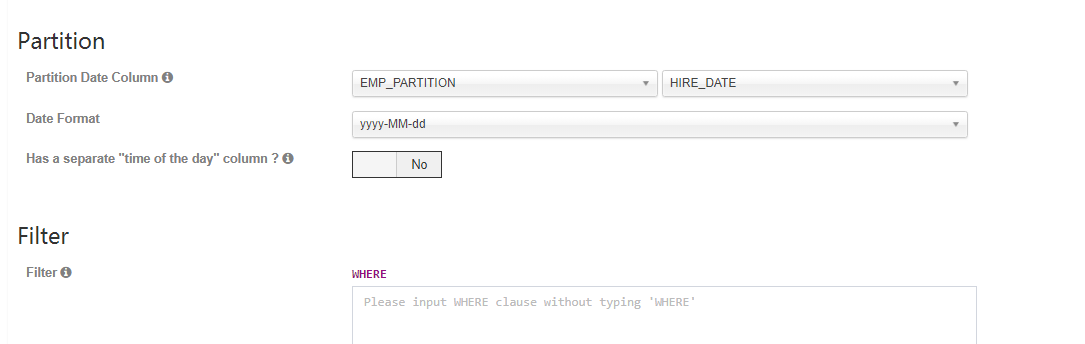
与动量cute做呼应,分区必须是日期;选分区表:hire_date

5. Kylin查询
在New Query中输入查询语句并Submit

数据图表展示及可以导出
6. 可视化
JDBC
新建项目并导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>2.5.1</version>
</dependency>
</dependencies>
public class TestKylin {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//kylin的JDBC驱动类
String Kylin_Driver = "org.apache.kylin.jdbc.Driver";
String Kylin_Url = "jdbc:kylin://hadoop101:7070/HelloWorld";
String Kylin_User = "ADMIN";
String Kylin_Password = "KYLIN";
Class.forName(Kylin_Driver); //①添加驱动信息
Connection connection = DriverManager.getConnection(Kylin_Url, Kylin_User, Kylin_Password);//②
//③预编译SQL
PreparedStatement preparedStatement = connection.prepareStatement("select job, count(*), sum(sal) from EMP inner join DEPT ON EMP.DEPTNO = DEPT.DEPTNO group by job");
ResultSet resultSet = preparedStatement.executeQuery(); //④执行查询
while (resultSet.next()){ //⑤遍历打印
String job = resultSet.getString(1);
int count = resultSet.getInt(2);
double sum_total = resultSet.getDouble(3);
System.out.println(job + " " + count + " " + sum_total);
}
}
}
可视化工具 Zepplin安装与启动
1)将zeppelin-0.8.0-bin-all.tgz上传至Linux 2)解压zeppelin-0.8.0-bin-all.tgz之/opt/module [kris@hadoop101 sorfware]$ tar -zxvf zeppelin-0.8.0-bin-all.tgz -C /opt/module/ 3)修改名称 [kris@hadoop101 module]$ mv zeppelin-0.8.0-bin-all/ zeppelin 4)启动 [kris@hadoop101 zeppelin]$ bin/zeppelin-daemon.sh start 可登录网页查看,web默认端口号为8080 http://hadoop101:8080



key横坐标;
values纵坐标
%kylin select job, dname, count(*), sum(sal) from EMP inner join DEPT ON EMP.DEPTNO = DEPT.DEPTNO group by job, dname;

7. Cube构建优化
在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化(即减少Cuboid的生成)。
找出问题Cube

Expansion Rate即膨胀率;
一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
1)Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多;
2)Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大;
3)存在比较占用空间的度量,例如Count Distinct,因此需要在Cuboid的每一行中都为其保存一个较大的寄存器,最坏的情况将会导致Cuboid中每一行都有数十KB,从而造成整个Cube的体积变大;
检查Cube中哪些Cuboid 最终被预计算了,我们称其为被物化(Materialized)的Cuboid。同时,这种方法还能给出每个Cuboid所占空间的估计值。由于该工具需要在对数据进行一定阶段的处理之后才能估算Cuboid的大小,因此一般来说只能在Cube构建完毕之后再使用该工具。
由于同一个Cube的不同Segment之间仅是输入数据不同,模型信息和优化策略都是共享的,所以不同Segment中哪些Cuboid被物化哪些没有被物化都是一样的。因此只要Cube中至少有一个Segment,那么就能使用如下的命令行工具去检查这个Cube中的Cuboid状态:
[kris@hadoop101 kylin]$ bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader cube_partition
Sampling percentage: 100
Mapper overlap ratio: 1.0
Mapper number: 1
Length of dimension DEFAULT.EMP_PARTITION.JOB is 1
Length of dimension DEFAULT.EMP_PARTITION.MGR is 1
Length of dimension DEFAULT.EMP_PARTITION.DEPTNO is 1
Length of dimension DEFAULT.EMP_PARTITION.HIRE_DATE is 1
|---- Cuboid 1111, est row: 14, est MB: 0
|---- Cuboid 0111, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 0011, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 0001, est row: 13, est MB: 0, shrink: 92.86%
|---- Cuboid 0010, est row: 3, est MB: 0, shrink: 21.43%
|---- Cuboid 0101, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 0100, est row: 7, est MB: 0, shrink: 50%
|---- Cuboid 0110, est row: 9, est MB: 0, shrink: 64.29%
|---- Cuboid 1011, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 1001, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 1000, est row: 5, est MB: 0, shrink: 35.71%
|---- Cuboid 1010, est row: 9, est MB: 0, shrink: 64.29%
|---- Cuboid 1101, est row: 14, est MB: 0, shrink: 100%
|---- Cuboid 1100, est row: 8, est MB: 0, shrink: 57.14%
|---- Cuboid 1110, est row: 10, est MB: 0, shrink: 71.43%
每个节点代表一个Cuboid,每个Cuboid都由一连串1或0的数字组成,如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度。
最高维度1111
3个维度0111
2维
收缩比例:
|---- Cuboid 0011, est row: 14, est MB: 0, shrink: 100%(相当于父维度0111是没有收缩的,应该去掉这个节点,它和0111一模一样)
|---- Cuboid 0001, est row: 13, est MB: 0, shrink: 92.86% (相对于它的父维度收缩了,基本上没收缩;减少的)
两个列分组更精细即父维度更精细,子维度相比于父维度应该差别更大,如果差别很小就应该砍掉;
砍的维度越多,Cuboid越少;
8. 构建增量cube
希望每次构建cube时,不用全量构建,即不用把所有原始hive表重新构建,而是把新增的hive数据构建一个segment即可。
见上创建项目:创建hive分区表--->module中指定分区列(--->cube增量构建
hive cube -->Segment -->Segment
-->Segment ... 全量构建(full-build) 增量构建() hive cube -->Segment1(2019-2-12) -->Segment2(2019-3-12)
由于hive中数据变更,kylin会去进行同步,同步一次叫一个segment,每次的segment就是一段一段;
cube关联着hive表,一个cube可能关联多次segment,关联一次就有一个segment
物化视图的概念
合并
手动合并
在cube中选择"build"的菜单位置,选择"merge"即可触发手动合并;
之后可以选择要合并的时间区间,提交任务即可
自动合并
通过在cube中设置阈值,让cube自动触发segment合并

自动合并(从大到小,如先看28天再看7天;7天合并1次,28天合并一次)做定期的合并
如果有时间跨度达到28天就合并1次;
例如每4天做1次构建,合并一次,做完第7次的构建之后,它和前6次的段就占满了28天,第7次时就占满了28天的间隔,则Segment合并一次;
当没有满足跨度达到28天,再判断有没有连续占满7天的,(它是会先检查大的,大的28天没有,如果7天满足了,就合并);每出现1次新的Segment就会去判断一次;
Retention Threshold中默认值为0,意思是,不丢弃任何segment;如改为20,保留最近20天的Segment,不在这个区间的就舍弃;
构建之前优化:砍掉 Cuboid
优化核心即剪掉没必要的cuboid,把它的数量减少点就会更快
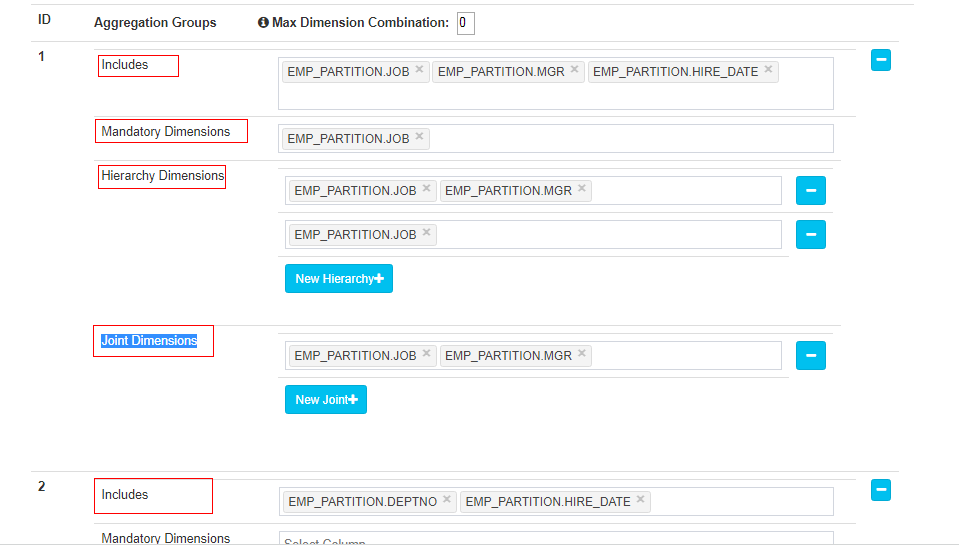
① 聚合组Aggregation Groups

默认的包含所有的维度,即最全的立方体; 聚合组之间不交叉
如果用户仅仅关注维度 AB 组合和维度 CD 组合 那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD
② 层级维度Hierarchy Dimensions:
层级之间是包含关系
保留比较全的维度,其他的子节点就砍掉;
层级维度是在聚合组内选的;cube的构建是以聚合组为单位的,有几个聚合组就决定了所有Cuboid组合的程度
只有聚合组中的维度才会进行组合;根据层级设置,立方体会去剪掉多余的Cuboid;保留全的维度,剪掉子维度;
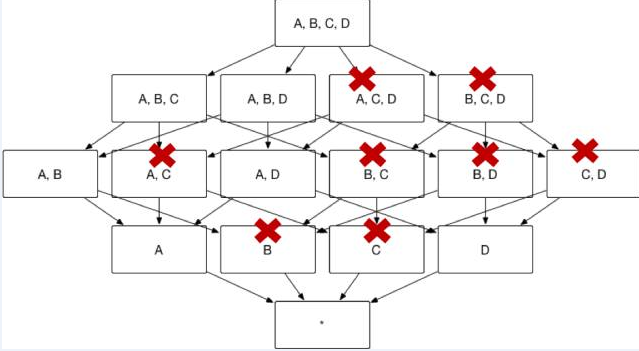
用户选择的维度中常常会出现具有层级关系的维度。例如对于国家(country)、省份(province)和城市(city)这三个维度,从上而下来说国家/省份/城市之间分别是一对多的关系。
也就是说,用户对于这三个维度的查询可以归类为以下三类: 1. group by country 2. group by country, province(等同于group by province) 3. group by country, province, city(等同于 group by city) 如果ABCD 四个维度中ABC这三个被设置为层级维度, abc=ac=bc 则 abcd=acd=bcd,所以剪掉acd,bcd,保留abcd足以, 则最终生成的cube:
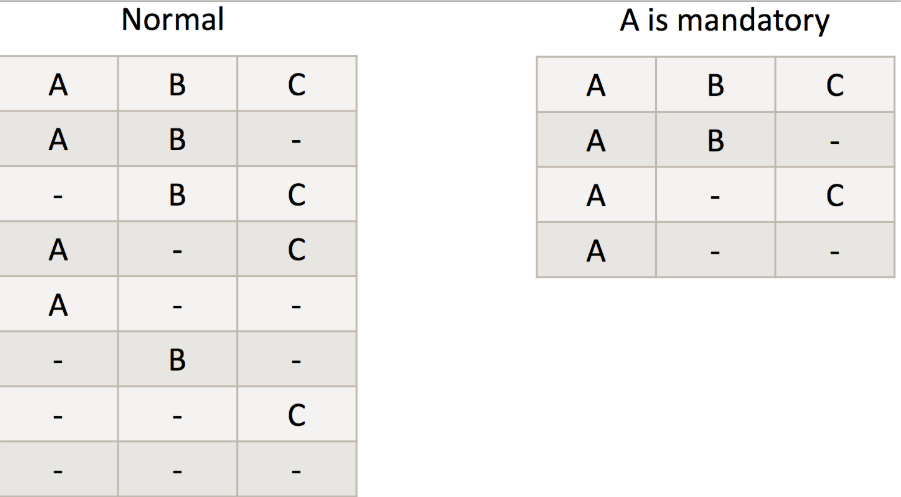
③ 强制维度Mandatory Dimensions
在所有的维度组合内都有有这个强制维度
假设共有3个维度:A B C
-
一般情况下的维度组合为如下左图,共有8中可能,则有8次运算;
-
但如果正真会被用到的运算中都包含A维度,并把A设置为前置维度,则维度组合为如下右图,
共需4次运算;
在后续的查询中是否每次group by都会包含某维度
④ 联合维度Joint Dimensions:
A B C为联合维度,3个维度在一块才有意义;
A B C为联合维度,则要么都在,要么都不在,如下图,最终的Cuboid 数目从 16 减少到 4。

⑤ 衍生(推导)维度:
Fact表:A(a,b,c)
Lookup表:B(x,y,z)
如果维度c中,每种情况都唯一对应一种 x,y。即 abc==abxy,或者说所有xy的组合都可以替换为c。
所以可以将 x,y 设置为derived维度,可以减少cuboid的个数。
在查询时:select xx from xx group by x,y;会被kylin等价转换为select ... group by c;
A
B C
衍生(推导)维度必须来自从表(维表)
强映射
normal维度来自主表
derived从表的维度默认会被外键(与主键一一对应)推导出来;如果在某种情况下不合理可以改edit改为normal
推导维度没必要选聚合组,默认也不会让我们选,;