测试之集群性能测试
1 DFSIO测试
在Hadoop中包含很多的基准测试,用来验证集群的HDFS是不是设置合理,性能是不是达到预期,DFSIO是Hadoop的一个基准测试工具,被用来分析集群HDFS的I/O性能。
DFSIO后台执行MapReduce框架,其中Map任务以并行方式读写文件,Reduce任务用来收集和汇总性能数字。可以通过这个基准测试对比吞吐量、IO速率的结果以及整个磁盘的原始速度,来确定你的集群是否得到了期待的性能。另外,可以通过这些测试中指标的严重偏差发现集群中一个或多个问题节点,结合监控系统一起使用能够更好的定位Hadoop集群的瓶颈所在。
2 写性能测试
执行以下命令来运行HDFS写性能测试,其中参数-nrFiles指定了测试中要写的文件数目,参数-fileSize指明了写入每个文件的大小单位是MB。该命令会在HDFS上产生一系列的文件存放在HDFS的/benchmarks/TestDFSIO文件夹下。
请注意,由于部署了Kerberos,hdfs不允许任意读写,此时需要kinit某个用户,然后指定TestDFSIO的写目录,指定方法为:
添加参数-D test.build.data=/user/用户名/benchmark
由于我们yarn配置了允许的用户:

所以用以上用户来测试,这里我选择hive用户。
[root@hadoop101 ~]# kinit hive
[root@hadoop101 ~]# hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.12.1-tests.jar TestDFSIO -D test.build.data=/user/hive/benchmark -write -nrFiles 100 -fileSize 10
====没有配置,我们则用Hdfs用户来测试:
[hdfs@hadoop101 ~]$ hadoop jar /home/kris/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.2-tests.jar TestDFSIO -write -nrFiles 100 -fileSize 10
20/04/21 22:44:58 INFO fs.TestDFSIO: TestDFSIO.1.7
20/04/21 22:44:58 INFO fs.TestDFSIO: nrFiles = 100
20/04/21 22:44:58 INFO fs.TestDFSIO: nrBytes (MB) = 10.0
20/04/21 22:44:58 INFO fs.TestDFSIO: bufferSize = 1000000
20/04/21 22:44:58 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
20/04/21 22:44:59 INFO fs.TestDFSIO: creating control file: 10485760 bytes, 100 files
20/04/21 22:45:01 INFO fs.TestDFSIO: created control files for: 100 files
20/04/21 22:45:01 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 22:45:01 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 22:45:01 INFO mapred.FileInputFormat: Total input paths to process : 100
20/04/21 22:45:01 INFO mapreduce.JobSubmitter: number of splits:100
20/04/21 22:45:01 INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
20/04/21 22:45:01 INFO Configuration.deprecation: dfs.https.address is deprecated. Instead, use dfs.namenode.https-address
20/04/21 22:45:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1586707133037_8119
20/04/21 22:45:02 INFO impl.YarnClientImpl: Submitted application application_1586707133037_8119
20/04/21 22:45:02 INFO mapreduce.Job: The url to track the job: http://el-hadoop-3:8088/proxy/application_1586707133037_8119/
20/04/21 22:45:02 INFO mapreduce.Job: Running job: job_1586707133037_8119
20/04/21 22:45:08 INFO mapreduce.Job: Job job_1586707133037_8119 running in uber mode : false
20/04/21 22:45:08 INFO mapreduce.Job: map 0% reduce 0%
20/04/21 22:45:16 INFO mapreduce.Job: map 2% reduce 0%
20/04/21 22:45:17 INFO mapreduce.Job: map 7% reduce 0%
...
File Input Format Counters
Bytes Read=11290
File Output Format Counters
Bytes Written=81
20/04/21 22:46:25 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
20/04/21 22:46:25 INFO fs.TestDFSIO: Date & time: Tue Apr 21 22:46:25 CST 2020
20/04/21 22:46:25 INFO fs.TestDFSIO: Number of files: 100
20/04/21 22:46:25 INFO fs.TestDFSIO: Total MBytes processed: 1000.0
20/04/21 22:46:25 INFO fs.TestDFSIO: Throughput mb/sec: 16.99004383431309
20/04/21 22:46:25 INFO fs.TestDFSIO: Average IO rate mb/sec: 19.468568801879883
20/04/21 22:46:25 INFO fs.TestDFSIO: IO rate std deviation: 9.590634021553296
20/04/21 22:46:25 INFO fs.TestDFSIO: Test exec time sec: 83.914
20/04/21 22:46:25 INFO fs.TestDFSIO:
读性能测试
性能基准测试针对HDFS的读操作进行,读操作将用到第一步的写操作,因此写操作必须在读操作之前执行
[hdfs@hadoop101 ~]$ hadoop jar /home/kris/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.2-tests.jar TestDFSIO -read -nrFiles 100 -fileSize 10
20/04/21 22:49:25 INFO fs.TestDFSIO: TestDFSIO.1.7
20/04/21 22:49:25 INFO fs.TestDFSIO: nrFiles = 100
20/04/21 22:49:25 INFO fs.TestDFSIO: nrBytes (MB) = 10.0
20/04/21 22:49:25 INFO fs.TestDFSIO: bufferSize = 1000000
20/04/21 22:49:25 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
20/04/21 22:49:26 INFO fs.TestDFSIO: creating control file: 10485760 bytes, 100 files
20/04/21 22:49:29 INFO fs.TestDFSIO: created control files for: 100 files
20/04/21 22:49:29 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 22:49:29 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 22:49:29 INFO mapred.FileInputFormat: Total input paths to process : 100
20/04/21 22:49:29 INFO mapreduce.JobSubmitter: number of splits:100
20/04/21 22:49:29 INFO Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
20/04/21 22:49:29 INFO Configuration.deprecation: dfs.https.address is deprecated. Instead, use dfs.namenode.https-address
...
File Input Format Counters
Bytes Read=11290
File Output Format Counters
Bytes Written=84
20/04/21 22:50:46 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
20/04/21 22:50:46 INFO fs.TestDFSIO: Date & time: Tue Apr 21 22:50:46 CST 2020
20/04/21 22:50:46 INFO fs.TestDFSIO: Number of files: 100
20/04/21 22:50:46 INFO fs.TestDFSIO: Total MBytes processed: 1000.0
20/04/21 22:50:46 INFO fs.TestDFSIO: Throughput mb/sec: 217.10811984368215
20/04/21 22:50:46 INFO fs.TestDFSIO: Average IO rate mb/sec: 288.4814147949219
20/04/21 22:50:46 INFO fs.TestDFSIO: IO rate std deviation: 131.65626363914566
20/04/21 22:50:46 INFO fs.TestDFSIO: Test exec time sec: 77.665
20/04/21 22:50:46 INFO fs.TestDFSIO:
清理测试数据
[hdfs@el-hadoop101 ~]$ hadoop jar /home/kris/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.2-tests.jar TestDFSIO -clean
20/04/21 22:52:32 INFO fs.TestDFSIO: TestDFSIO.1.7
20/04/21 22:52:32 INFO fs.TestDFSIO: nrFiles = 1
20/04/21 22:52:32 INFO fs.TestDFSIO: nrBytes (MB) = 1.0
20/04/21 22:52:32 INFO fs.TestDFSIO: bufferSize = 1000000
20/04/21 22:52:32 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
20/04/21 22:52:33 INFO fs.TestDFSIO: Cleaning up test files
测试参考
在某一集群运行此命令,此集群配置10个datanode和3个namenode,每个节点采用10块2T硬盘,128G内存,32核CPU,采用双千兆网口,结果如下:
|
序号 |
操作 |
文件数目 |
文件大小 |
吞吐量(mb/sec) |
平均IO速率(mb/sec) |
IO速率标准差 |
消耗时间(sec) |
|
1 |
写 |
100 |
1000 |
31.01 |
134.33 |
285.7 |
74.52 |
|
2 |
写 |
1000 |
100 |
79.53 |
129.08 |
119.17 |
116 |
|
3 |
写 |
1000 |
1000 |
17.59 |
34.45 |
65.44 |
431.6 |
|
4 |
读 |
10 |
100 |
58.63 |
64.07 |
20.79 |
34.05 |
|
5 |
读 |
1000 |
100 |
8.07 |
10.49 |
6.33 |
104.78 |
|
6 |
读 |
1000 |
1000 |
5.64 |
6.13 |
1.84 |
1220.84 |
TeraSort测试
Hadoop的TeraSort是一个常用的测试,目的是利用MapReduce来尽可能快的对数据进行排序。TeraSort使用MapReduce框架通过分区操作将Map过程中的结果输出到Reduce任务,确保整体排序的顺序。TeraSort测试可以很好的对MapReduce框架的每个过程进行压力测试,为调优和配置Hadoop集群提供一个合理的参考。
生成测试数据
在进行TeraSort测试之前的一个准备过程就是数据的产生,可以使用teragen命令来生成TeraSort测试输入的数据。teragen命令的第一个参数是记录的数目,第二个参数是生成数据的HDFS目录。下面这个命令在HDFS的terasort-input目录中生成1GB的数据,由1千万条记录组成。
[root@hadoop101 ~]#
time hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 10000000 /user/hive/terasort-input
[hdfs@hadoop101 ~]$ time hadoop jar /home/hopson/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 10000000 /user/hive/terasort-input
20/04/21 22:57:23 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 22:57:24 INFO terasort.TeraGen: Generating 10000000 using 2
20/04/21 22:57:24 INFO mapreduce.JobSubmitter: number of splits:2
20/04/21 22:57:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1586707133037_8121
20/04/21 22:57:24 INFO impl.YarnClientImpl: Submitted application application_1586707133037_8121
20/04/21 22:57:24 INFO mapreduce.Job: The url to track the job: http://el-hadoop-3:8088/proxy/application_1586707133037_8121/
20/04/21 22:57:24 INFO mapreduce.Job: Running job: job_1586707133037_8121
..
FILE: Number of write operations=0
HDFS: Number of bytes read=167
HDFS: Number of bytes written=1000000000
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=2
Other local map tasks=2
Total time spent by all maps in occupied slots (ms)=23479
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=23479
Total vcore-milliseconds taken by all map tasks=23479
Total megabyte-milliseconds taken by all map tasks=24042496
Map-Reduce Framework
Map input records=10000000
Map output records=10000000
Input split bytes=167
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=319
CPU time spent (ms)=19430
Physical memory (bytes) snapshot=717750272
Virtual memory (bytes) snapshot=5582888960
Total committed heap usage (bytes)=910163968
org.apache.hadoop.examples.terasort.TeraGen$Counters
CHECKSUM=21472776955442690
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=1000000000
real 0m23.727s
user 0m6.806s
sys 0m0.411s
执行测试
对于TeraSort第一个参数是HDFS上输入文件的路径,第二个参数是HDFS上输出结果的路径。
[root@hadoop101 ~]#
time hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort /user/hive/terasort-input /user/hive/terasort-ouput
[hdfs@hadoop101 ~]$ time hadoop jar /home/hopson/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort /user/hive/terasort-input /user/hive/terasort-ouput
20/04/21 23:02:08 INFO terasort.TeraSort: starting
20/04/21 23:02:10 INFO input.FileInputFormat: Total input paths to process : 2
Spent 128ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
Computing input splits took 131ms
Sampling 8 splits of 8
Making 4 from 100000 sampled records
Computing parititions took 867ms
Spent 1000ms computing partitions
..
HDFS: Number of bytes read=1000001008
HDFS: Number of bytes written=1000000000
HDFS: Number of read operations=36
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
Job Counters
Launched map tasks=8
Launched reduce tasks=4
Data-local map tasks=8
Total time spent by all maps in occupied slots (ms)=88911
Total time spent by all reduces in occupied slots (ms)=47828
Total time spent by all map tasks (ms)=88911
Total time spent by all reduce tasks (ms)=47828
Total vcore-milliseconds taken by all map tasks=88911
Total vcore-milliseconds taken by all reduce tasks=47828
Total megabyte-milliseconds taken by all map tasks=91044864
Total megabyte-milliseconds taken by all reduce tasks=48975872
Map-Reduce Framework
Map input records=10000000
Map output records=10000000
Map output bytes=1020000000
Map output materialized bytes=436911769
Input split bytes=1008
Combine input records=0
Combine output records=0
Reduce input groups=10000000
Reduce shuffle bytes=436911769
Reduce input records=10000000
Reduce output records=10000000
Spilled Records=20000000
Shuffled Maps =32
Failed Shuffles=0
Merged Map outputs=32
GC time elapsed (ms)=4132
CPU time spent (ms)=101330
Physical memory (bytes) snapshot=7406276608
Virtual memory (bytes) snapshot=33618665472
Total committed heap usage (bytes)=8776056832
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1000000000
File Output Format Counters
Bytes Written=1000000000
20/04/21 23:02:49 INFO terasort.TeraSort: done
real 0m42.053s
user 0m8.690s
sys 0m0.413s
验证
验证TeraSort基准测试程序结果的正确性,可以使用teravalidate命令来执行。第一个参数是排序的结果集的HDFS上的位置。第二个参数是验证结果集正确性的报告存放位置。
[root@hadoop101 ~]#
time hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teravalidate /user/hive/terasort-ouput /user/hive/terasort-validate
[hdfs@hadoop101 ~]$ time hadoop jar /home/kris/apps/usr/webserver/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teravalidate /user/hive/terasort-ouput /user/hive/terasort-validate
20/04/21 23:05:20 INFO client.RMProxy: Connecting to ResourceManager at el-hadoop-3/172.26.0.109:8032
20/04/21 23:05:20 INFO input.FileInputFormat: Total input paths to process : 4
Spent 20ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
20/04/21 23:05:20 INFO mapreduce.JobSubmitter: number of splits:4
...
20/04/21 23:05:43 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=256
FILE: Number of bytes written=746005
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1000000504
HDFS: Number of bytes written=24
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=4
Launched reduce tasks=1
Data-local map tasks=1
Rack-local map tasks=3
Total time spent by all maps in occupied slots (ms)=26512
Total time spent by all reduces in occupied slots (ms)=2701
Total time spent by all map tasks (ms)=26512
Total time spent by all reduce tasks (ms)=2701
Total vcore-milliseconds taken by all map tasks=26512
Total vcore-milliseconds taken by all reduce tasks=2701
Total megabyte-milliseconds taken by all map tasks=27148288
Total megabyte-milliseconds taken by all reduce tasks=2765824
Map-Reduce Framework
Map input records=10000000
Map output records=12
Map output bytes=328
Map output materialized bytes=384
Input split bytes=504
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=384
Reduce input records=12
Reduce output records=1
Spilled Records=24
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=495
CPU time spent (ms)=16210
Physical memory (bytes) snapshot=2590765056
Virtual memory (bytes) snapshot=13983645696
Total committed heap usage (bytes)=3243245568
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1000000000
File Output Format Counters
Bytes Written=24
real 0m25.183s
user 0m7.004s
sys 0m0.394s
[hdfs@el-hadoop101 ~]$hadoop fs -cat /user/hive/terasort-validate/part-r-00000
checksum 4c49607ac53602
该文件有内容,说明结果是有序的。
测试参考
在某一集群运行此命令,此集群配置10个datanode和3个namenode,每个节点采用10块2T硬盘,128G内存,32核CPU,结果如下:
TeraSort命令耗时46.553s
YARN动态资源池
CDH 集成了 YARN 组件,提供了动态资源隔离能力,并对内存资源和 CPU 资源采用了不同的资源隔离方案。CM 提供了可视化界面来配置动态资源池,同时支持计划模式,对于指定类型的时间使用特定的资源管理策略,能有效的管理高峰在线业务期以及高峰离线计算期的不同资源负载管理矛盾。
当前 YARN 支持内存和 CPU 两种资源类型的管理和分配。 对于内存资源是限制性资源, 应用程序到达内存限制, 会发生 OOM, 就会被杀死, 因此内存直接决定应用程序的运行。CPU 资源一般用 Cgroups 进行资源控制, 内存资源隔离除 Cgroups 之外提供了另外一个更灵活的方案,就是线程监控方案,以获取更加灵活的资源控制效果。默认情况下 YARN 采用线程监控的方案控制内存使用,每个 NodeManager 会启动一个额外监控线程监控每个 container 内存资源使用量,一旦发现它超过约定的资源量,则会将其杀死。
在 YARN 中, 用户以队列的形式组织, 每个用户可属于一个或多个队列, 且只能向这些队列中提交 application。 每个队列被划分了一定比例的资源。 用户提交应用程序时, 可以指定每个任务需要的虚拟 CPU 个数以及内存要求。
本章中仅演示功能,可以按照实际情况调整。
前期配置
1)确认开启HDFS权限检查 (默认是开启的)

2)启用 ResourceManager ACL
在YARN中搜索acl,其中yarn.acl.enable默认值为true。而对于yarn.admin.acl默认值为*,意味着所有人都可以提交任务、管理已提交 (比如取消kill) 的任务。格式为”以逗号分隔的用户列表+空格+以逗号分隔的组列表”,例如”user1,user2 group1,group2”。如果只有组信息,需要在最前端加入一个空格,例如” group1,group2”。另外特别需要注意的是需要将”yarn”加入到用户列表中,默认安装CDH后,有关YARN服务的命令会以yarn用户的身份进行运行,若yarn不设置于yarn.admin.acl中,可能出现权限相关的错误 (例如刷新动态资源池)。
下图中配置了yarn用户和admins用户组作为管理员。

3)关闭未声明资源池的自动生成
默认情况下,允许未声明的池是选中的,需要关闭,否则如果用户指定一个尚未声明的资源池,比如prod,YARN将会自动生成一个prod资源池。
配置文件修改后需要重新启动YARN服务,重新部署客户端配置。


4)配置不指定特定的queue时使用default queue
默认情况下,使用默认队列时的 Fair Scheduler 用户是选中的,意味着如果用户提交任务时不指定特定的queue,就使用以用户命名的queue。
搜索:yarn.scheduler.fair.user,将其取消

资源池设置
1)点击群集-动态资源池配置进入动态资源池的设置

2)访问动态资源池管理页面
此界面展示了当前资源池的分配情况,默认情况下,只有一个资源池root.default。但是如果在本文开头的前期配置之前执行了任务,yarn会自动建立users资源池。
权重 (weight) 定义了两个资源池资源分配的比例。如将users资源池设置权重为4而default的权重为1,那么集群资源的80%会被分配给users资源池。注意,这里提到的资源分配不是一个静态的概念,例如当前资源池users中没有任何任务在运行,那么资源池default是允许使用超过20%的集群资源。
点击资源池对应的编辑按钮,如编辑users,请注意,users可以使用与root相同的ACL配置,也可以使用不同的配置。

3)在Resource Limits栏, 设置资源池权重,资源约束等

4)在计划策略栏,设置资源池users的调度算法,一般使用默认的DRF

5)在提交访问控制(Submission Access Control)栏,设置哪些用户或组可以向该资源池提交任务

6)在管理访问控制 (Administration Access Control) 栏设置哪些用户或组可以对资源池中的任务进行管理

创建资源池
点击创建资源池可以创建一个新的资源池,可以参照上文的配置方法配置新建立的资源池的属性

可以为每个资源池创建子池。

YARN任务放置规则配置
点击放置规则,选择创建规则,进入配置选项
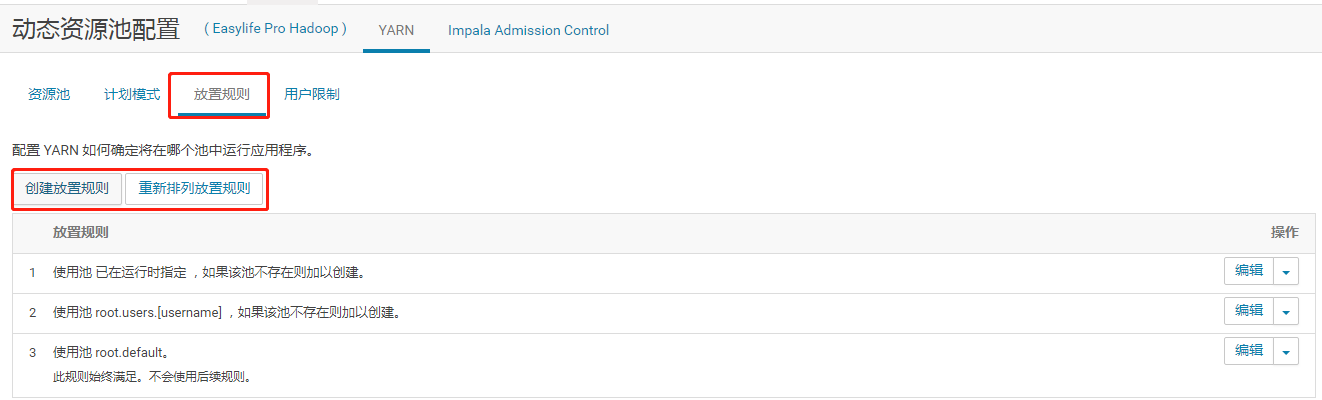
根据实际情况选择放置规则

选择重新排列防止规则设置规则优先级。


如需采用最严格的资源权限控制,可以在资源池权限配置中为每个用户组配置相应的资源池,然后此处删除所有放置规则,只添加“已在运行时指定”一条放置规则, 并且不勾选自动创建池,此时用户提交任务时必须指定使用的资源池,方法为指定参数
|
-Dmapreduce.job.queuename=<pool name> |
2 静态资源池
静态资源隔离能力基于 Linux 容器技术。Linux 容器工具,即 LXC,可以提供轻量级的虚拟化,以便隔离进程和资源。使用 LXC 的优点就是不需要安装太多的软件包,使用过程也不会占用太多的资源,LXC 是在 Linux 平台上基于容器的虚拟化技术的未来标准,最初的 LXC 技术是由 IBM 研发的,目前已经进入 Linux 内核主线,这意味着 LXC 技术将是目前最有竞争力的轻量级虚拟容器技术。LXC 项目由一个 Linux 内核补丁和一些用户空间(userspace)工具组成。这些工具使用由补丁增加的内核新特性,提供一套简化的工具来维护容器。2.6.29 版本后的 Linux 内核版本已经包含该补丁提供的大部分功能。所以强烈建议使用最新的内核源代码。 LXC 在资源管理方面依赖 Linux 内核的 CGroups (Control Groups) 系统,CGroups 系统是 Linux 内核提供的一个基于进 程组的资源管理的框架,可以为特定的进程组限定可以使用的资源。它最初由 Google 的工程师提出,后来被整合进 Linux 内核。CGroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 CGroups 就没有 LXC。
CDH 支持基于 CGroups 或者 Linux 容器进行静态资源隔离,保证不同应用、不同任务之间的资源使用独立性。
CM 提供了静态服务的监控和运维界面,能方便的查看和管理静态服务池。



测试之邮件报警
点击Cloudera Management Service


邮件服务器主机名称:自己选择,可用smtp.163.com、smtp.qq.com等
邮件服务器用户名:对应邮件服务器的邮箱账号,用此账号发邮件
邮件服务器密码:邮件服务器用户名对应的密码
邮件发件人地址:发件人地址一般可以与邮件服务器用户名一样
邮件收件人: 接收报警信息的地址,可为任意可用邮件地址(多个人用,隔开)
重启Cloudera Management Service


测试发送邮件


测试之数据备份
NameNode元数据备份
选择活动的NameNode

进入安全模式


选择保存Namespace

进入活动namenode所在服务器备份
[root@hadoop101 ~]# mkdir /root/namenode_back
[root@hadoop101 ~]# tar -zcvf /root/namenode_back/nn_back.tar.gz /dfs/nn/
tar: Removing leading `/' from member names
/dfs/nn/
/dfs/nn/in_use.lock
/dfs/nn/current/
/dfs/nn/current/edits_inprogress_0000000000037191075
/dfs/nn/current/edits_0000000000036958153-0000000000036960653
...
/dfs/nn/current/edits_0000000000036305400-0000000000036344955
/dfs/nn/current/fsimage_0000000000037191074.md5
/dfs/nn/current/edits_0000000000037178008-0000000000037179639
/dfs/nn/current/edits_0000000000036941796-0000000000036943432
/dfs/nn/current/fsimage_0000000000037189435
/dfs/nn/current/edits_0000000000036727644-0000000000036729281
/dfs/nn/current/edits_0000000000036739092-0000000000036740725
...
/dfs/nn/current/edits_0000000000036522931-0000000000036524567
/dfs/nn/current/VERSION
/dfs/nn/current/edits_0000000000037184542-0000000000037186167
/dfs/nn/current/edits_0000000000036722738-0000000000036724374
...
/dfs/nn/current/edits_0000000000036720180-0000000000036722737
/dfs/nn/current/fsimage_0000000000037189435.md5
/dfs/nn/current/edits_0000000000036967223-0000000000036968854
...
/dfs/nn/current/edits_0000000000036252237-0000000000036273536
/dfs/nn/current/fsimage_0000000000037191074
/dfs/nn/current/edits_0000000000036943433-0000000000036945070
/dfs/nn/current/edits_0000000000036409679-0000000000036453971
/dfs/nn/current/edits_0000000000036518027-0000000000036519658
/dfs/nn/current/edits_0000000000036745627-0000000000036747263
/dfs/nn/current/seen_txid
/dfs/nn/current/edits_0000000000036737460-0000000000036739091
/dfs/nn/current/edits_0000000000036514752-0000000000036516383
...
[root@hadoop101 ~]# ll
total 4
drwxr-xr-x 2 root root 4096 Apr 21 22:11 namenode_back
[root@hadoop101 ~]# cd namenode_back/
[root@hadoop101 namenode_back]# ll
total 24584
-rw-r--r-- 1 root root 25170701 Apr 21 22:11 nn_back.tar.gz
备份MySQL元数据
在MySQL所在节点运行以下命令:
[root@hadoop101 ~]# mysqldump -u root -p -A > /root/mysql_back.dump
Enter password:
可以通过以下命令恢复:
[root@hadoop101 ~]# mysql -u root -p -A < /root/mysql_back.dump
-A :全部数据库
升级之节点的添加和删除
准备机器
新准备一台机器hadoop104,配置好对应主机的网络IP、主机名称、关闭防火墙。安装JDK,下载依赖,关闭SELINUX,解压CM,修改config.ini,创建/opt/cloudera/parcel-repo,创建cloudera-scm用户,最后启动agent。
详见前边。
注意:如果集群配置了Kerberos,则需要在该机器配置。
此时页面点击主机 会自动出现hadoop104
添加节点
1)点击向集群中添加新主机

2)运行向导

3)选择机器hadoop104

4)等待激活

5)检查主机

6)创建主机模板
这里点击创建后自己选择需要的服务。

如果安装过程应用主机模板失败,也可以直接在CM中应用。


之后重新部署启动即可。
7)重新平衡

删除节点
1)停止agent服务

2)停止角色并删除

之后重新部署重启即可。