一、分析函数、窗口函数一般形式
1、分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,
他们的使用形式如下:分析函数名(参数) over (partition by 子句 order by 子句 rows/range.. 子句)
(注:若窗口函数内和sql语句末尾共存在两个order by
a) order by 字段两者一致:即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容一样,
那么sql语句中的排序将先执行,分析函数在分析时就不必再排序;
b) order by 字段两者不一致:即sql语句中的order by子句里的内容和开窗函数over()中的order by子句里的内容不一样,
那么sql语句中的排序将最后在分析函数分析结束后执行排序。)
注意Partition by可以有多个字段。
2、以Scott用户中的emp表,结合sum()over()简单示例
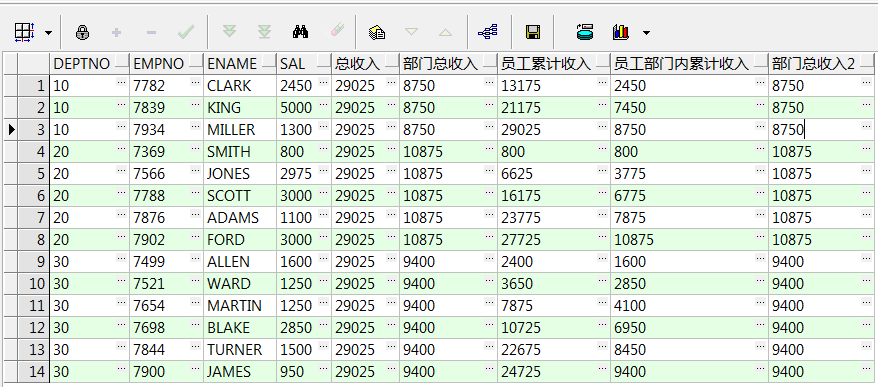
select e.deptno, e.empno, e.ename, e.sal, sum(e.sal)over() 总收入, sum(e.sal)over(partition by e.deptno) 部门总收入,--按部门分组求和 sum(e.sal)over(order by e.empno) 员工累计收入,--按照员工编号(empno)的排序取累计收入和 sum(e.sal)over(partition by e.deptno order by e.empno) 员工部门内累计收入,--按部门(deptno)分组,同时按员工编号(empno)排序取员工部门内累计收入和 sum(e.sal)over(partition by e.deptno order by e.empno rows between unbounded preceding and unbounded following) 部门总收入2--可指定范围,结果同上 from emp e;
累计收入求和的需要重新按empno或者empno、deptno排一下序,不然有些乱看的不是很清楚,基本常用的就是上面几种形式
注:
--unbounded preceding and unbouned following针对当前所有记录的前一条、后一条记录,也就是表中的所有记录
--unbounded:不受控制的,无限的
--preceding:在...之前
--following:在...之后
rows between unbounded preceding and unbounded following 表中的所有记录
rows between unbounded preceding and current row 是指第一行至当前行的汇总
rows between current row and unbounded following 指当前行到最后一行的汇总
rows between 1 preceding and current row 是指当前行的上一行(rownum-1)到当前行的汇总
rows between 1 preceding and 2 following 是指当前行的上一行(rownum-1)到当前行的下两行(rownum+2)的汇总
3、有关ROWS/RANGE窗口的例子(借鉴其他的博客)
with t as (select (case when level in (1, 2) then 1 when level in (4, 5) then 6 else level end) id from dual connect by level < 10) select id, sum(id) over(order by id) default_sum, sum(id) over(order by id range between unbounded preceding and current row) range_unbound_sum, sum(id) over(order by id rows between unbounded preceding and current row) rows_unbound_sum, sum(id) over(order by id range between 1 preceding and 2 following) range_sum, sum(id) over(order by id rows between 1 preceding and 2 following) rows_sum from t;
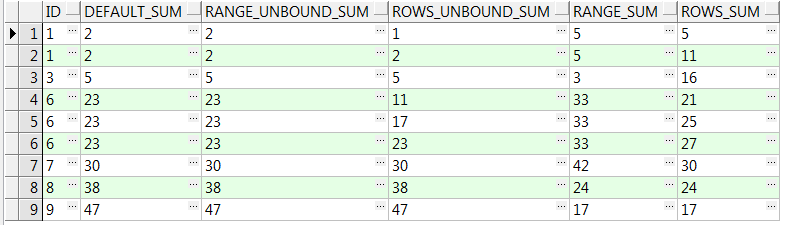
1、窗口子句一般和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN unbounded preceding AND CURRENT ROW,如上例结果集中的defult_sum等于range_unbound_sum;
2、如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
3、range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内,如上例中range_sum(即range 1 preceing and 2 following)例的分析结果:
当id=1时,是sum为1-1<=id<=1+2 的和,即sum=1+1+3=5(取id为1,1,3);
当id=3时,是sum为3-1<=id<=3+2 的和,即sum=3(取id为3);
当id=6时,是sum为6-1<=id<=6+2 的和,即sum=6+6+6+7+8=33(取id为6,6,6,7,8);
以此类推下去,结果如上例中所示。
4、rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关),如上例中rows_sum例结果,是取前1行和后2行数据的求和,分析上例rows_sum的结果:
当id=1(第一个1时)时,前一行没数,后二行分别是1和3,sum=1+1+3=5;
当id=3时,前一行id=1,后二行id都为6,则sum=1+3+6+6=16;
以此类推下去,结果如上例所示。
注:行比较分析函数lead和lag无window(窗口)子句。
二、常用分析函数汇总
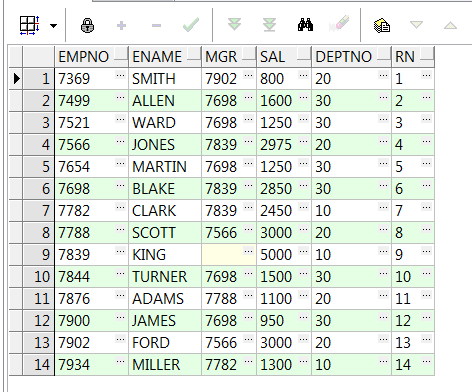
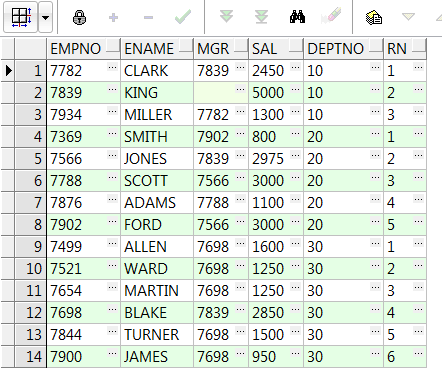
1、row_number() over:伪列(添加一个序号);注:此分析函数必须要加order by排序
select empno,ename,mgr,sal,deptno,row_number() over(order by empno) rn from emp;--按empno排序 select empno,ename,mgr,sal,deptno,row_number() over(partition by deptno order by empno) rn from emp;--(按部门分组,empno排序)添加一个伪列(和rownum类似) --此分析函数在对数据去重时用的比较多 select * from( select empno,ename,mgr,sal,deptno,row_number() over(partition by deptno order by empno) rn from emp) where rn = 1;--每个部门只取一条数据(当然 partition by 后面可以按需求跟多个字段,来达到你想要的筛选目的)
2、count() over():计数
select empno,ename,mgr,sal,deptno,count(*) over() from emp;--总计数 select empno,ename,mgr,sal,deptno,count(*) over(order by empno) from emp;--按照empno累计计数 select empno,ename,mgr,sal,deptno,count(*) over(partition by deptno) from emp;--按照deptno分组计数 select empno,ename,mgr,sal,deptno,count(*) over(partition by deptno order by empno) from emp;--按照deptno分组并累计计数
3、sum() over():求和
select empno,ename,mgr,sal,deptno,sum(sal) over() from emp;--总和 select empno,ename,mgr,sal,deptno,sum(sal) over(order by empno) from emp;--按empno累计求和 select empno,ename,mgr,sal,deptno,sum(sal) over(partition by deptno) from emp;--按照deptno分组求和 select empno,ename,mgr,sal,deptno,sum(sal) over(partition by deptno order by empno) from emp;--按照deptno分组并按empno累计求和
4、avg() over():求平均
select empno,ename,mgr,sal,deptno,avg(sal) over() from emp;--总平均 select empno,ename,mgr,sal,deptno,avg(sal) over(order by empno) from emp;--按照empno累计平均 select empno,ename,mgr,sal,deptno,avg(sal) over(partition by deptno) from emp;--按照deptno分组求平均 select empno,ename,mgr,sal,deptno,avg(sal) over(partition by deptno order by empno) from emp;--按照deptno分组并按empno一个个累计求平均
5、min() over();max() over():求最小最大
select empno,ename,mgr,sal,deptno ,min(sal) over() 最小金额 ,max(sal) over() 最大金额 from emp;--总最小(大) select empno,ename,mgr,sal,deptno ,min(sal) over(order by empno) 最小金额 ,max(sal) over(order by empno) 最大金额 from emp;--按empno排序并一个个递增后的最小(大) select empno,ename,mgr,sal,deptno ,min(sal) over(partition by deptno) 最小金额 ,max(sal) over(partition by deptno) 最大金额 from emp;--按deptno分组后的最小(大) select empno,ename,mgr,sal,deptno ,min(sal) over(partition by deptno order by empno) 最小金额 ,max(sal) over(partition by deptno order by empno) 最大金额 from emp;--组内、递增累计后的最小(大)
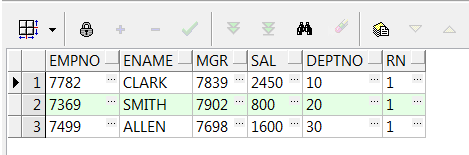
6、rank() over():跳跃排序;dense_rank():连续排序;注:此分析函数同row_number() over()必须要加order by排序
select empno,ename,mgr,sal,deptno ,rank() over(order by sal desc) 跳跃排序 ,dense_rank() over(order by sal desc) 连续排序 from emp;--按sal金额排名 select empno,ename,mgr,sal,deptno ,rank() over(partition by deptno order by sal desc) 跳跃排序 ,dense_rank() over(partition by deptno order by sal desc) 连续排序 from emp;--按deptno分组,组内、金额排名
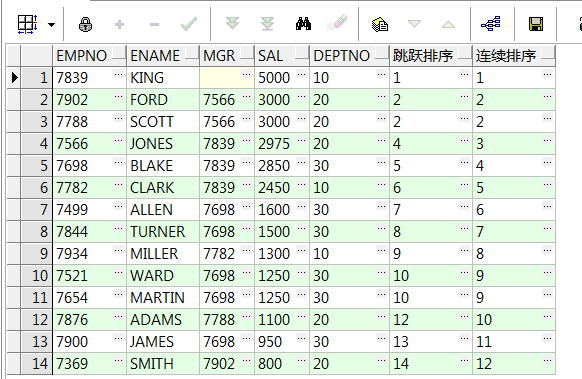

7、ntile(n) over():将数据等分成n组(不够等分的按顺序添加到每个组内);注:必须要加order by
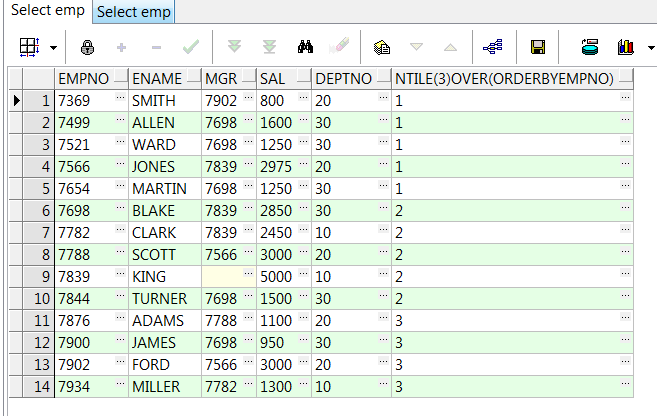
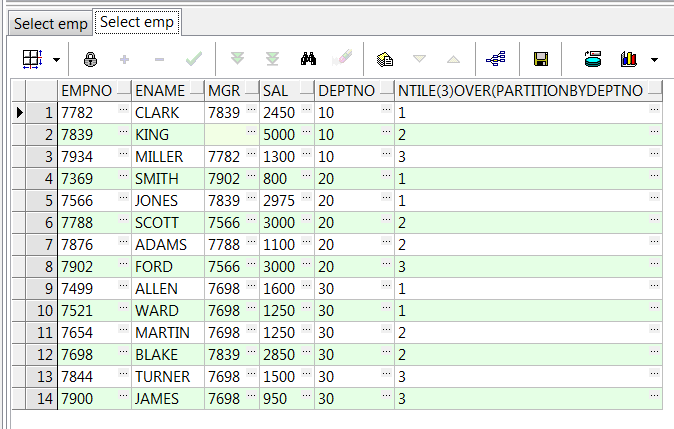
select empno,ename,mgr,sal,deptno,ntile(3) over(order by empno) from emp;--将数据等分3组(不够等分的按顺序添加到每个组内) select empno,ename,mgr,sal,deptno,ntile(3) over(partition by deptno order by empno) from emp;--组内再将数据均分3组
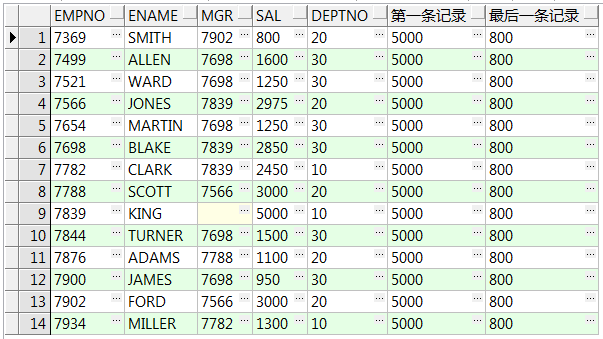
8、first_value() over():取对应第一条记录;last_value() over():取对应最后一条记录(可加 ignore nulls 空值填充)向下(上)找最近的不为空的值
还有:nth_value(value any, nth integer):返回窗口框架中的指定值,如nth_value(salary,2),则表示返回字段salary的第二个窗口函数值
select empno,ename,mgr,sal,deptno ,first_value(sal ignore nulls) over() 整表sal的第一条记录 ,last_value(sal ignore nulls) over() 整表sal的最后一条记录 from emp; select empno,ename,mgr,sal,deptno ,first_value(ename) over(order by empno) 第一条ename记录 ,last_value(ename) over(order by empno) 最后一条ename记录 from emp;--按empno顺序第一、最后一条数据 select empno,ename,mgr,sal,deptno ,first_value(sal) over(partition by deptno) 第一条记录 ,last_value(sal) over(partition by deptno) 最后一条记录 from emp;--部门组内数据第一、最后一条 select empno,ename,mgr,sal,deptno ,first_value(sal) over(partition by deptno order by empno) 第一条记录 ,last_value(sal) over(partition by deptno order by empno) 最后一条记录 from emp;--部门组内、递增数据第一、最后一条
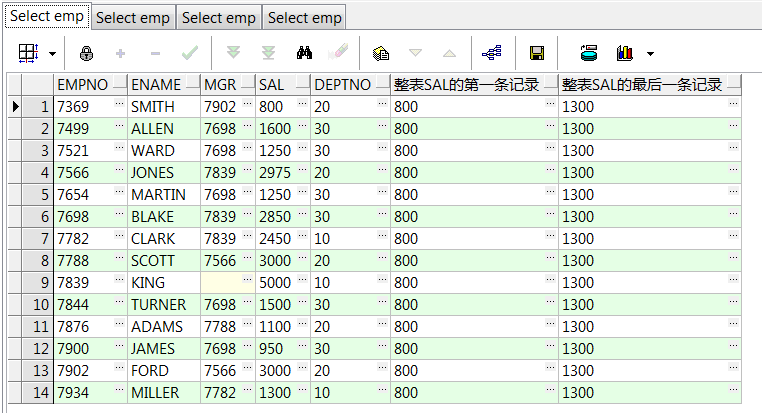
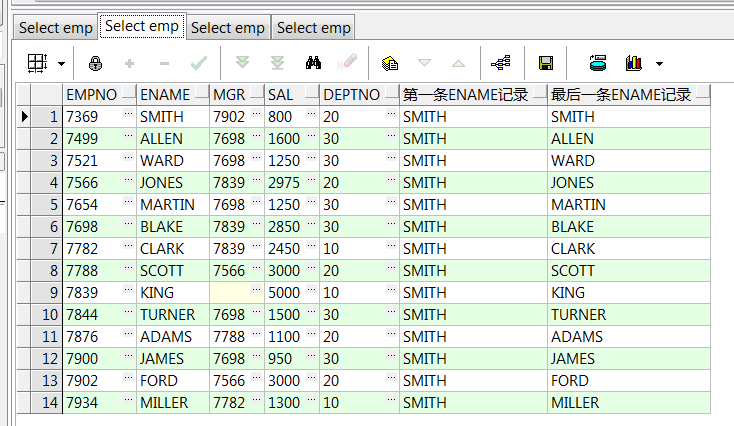
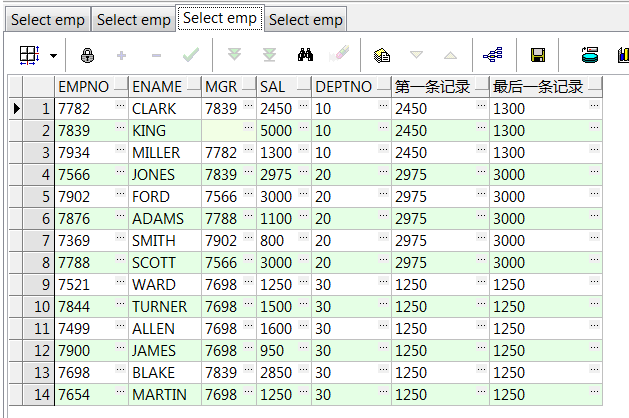
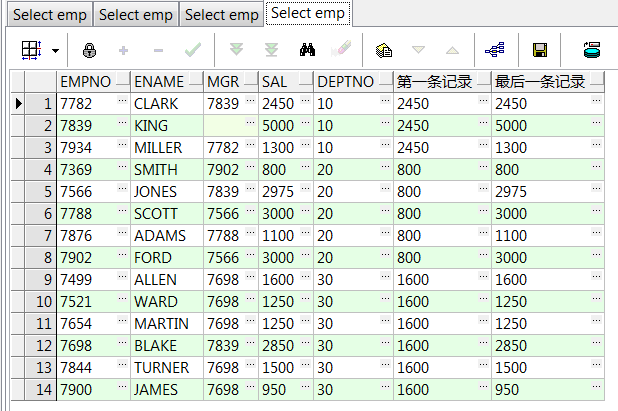
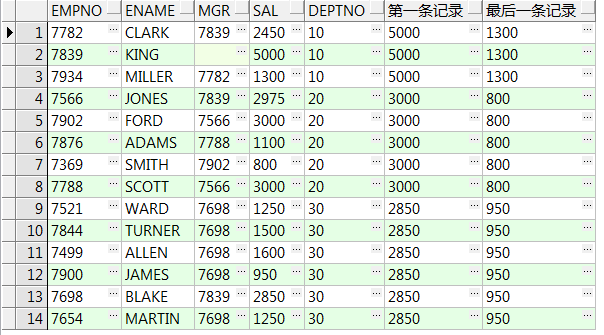
9、keep (dense_rank first/last order by ...)over():配合max()/min()取集合内第一或最后一条
select empno,ename,mgr,sal,deptno ,max(sal) keep(dense_rank first order by sal desc)over() 第一条记录 ,max(sal) keep(dense_rank last order by sal desc)over() 最后一条记录 from emp;--取集合内第一或最后一条 select empno,ename,mgr,sal,deptno ,max(sal) keep(dense_rank first order by sal desc)over(partition by deptno) 第一条记录 ,max(sal) keep(dense_rank last order by sal desc)over(partition by deptno) 最后一条记录 from emp;--组内排序后第一或最后一条
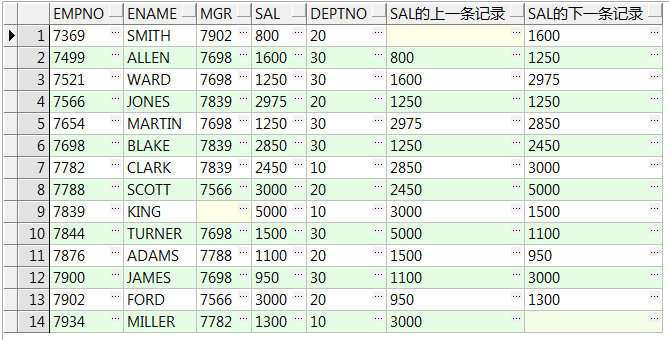
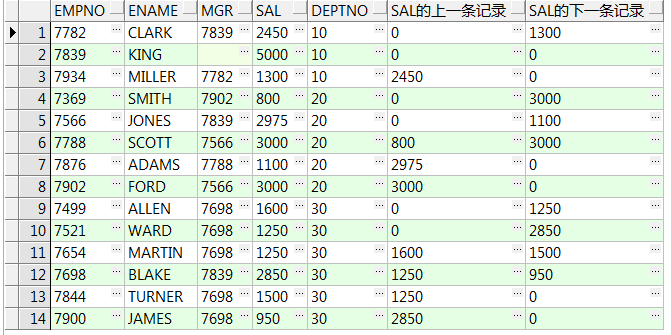
10、lag(column_name,n,若首行无填充默认为null) over() :取出前n行数据;lead() over() :取出前(后)第n行数据;注:必须要加order by排序(11g中支持ignore nulls)
select empno,ename,mgr,sal,deptno ,lag(sal,1) over(order by empno) sal的上一条记录 ,lead(sal,1) over(order by empno) sal的下一条记录 from emp;--取出前(后)第1行数据 select empno,ename,mgr,sal,deptno ,lag(sal,2,0) over(partition by deptno order by empno) sal的上一条记录 ,lead(sal,2,0) over(partition by deptno order by empno) sal的下一条记录 from emp;--取出组内前(后)第2行数据
11、ratio_to_report(a) over(partition by b) :求按照b分组后a的值在所属分组中总值的占比,a的值必须为数值或数值型字段;注:禁用order by
简单理解就是a/b
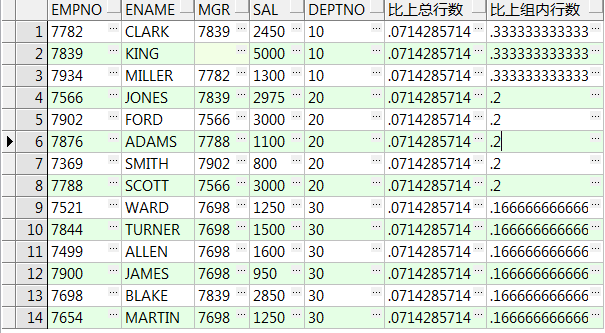
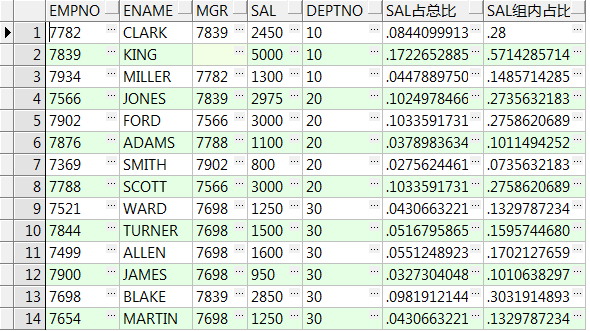
select empno,ename,mgr,sal,deptno ,ratio_to_report(1) over() 比上总行数 ,ratio_to_report(1) over(partition by deptno) 比上组内行数 from emp;--1/总(组内)行数 select empno,ename,mgr,sal,deptno ,ratio_to_report(sal) over() sal占总比 ,ratio_to_report(sal) over(partition by deptno) sal组内占比 from emp;--金额占比
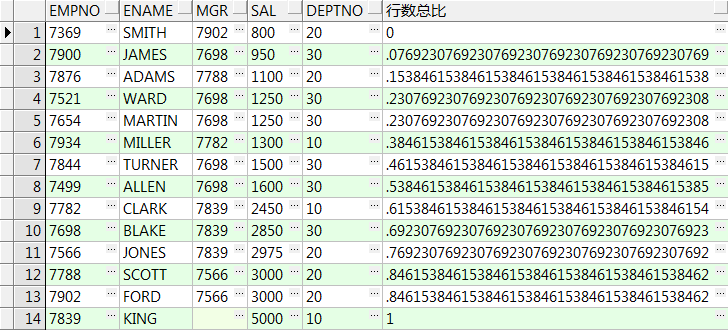
12、percent_rank() over():(所在序号-1)/(总行数-1) 注:必须要加order by排序
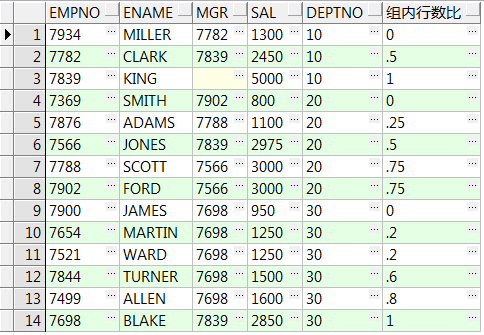
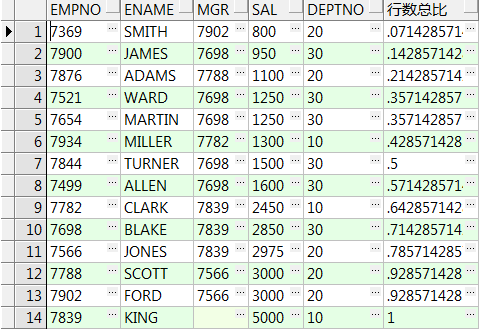
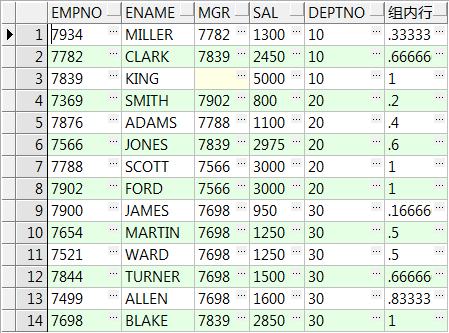
13、cume_dist() over() :所在组排名序号除以该组所有的行数,注意对于重复行,计算时取重复行中的最后一行的位置
select empno,ename,mgr,sal,deptno,cume_dist() over(order by sal) 行数总比 from emp; select empno,ename,mgr,sal,deptno,cume_dist() over(partition by deptno order by sal) 组内行数比 from emp;
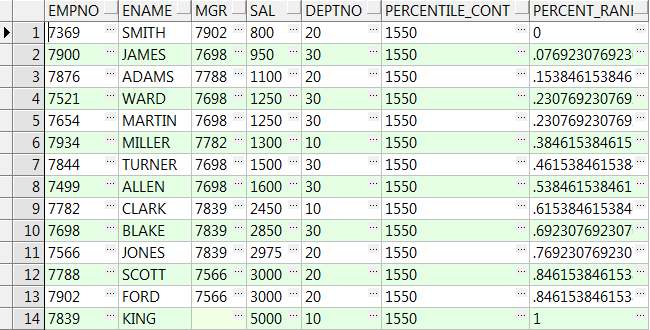
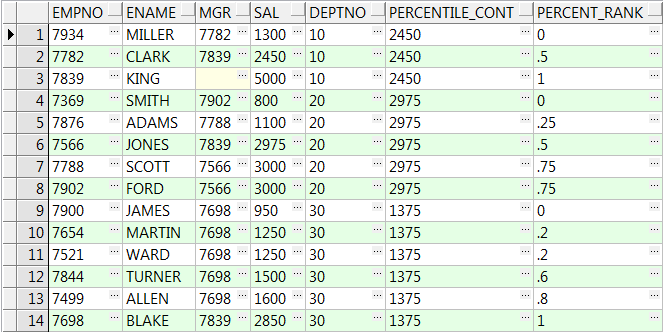
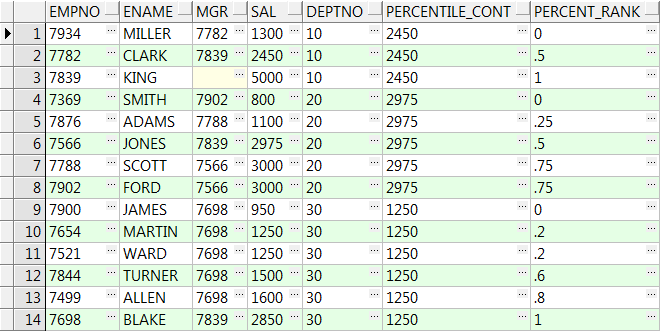
14、precentile_cont( x ) within group(order by ...) over():over()中partition by可选,order by 不可选
x为输入的百分比,是0-1之间的一个小数,返回该百分比位置的数据,若没有则取上下对应两个值的平均值:
select empno,ename,mgr,sal,deptno ,percentile_cont(0.5) within group(order by sal) over() Percentile_Cont ,percent_rank() over(order by sal) Percent_Rank from emp; --Percentile_Cont输入百分比为0.5,则他在对应Percent_Rank:0.46;0.53之间,值就取他两对应值的平均数(1500+1600)/2=1550下面同理 select empno,ename,mgr,sal,deptno ,percentile_cont(0.5) within group(order by sal) over(partition by deptno) Percentile_Cont ,percent_rank() over(partition by deptno order by sal) Percent_Rank from emp;
15、percentile_disc() within group(order by ...) over():返回一个与输入的分布百分比值相对应的数据值,如果没有正好对应的数据值,就取大于该分布值的下一个值(好像要四舍五入)。
注意:本函数与percentile_cont的区别在找不到对应的分布值时返回的替代值的计算方法不同
select empno,ename,mgr,sal ,deptno,percentile_disc(0.7) within group(order by sal) over() Percentile_Cont ,percent_rank() over(order by sal) Percent_Rank from emp; select empno,ename,mgr,sal,deptno ,percentile_disc(0.5) within group(order by sal) over(partition by deptno) Percentile_Cont ,percent_rank() over(partition by deptno order by sal) Percent_Rank from emp;

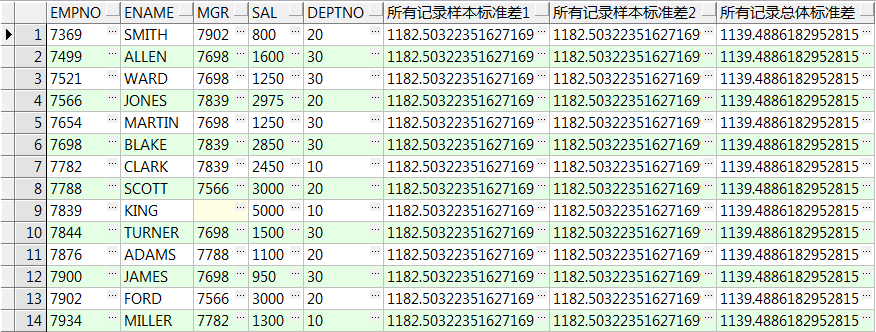
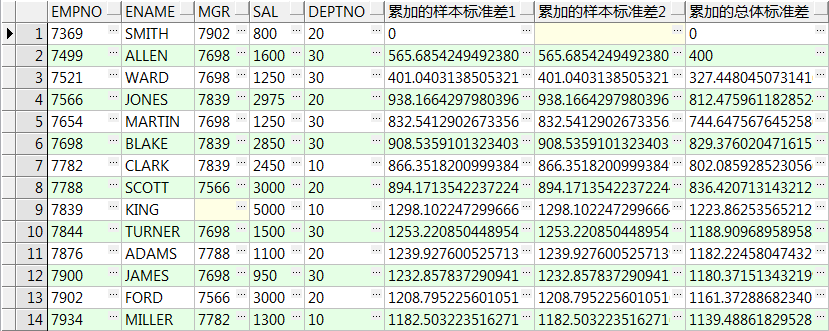
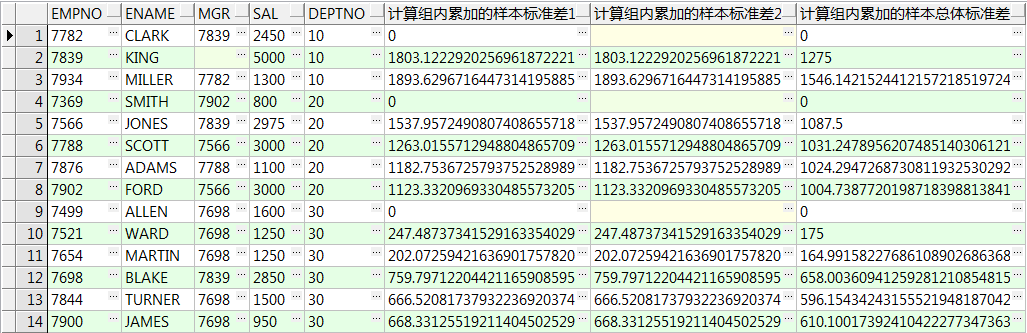
16、stddev() over():计算样本标准差,只有一行数据时返回0,partition by 可选,order by 可选
stddev_samp() over():计算样本标准差,只有一行数据时返回null,partition by 可选,order by 可选
stddev_pop() over():计算总体标准差,partition by 可选,order by 可选
select empno,ename,mgr,sal,deptno ,stddev(sal) over() 所有记录样本标准差1 ,stddev_samp(sal) over() 所有记录样本标准差2 ,stddev_pop(sal) over() 所有记录总体标准差 from emp; select empno,ename,mgr,sal,deptno ,stddev(sal) over(order by empno) 累加的样本标准差1 ,stddev_samp(sal) over(order by empno) 累加的样本标准差2 ,stddev_pop(sal) over(order by empno) 累加的总体标准差 from emp; select empno,ename,mgr,sal,deptno ,stddev(sal) over(partition by deptno) 组内样本标准差1 ,stddev_samp(sal) over(partition by deptno) 组内样本标准差2 ,stddev_pop(sal) over(partition by deptno) 组内总体标准差 from emp; select empno,ename,mgr,sal,deptno ,stddev(sal) over(partition by deptno order by empno) 计算组内累加的样本标准差1 ,stddev_samp(sal) over(partition by deptno order by empno) 计算组内累加的样本标准差2 ,stddev_pop(sal) over(partition by deptno order by empno) 计算组内累加的样本总体标准差 from emp;

17、variance() over():计算样本方差,只有一行数据时返回0,partition by 可选,order by 可选
var_samp() over():计算样本方差,只有一行数据时返回null,partition by 可选,order by 可选
var_pop() over():计算总体方差,partition by 可选,order by 可选
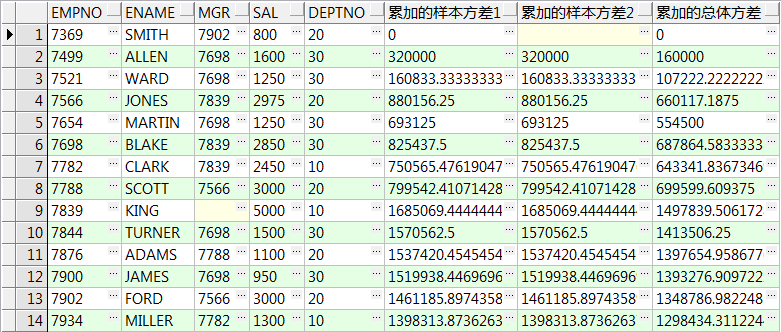
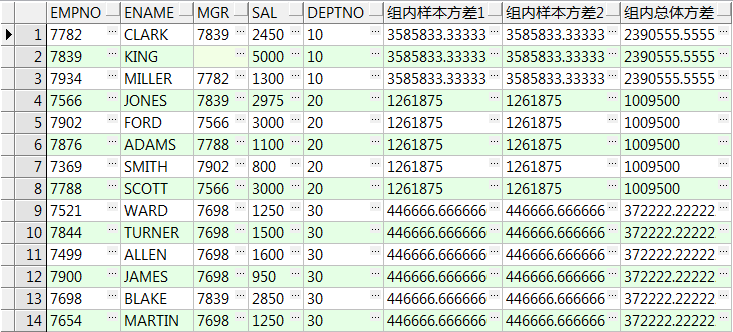
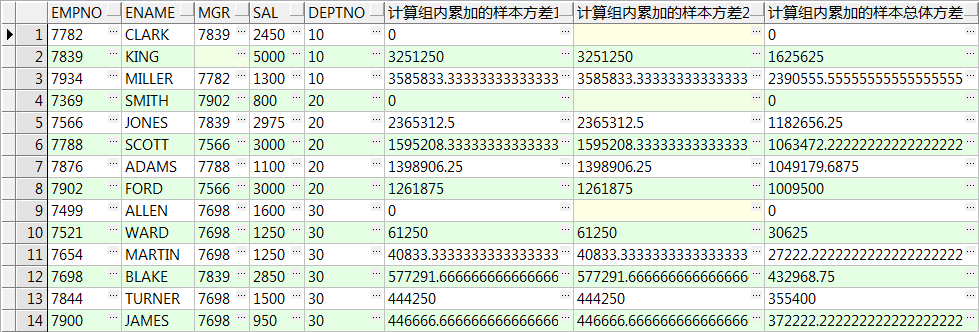
select empno,ename,mgr,sal,deptno ,variance(sal) over() 所有记录样本方差1 ,var_samp(sal) over() 所有记录样本方差2 ,var_pop(sal) over() 所有记录总体方差 from emp; select empno,ename,mgr,sal,deptno ,variance(sal) over(order by empno) 累加的样本方差1 ,var_samp(sal) over(order by empno) 累加的样本方差2 ,var_pop(sal) over(order by empno) 累加的总体方差 from emp; select empno,ename,mgr,sal,deptno ,variance(sal) over(partition by deptno) 组内样本方差1 ,var_samp(sal) over(partition by deptno) 组内样本方差2 ,var_pop(sal) over(partition by deptno) 组内总体方差 from emp; select empno,ename,mgr,sal,deptno ,variance(sal) over(partition by deptno order by empno) 计算组内累加的样本方差1 ,var_samp(sal) over(partition by deptno order by empno) 计算组内累加的样本方差2 ,var_pop(sal) over(partition by deptno order by empno) 计算组内累加的样本总体方差 from emp;

--stddev()=sqrt(variance()) sqrt()--求开方
--stddev_samp()=sqrt(var_samp())
--stddec_pop=sqrt(var_pop())
17、covar_samp over():返回一对表达式的样本协方差,partition by 可选,order by 可选
covar_pop over(): 返回一堆表达式的总体协方差,partition by 可选,order by 可选
18、corr() over() :返回一对表达式的相关系数,partition by 可选,order by 可选
19、REGR_ (Linear Regression) Functions:这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用
(注:此为学习记录笔记,仅供参考若有问题请指正,后续补充......)
参考原文:http://www.blogjava.net/pengpenglin/archive/2008/06/25/210536.html
参考原文:https://blog.csdn.net/huozhicheng/article/details/5843782/
参考原文:https://blog.csdn.net/haiross/article/details/15336313
参考原文:https://blog.csdn.net/cc_0101/article/details/80884076
参考原文:https://blog.csdn.net/richieruan/article/details/52712447?locationNum=6