keys * 获取所有的key 忽略其数据类型 数据为空 返回(empty list or set)
keys a* 、*b 获取以a开头 或者 以b结尾的key 返回(empty list or set)
exists key 判断key是否存在 存在返回1 不存在返回0
del key 删除key 返回 受影响key的个数
expire key seconds 设置key的过期时间 单位为秒
persist key 消除key的过期时间设置
move key db 数据移动到 另外的一个数据库中
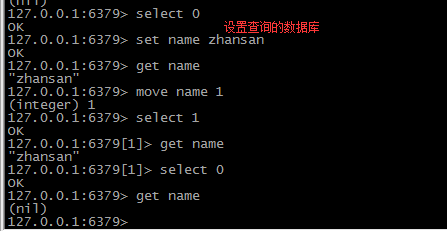
randomkey 在当前数据库中随机返回一个key 如果当前数据库没有key 则返回nil
rename key newKey 修改key的名称
type key 返回key的类型
----------------------------服务器相关命令
ping 是否连接redis 已经连接返回 pong 未连接 返回 Connection refused
echo xxxx 向命令行 输出xxxxx
select index 选择数据库。 Redis 数据库编号从 0~15,我们可以选择任意一个数据库来进行数据的存取 越界则报错(error) ERR invalid DB index
qiut 退出当前redis-cli连接
dbsize 返回当前数据库的key数目
info [参数] 获取redis 信息 不写参数有默认返回
一种易于解释(parse)且易于阅读的格式,返回关于 Redis 服务器的各种信息和统计数值。 通过给定可选的参数 section ,可以让命令只返回某一部分的信息: server : 一般 redis 服务器信息,包含以下域: redis_version : Redis 服务器版本 redis_git_sha1 : Git SHA1 redis_git_dirty : Git dirty flag os : Redis 服务器的宿主操作系统 arch_bits : 架构(32 或 64 位) multiplexing_api : Redis 所使用的事件处理机制 gcc_version : 编译 Redis 时所使用的 GCC 版本 process_id : 服务器进程的 PID run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群) tcp_port : TCP/IP 监听端口 uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数 uptime_in_days : 自 Redis 服务器启动以来,经过的天数 lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理 clients : 已连接客户端信息,包含以下域: connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端) client_longest_output_list : 当前连接的客户端当中,最长的输出列表 client_longest_input_buf : 当前连接的客户端当中,最大输入缓存 blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 memory : 内存信息,包含以下域: used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位 used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量 used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。 used_memory_peak : Redis 的内存消耗峰值(以字节为单位) used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值 used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位) mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率 mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。 在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。 当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。 内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。 当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。 Because Redis does not have control over how its allocations are mapped to memory pages, high used_memory_rss is often the result of a spike in memory usage. 当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。 如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。 查看 used_memory_peak 的值可以验证这种情况是否发生。 persistence : RDB 和 AOF 的相关信息 stats : 一般统计信息 replication : 主/从复制信息 cpu : CPU 计算量统计信息 commandstats : Redis 命令统计信息 cluster : Redis 集群信息 keyspace : 数据库相关的统计信息 除上面给出的这些值以外,参数还可以是下面这两个: all : 返回所有信息 default : 返回默认选择的信息 当不带参数直接调用 INFO 命令时,使用 default 作为默认参数。 不同版本的 Redis 可能对返回的一些域进行了增加或删减。 因此,一个健壮的客户端程序在对 INFO 命令的输出进行分析时,应该能够跳过不认识的域,并且妥善地处理丢失不见的域。 以上内容来自http://blog.csdn.net/lang_man_xing/article/details/38539057
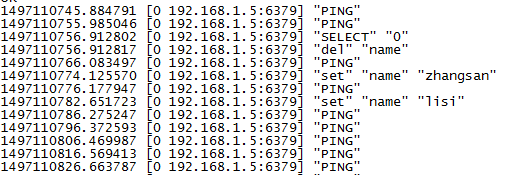
monitor 此命令用与监控redis 将接收到的命令 在控制台打印出来 演示效果 secureCRT克隆一个连接 clone session 执行增删 改 查
 monitor命令监控到的命令请求
monitor命令监控到的命令请求
config set [参数] config get [参数] 设置系统参数 获取系统参数 实时生效 无需重启

flushdb 删除当前数据库中所有的key
flushall 删除redis 服务器上所有的key
--------------redis主从复制--------------------------
开启另外一台 虚拟机 主机地址为192.168.1.5 从服务器为 192.168.1.6
在从服务器上的redis.conf文件中
设置 slaveof 192.168.1.5 6379 即可
修改后启动 从服务器 ,出现以下信息 说明配置 成功
注意要修改主服务器的bind IP 否则从服务器连接不上 将bind 0.0.0.0 表示所有网络都可以连接
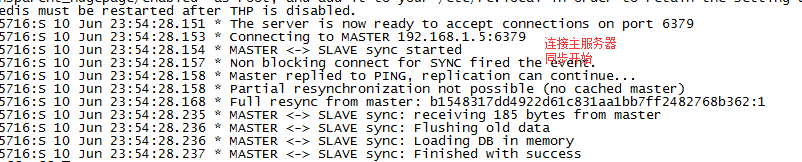
此时分别打开从服务器的 redis-cli 在从服务器 192.168.1.6 上 输入monitor 用与监听同步信息
--------------主服务器redis-cli---------------------------------------
-----------------从服务器 redis-cli监听到的命令----------------------------------
退出监听器获取name key的值
查看 info + 参数 查看信息
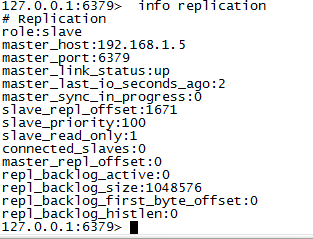

里面有一个角色标识 ,来判断是主库还是从库 ,对于本例是一个从库,同时还有一个
master_link_status 用于标明主从是否异步,如果此值=up,说明同步正常;如果此值=down,说明同步异步;
db0:keys=1,expires=0, 用于说明数据库有几个 key,以及过期 key 的数量 ;
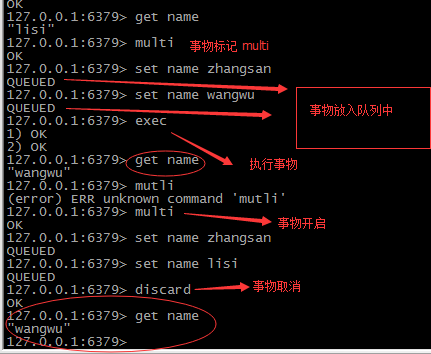
---------------------简单事物处理---------------------------------------------
redis 对事务的支持目前还比较简单。 redis 只能保证一个 client 发起的事务中的命令可以连
续的执行,而中间不会插入其他 client 的命令。 由于 redis 是单线程来处理所有 client 的请
求的所以做到这点是很容易的。一般情况下 redis 在接受到一个 client 发来的命令后会立即
处理并 返回处理结果,但是当一个 client 在一个连接中发出 multi 命令有,这个连接会进入
一个事务上下文,该连接后续的命令并不是立即执行,而是先放到一个队列中。当从此连接
受到 exec 命令后, redis 会顺序的执行队列中的所有命令。并将所有命令的运行结果打包到
一起返回给 client.然后此连接就 结束事务上下文。
--------------------乐观锁事物处理 ------------------------------
乐观锁原理 对key 进行 版本标记(watch key) 标识这个key 是乐观锁 复制一个 session
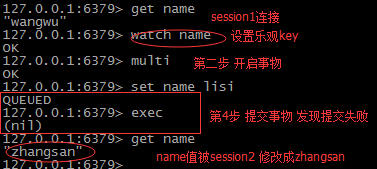
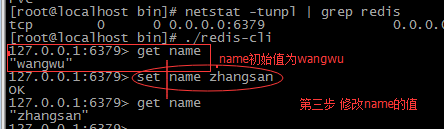
完成乐观锁的测试
----------------------持久化机制-----------------------------------
默认方式 在conf文件中的默认配置
save 900 1 #900 秒内如果超过 1 个 key 被修改,则发起快照保存
save 300 10 #300 秒内容如超过 10 个 key 被修改,则发起快照保存
save 60 10000
redis-cli端 可以主动设置 保存快照文件到磁盘 使用
save 或者 bgsave 命令通知 redis 做一次快照持久化。 save 操作是在主线程
中保存快照的,由于 redis 是用一个主线程来处理所有 client 的请求,这种方式会阻塞所有
client 请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整
写入到磁盘一次,并不是增量的只同步变更数据。如果数据量大的话,而且写操作比较多,
必然会引起大量的磁盘 io 操作,可能会严重影响性能
查看log日志 设置logfile的路径 和日志级别 info (查看所有信息 开发模式使用)

------------------aof方式 --------------------
aof 比快照方式有更好的持久化性,是由于在使用 aof 持久化方式时,redis 会将每一个收到
的写命令都通过 write 函数追加到文件中(默认是 appendonly.aof)。当 redis 重启时会通过重
新执行文件中保存的写命令来在内存中重建整个数据库的内容
appendonly yes //启用 aof 持久化方式 # appendfsync always //收到写命令就立即写入磁盘,最慢,但是保证完全的持久化 appendfsync everysec //每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中 # appendfsync no //完全依赖 os,性能最好,持久化没保证
此方式下redis调用fork 产生 父子进程
1-子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
2-父进程继续处理client请求 除了把命令写入到原来的aof文件中以外,同时把收到的命令缓存起来
4-当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然
后父进程把缓存的写命令也写入到临时文件。
5-现在父进程可以使用临时文件替换老的 aof 文件,并重命名,后面收到的写命令也开始
往新的 aof 文件中追加。
需要注意到是重写 aof 文件的操作,并没有读取旧的 aof 文件,而是将整个内存中的数据库
内容用命令的方式重写了一个新的 aof 文件 这样会导致文件越来越大 需要手动 清理
client 端 可以执行 bgrewriteaof 命令 剔除 aof文件中重复的内容
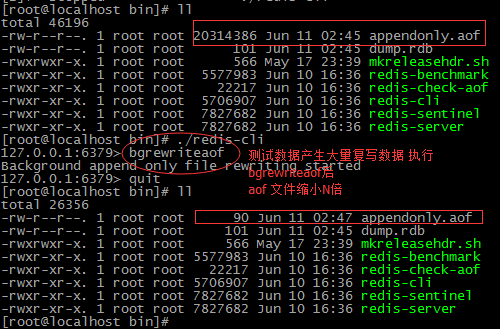
----------------------------------发布及订阅消息 ---------------
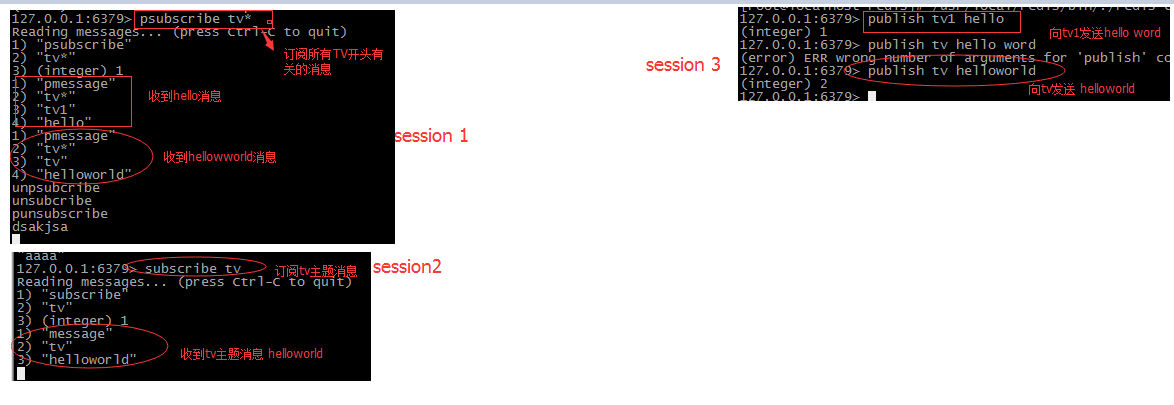
发布订阅(pub/sub)是一种消息通信模式,主要的目的是解耦消息发布者和消息订阅者之间的耦合订阅者可以通过 subscribe 和 psubscribe 命令向 redis
server 订阅自己感兴趣的消息类型, redis 将消息类型称为通道(channel)。当发布者通过
publish 命令向 redis server 发送特定类型的消息时。订阅该消息类型的全部 client 都会收到
此消息。这里消息的传递是多对多的。一个 client可以订阅多个 channel,也可以向多个 channel发送消息
订阅之后 线程是阻塞状态 意味这不能接受其他的命令
---------------Pipeline 批量发送请求 处理 --redis-jar 为jedis-2.9.0.jar
package com.swb.redis; import org.junit.Test; import redis.clients.jedis.Connection; import redis.clients.jedis.Jedis; import redis.clients.jedis.Pipeline; public class RedisTest { // 采用 pipeline 方式发送指令 @Test public void usePipeline() { long start = System.currentTimeMillis(); try { Jedis jredis = new Jedis("192.168.1.5", 6379); Pipeline pi=jredis.pipelined(); for (int i = 0; i < 10000; i++) { pi.incr("test"); } jredis.quit(); } catch (Exception e) { } long end = System.currentTimeMillis(); System.out.println("用 pipeline 方式耗时: " + (end - start) + "毫秒"); } // 普通方式发送指令 @Test public void withoutPipeline() { long start = System.currentTimeMillis(); try { Jedis jredis = new Jedis("192.168.1.5", 6379); for (int i = 0; i < 10000; i++) { jredis.incr("test"); } jredis.quit(); } catch (Exception e) { } long end = System.currentTimeMillis(); System.out.println("用 普通方式耗时: " + (end - start) + "毫秒"); } @Test public void testConnection(){ this.withoutPipeline(); this.usePipeline(); /** 用 普通方式耗时: 2038毫秒 用 pipeline 方式耗时: 56毫秒 */ } }
--------------------------redis 虚拟内存---------------
vm-enabled yes #开启 vm 功能
vm-swap-file /tmp/redis.swap #交换出来的 value 保存的文件路径
vm-max-memory 1000000 #redis 使用的最大内存上限
vm-page-size 32 #每个页面的大小 32 个字节
vm-pages 134217728 #最多使用多少页面
vm-max-threads 4 #用于执行 value 对象换入换出的工作线程数量
redis 的虚拟内存在设计上为了保证 key 的查找速度,只会将 value 交换到 swap 文件中。所
以如果是内存问题是由于太多 value 很小的 key 造成的,那么虚拟内存并不能解决,和操作
系统一样 redis 也是按页面来交换对象的。 redis 规定同一个页面只能保存一个对象。但是一
个对象可以保存在多个页面中。在 redis 使用的内存没超过 vm-max-memory 之前是不会交换
任何 value 的。当超过最大内存限制后, redis 会选择较过期的对象。如果两个对象一样过期
会优先交换比较大的对象,精确的公式 swappability = age*log(size_in_memory)。对于
vm-page-size 的设置应该根据自己的应用将页面的大小设置为可以容纳大多数对象的大小,
太大了会浪费磁盘空间,太小了会造成交换文件出现碎片。对于交换文件中的每个页面, redis
会在内存中对应一个 1bit 值来记录页面的空闲状态。所以像上面配置中页面数量(vm-pages
134217728 )会占用 16M 内存用来记录页面空闲状态。 vm-max-threads 表示用做交换任务的
线程数量。如果大于 0 推荐设为服务器的 cpu 内核的数量,如果是 0 则交换过程在主线程进行