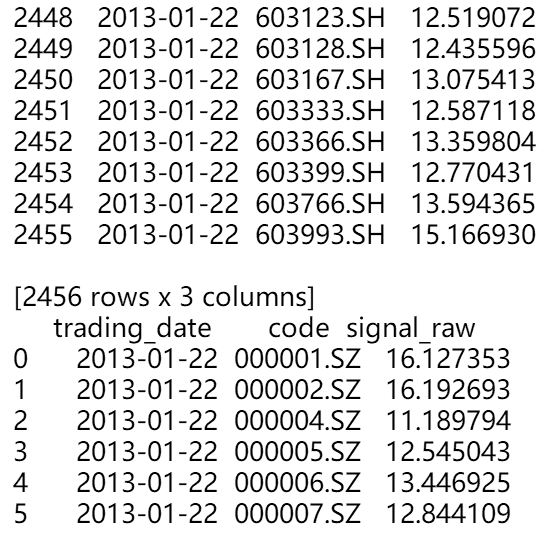
pandas的IO
量化投资逃不过数据处理,数据处理逃不过数据的读取和存储。一般,最常用的交易数据存储格式是csv,但是csv有一个很大的缺点,就是无论如何,存储起来都是一个文本的格式,例如日期‘2018-01-01’,在csv里面是字符串格式存储,每次read_csv的时候,我们如果希望日期以datatime格式存储的时候,都要用pd.to_datetime()函数来转换一下,显得很麻烦。而且,csv文件万一一不小心被excel打开之后,说不定某些格式会被excel“善意的改变”,譬如字符串‘000006’被excel打开之后,然后万一选择了保存,那么再次读取的时候,将会自动变成数值,前面的五个0都消失了,很显然,原来的股票代码被改变了,会造成很多不方便。
此外,如果我们的pandas中的某些地方存储的不是可以被文本化的内容的时候,csv的局限性就更大了。pandas官方提供了一个很好的存储格式,hdfs。所以笔者建议,凡是pandas格式的数据,想存储下来,就用hdfs格式。
例如下面这样的一个数据:
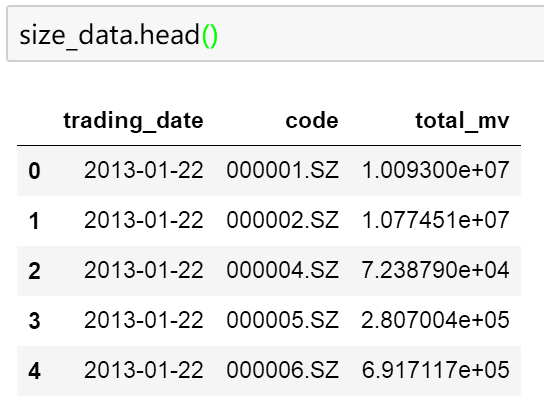
size_data.to_hdf('filename.h5', key='data')当我们想读取的时候,只要
size_data = pd.read_hdf('filename.h5', key='data')就可以了,size_data就可以再次使用了。
面板数据的截面分析
所谓的面板数据就是截面数据加上时间序列数据。股票的数据很显然就是一个面板数据。在量化投资中,我们经常会使用截面数据处理和时间序列数据的处理。
所谓的截面数据处理,就是站在某一个交易日,或者某一个时间点,来考察全市场这么多股票的情况。而,通常,我们希望对时间序列上每一个时间节点都进行一次截面处理。
例如,我们现在有这样的一个dataframe:
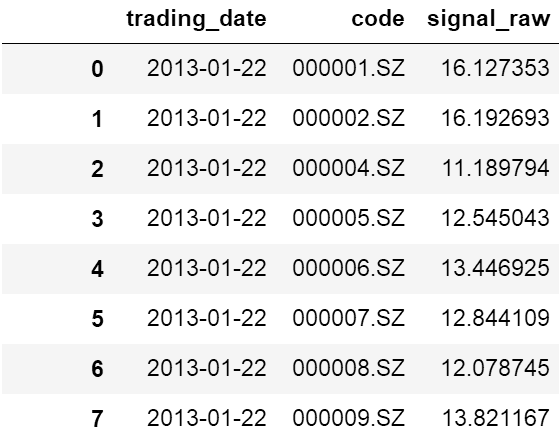
。。。。。。
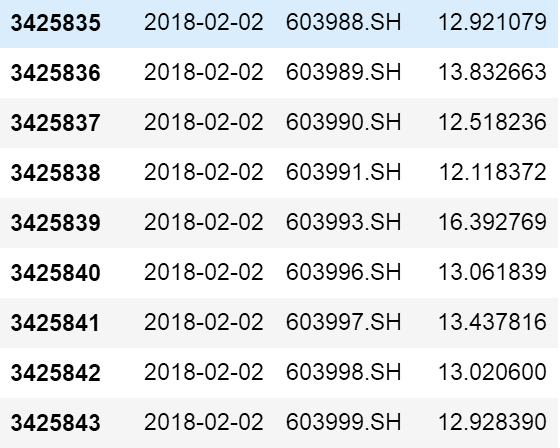
显然,这个数据就是一个典型的面板数据。我们现在希望对第三列signal_raw做截面上的处理。这个时候,就可以使用groupby。
-
signal.sort_values(['trading_date', 'code'], inplace=True)
-
signal['siganl_win'] = signal.groupby('trading_date').apply(your_function).values
我们来分析一下上面的代码。第一行的作用是先根据trading_date排序,然后根据code排序。
代码中的your_function就是我们希望作用在截面数据上的函数。
我们来好好分析一下:
-
def xf(df):
-
print df
-
signal.groupby('trading_date').apply(xf)
我们运行一下看看,究竟groupby之后每一个部分是什么。
很显然,groupby把dataframe按照日期分成好多小的dataframe。所以我们的处理函数只要能够返回一个等长的series,注意,我们的函数要返回一个series,要不然整个函数就不是这样写的。大家可以尝试返回一个等长的list,就会发现上面的代码不能成功运行。这样的原因是因为如果返回一个series,pandas最后整个groupby语句返回的是一个multi index 的series,index第一层是日期,第二层是返回的series的index。如果返回的是list,那么返回的是一个类似于字典结构的结果,key是日期,values是返回的list。
之所以最后要用values是将multi index去掉,只留下数值。而之所以前面要sort_values是为了顺序匹配,大家可以仔细想想。
面板数据的时间序列分析
很简单,只要sort的时候,顺序换一下,先code,后日期。然后groupby的时候按照code就可以了。
groupby apply的彩蛋
groupby后面apply的函数运行过程中,第一个被groupby拆分的子dataframe会被apply后面的函数运行两次。大家如果看仔细的话,会发现,第一个子dataframe和第二个dataframe其实是一样的。pandas官方说,之所以这样是第一个子dataframe传入的目的是为了寻找一个能够优化运行速度的方法,提高后面的运行效率。所以,如果日期只有一种,而再groupby后,返回的逻辑和有多种日期是不一样的,大家可以自行研究一下,还是很有趣的。