什么是不可变对象?
众所周知, 在Java中, String类是不可变的。那么到底什么是不可变的对象呢? 可以这样认为:如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
区分对象和对象的引用
对于Java初学者, 对于String是不可变对象总是存有疑惑。看下面代码:
String s = "ABCabc";
System.out.println("s = " + s);
s = "123456";
System.out.println("s = " + s);
打印结果为: s = ABCabc
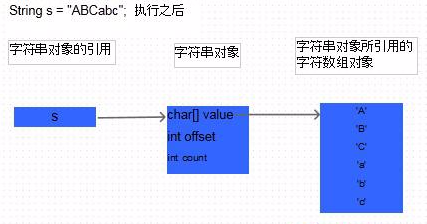
首先创建一个String对象s,然后让s的值为“ABCabc”, 然后又让s的值为“123456”。 从打印结果可以看出,s的值确实改变了。那么怎么还说String对象是不可变的呢? 其实这里存在一个误区: s只是一个String对象的引用,并不是对象本身。对象在内存中是一块内存区,成员变量越多,这块内存区占的空间越大。引用只是一个4字节的数据,里面存放了它所指向的对象的地址,通过这个地址可以访问对象。 也就是说,s只是一个引用,它指向了一个具体的对象,当s=“123456”; 这句代码执行过之后,又创建了一个新的对象“123456”, 而引用s重新指向了这个心的对象,原来的对象“ABCabc”还在内存中存在,并没有改变。内存结构如下图所示:
Java和C++的一个不同点是, 在Java中不可能直接操作对象本身,所有的对象都由一个引用指向,必须通过这个引用才能访问对象本身,包括获取成员变量的值,改变对象的成员变量,调用对象的方法等。而在C++中存在引用,对象和指针三个东西,这三个东西都可以访问对象。其实,Java中的引用和C++中的指针在概念上是相似的,他们都是存放的对象在内存中的地址值,只是在Java中,引用丧失了部分灵活性,比如Java中的引用不能像C++中的指针那样进行加减运算。
为什么String对象是不可变的?
要理解String的不可变性,首先看一下String类中都有哪些成员变量。 在JDK1.6中,String的成员变量有以下几个:
public final class String
implements java.io.Serializable, Comparable<string>, CharSequence{
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
/** Cache the hash code for the string */
private int hash; // Default to 0</string>
public final class String
implements java.io.Serializable, Comparable<string>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0</string>
value,offset和count这三个变量都是private的,并且没有提供setValue, setOffset和setCount等公共方法来修改这些值,所以在String类的外部无法修改String。也就是说一旦初始化就不能修改, 并且在String类的外部不能访问这三个成员。此外,value,offset和count这三个变量都是final的, 也就是说在String类内部,一旦这三个值初始化了, 也不能被改变。所以可以认为String对象是不可变的了。
那么在String中,明明存在一些方法,调用他们可以得到改变后的值。这些方法包括substring, replace, replaceAll, toLowerCase等。例如如下代码:
String a = "ABCabc";
System.out.println("a = " + a);
a = a.replace('A', 'a');
System.out.println("a = " + a);
打印结果为: a = ABCabc
那么a的值看似改变了,其实也是同样的误区。再次说明, a只是一个引用, 不是真正的字符串对象,在调用a.replace('A', 'a')时, 方法内部创建了一个新的String对象,并把这个心的

String ss = "123456";
System.out.println("ss = " + ss);
ss.replace('1', '0');
System.out.println("ss = " + ss);
打印结果: ss = 123456
String对象真的不可变吗?
从上文可知String的成员变量是private final 的,也就是初始化之后不可改变。那么在这几个成员中, value比较特殊,因为他是一个引用变量,而不是真正的对象。value是final修饰的,也就是说final不能再指向其他数组对象,那么我能改变value指向的数组吗? 比如将数组中的某个位置上的字符变为下划线“_”。 至少在我们自己写的普通代码中不能够做到,因为我们根本不能够访问到这个value引用,更不能通过这个引用去修改数组。 那么用什么方式可以访问私有成员呢? 没错,用反射, 可以反射出String对象中的value属性, 进而改变通过获得的value引用改变数组的结构。下面是实例代码:public static void testReflection() throws Exception {
//创建字符串"Hello World", 并赋给引用s
String s = "Hello World";
System.out.println("s = " + s); //Hello World
//获取String类中的value字段
Field valueFieldOfString = String.class.getDeclaredField("value");
//改变value属性的访问权限
valueFieldOfString.setAccessible(true);
//获取s对象上的value属性的值
char[] value = (char[]) valueFieldOfString.get(s);
//改变value所引用的数组中的第5个字符
value[5] = '_';
System.out.println("s = " + s); //Hello_World
}
打印结果为: s = Hello World
在这个过程中,s始终引用的同一个String对象,但是再反射前后,这个String对象发生了变化, 也就是说,通过反射是可以修改所谓的“不可变”对象的。但是一般我们不这么做。这个反射的实例还可以说明一个问题:如果一个对象,他组合的其他对象的状态是可以改变的,那么这个对象很可能不是不可变对象。例如一个Car对象,它组合了一个Wheel对象,虽然这个Wheel对象声明成了private final 的,但是这个Wheel对象内部的状态可以改变, 那么就不能很好的保证Car对象不可变。
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的:
String S1 = “This is only a” + “ simple” + “ test”;
StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候 StringBuffer 居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个
String S1 = “This is only a” + “ simple” + “test”; 其实就是:
String S1 = “This is only a simple test”; 所以当然不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
String S2 = “This is only a”;
String S3 = “ simple”;
String S4 = “ test”;
String S1 = S2 +S3 + S4;
这时候 JVM 会规规矩矩的按照原来的方式去做
在大部分情况下 StringBuffer > String
StringBuffer
Java.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。
可将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
例如,如果 z 引用一个当前内容是“start”的字符串缓冲区对象,则此方法调用 z.append("le") 会使字符串缓冲区包含“startle”,而 z.insert(4, "le") 将更改字符串缓冲区,使之包含“starlet”。
在大部分情况下 StringBuilder > StringBuffer
java.lang.StringBuilde
java.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同。
关于线程和线程不安全:
概述
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
安全性
类要成为线程安全的,首先必须在单线程环境中有正确的行为。如果一个类实现正确(这是说它符合规格说明的另一种方式),那么没有一种对这个类的对象的操作序列(读或者写公共字段以及调用公共方法)可以让对象处于无效状态,观察到对象处于无效状态、或者违反类的任何不可变量、前置条件或者后置条件的情况。
此外,一个类要成为线程安全的,在被多个线程访问时,不管运行时环境执行这些线程有什么样的时序安排或者交错,它必须仍然有如上所述的正确行为,并且在调用的代码中没有任何额外的同步。其效果就是,在所有线程看来,对于线程安全对象的操作是以固定的、全局一致的顺序发生的。
正确性与线程安全性之间的关系非常类似于在描述 ACID(原子性、一致性、独立性和持久性)事务时使用的一致性与独立性之间的关系:从特定线程的角度看,由不同线程所执行的对象操作是先后(虽然顺序不定)而不是并行执行的。
举例
比如一个 ArrayList 类,在添加一个元素的时候,它可能会有两步来完成:1. 在 Items[Size] 的位置存放此元素;2. 增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;
而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增加 Size 的值。
那好,我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。
安全程度
线程安全性不是一个非真即假的命题。 Vector 的方法都是同步的,并且 Vector 明确地设计为在多线程环境中工作。但是它的线程安全性是有限制的,即在某些方法之间有状态依赖(类似地,如果在迭代过程中 Vector 被其他线程修改,那么由 Vector.iterator() 返回的 iterator会抛出ConcurrentModificationException)。
对于 Java 类中常见的线程安全性级别,没有一种分类系统可被广泛接受,不过重要的是在编写类时尽量记录下它们的线程安全行为。
Bloch 给出了描述五类线程安全性的分类方法:不可变、线程安全、有条件线程安全、线程兼容和线程对立。只要明确地记录下线程安全特性,那么您是否使用这种系统都没关系。这种系统有其局限性 -- 各类之间的界线不是百分之百地明确,而且有些情况它没照顾到 -- 但是这套系统是一个很好的起点。这种分类系统的核心是调用者是否可以或者必须用外部同步包围操作(或者一系列操作)。下面几节分别描述了线程安全性的这五种类别。
不可变
不可变的对象一定是线程安全的,并且永远也不需要额外的同步[1] 。因为一个不可变的对象只要构建正确,其外部可见状态永远也不会改变,永远也不会看到它处于不一致的状态。Java 类库中大多数基本数值类如 Integer 、 String 和 BigInteger 都是不可变的。
需要注意的是,对于Integer,该类不提供add方法,加法是使用+来直接操作。而+操作是不具线程安全的。这是提供原子操作类AtomicInteger的原因。
线程安全
线程安全的对象具有在上面“线程安全”一节中描述的属性 -- 由类的规格说明所规定的约束在对象被多个线程访问时仍然有效,不管运行时环境如何排列,线程都不需要任何额外的同步。这种线程安全性保证是很严格的 -- 许多类,如 Hashtable 或者 Vector 都不能满足这种严格的定义。
有条件的
有条件的线程安全类对于单独的操作可以是线程安全的,但是某些操作序列可能需要外部同步。条件线程安全的最常见的例子是遍历由 Hashtable 或者 Vector 或者返回的迭代器 -- 由这些类返回的 fail-fast 迭代器假定在迭代器进行遍历的时候底层集合不会有变化。为了保证其他线程不会在遍历的时候改变集合,进行迭代的线程应该确保它是独占性地访问集合以实现遍历的完整性。通常,独占性的访问是由对锁的同步保证的 -- 并且类的文档应该说明是哪个锁(通常是对象的内部监视器(intrinsic monitor))。
如果对一个有条件线程安全类进行记录,那么您应该不仅要记录它是有条件线程安全的,而且还要记录必须防止哪些操作序列的并发访问。用户可以合理地假设其他操作序列不需要任何额外的同步。
线程兼容
线程兼容类不是线程安全的,但是可以通过正确使用同步而在并发环境中安全地使用。这可能意味着用一个 synchronized 块包围每一个方法调用,或者创建一个包装器对象,其中每一个方法都是同步的(就像 Collections.synchronizedList() 一样)。也可能意味着用 synchronized 块包围某些操作序列。为了最大程度地利用线程兼容类,如果所有调用都使用同一个块,那么就不应该要求调用者对该块同步。这样做会使线程兼容的对象作为变量实例包含在其他线程安全的对象中,从而可以利用其所有者对象的同步。
许多常见的类是线程兼容的,如集合类 ArrayList 和 HashMap 、 java.text.SimpleDateFormat 、或者 JDBC 类 Connection 和 ResultSet 。
线程对立
线程对立类是那些不管是否调用了外部同步都不能在并发使用时安全地呈现的类。线程对立很少见,当类修改静态数据,而静态数据会影响在其他线程中执行的其他类的行为,这时通常会出现线程对立。线程对立类的一个例子是调用 System.setOut() 的类