1) 函数参数
1. 必选参数在前,默认参数在后(多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数)
2. 可变参数:参数前面加了一个*号(在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去);
3. 关键字参数: 参数前面加了个**, (在dict的前加**,dict中所有key-value用关键字参数传入到函数的**变量中,**变量将获得一个dict,注意变量获得的dict是一份拷贝,对变量的改动不会影响到函数外的dict)。
def person(name, age, *, city, job):#(只接收city和job作为关键字参数)
命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了: def person(name, age, *args, city, job):
2)列表生成器
示例:
L1 = ['Hello', 'World', 18, 'Apple', None]
L2 = [i.lower() for i in L1 if isinstance(i,str)]
# 测试:
print(L2)
# 结果:
['hello', 'world', 'apple']
3)生成器与迭代器
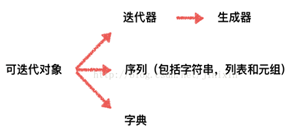
1. 边循环一边计算的机制,称为生成器:generator。
2. 如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator,每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
def odd(): print('step 1') yield 1 print('step 2') yield(3) #结果 >>> o = odd() >>> next(o) step 1 1 >>> next(o) step 2 3 >>> next(o) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
2.可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
4) 高阶函数
1. map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回
In [1]: def f(x): ...: return x*2+1 ...: In [2]: r = map(f, [1,2,3,4,5,6]) In [3]: list(r) Out[3]: [3, 5, 7, 9, 11, 13]
2. reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
In [4]: from functools import reduce >>> def fn(x, y): ...: return x * 10 + y ...: In [5]: reduce(fn, [1,4,6,3]) Out[5]: 1463
小结:利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:
from functools import reduce def str2float(s): def f(x, y): return x * 10 + y def f1(x, y): return x / 10 + y l1, l2 = s.split('.') l2 = l2[::-1] l2 = l2 + '0' s1 = reduce(f, map(int, l1)) s2 = reduce(f1, map(int, l2)) return s1 + s2
3. filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
def createOdd():#产生从3开始的奇数 n = 1 while True: n = n+2 yield n def notDivisible(n):#是否可以分割 return lambda x : x % n != 0 def primes():#产生素数 yield 2 it = createOdd() while True: n = next(it) yield n it = filter(notDivisible(n), it) for n in primes(): if(n < 100): print(n) else: break
4. sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,可以传入第三个参数reverse=True(反向排序):
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) ['Zoo', 'Credit', 'bob', 'about']
****例如:L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
请用sorted()对上述列表分别按名字排序,再按成绩从高到低排序:
def by_name(t): return t[0] def by_score(t): return t[1] #L2 = sorted(L, key=by_name) 注意在sort函数里面的不同用法 #L2 = sorted(L, key=by_score) #print(L2)
5) 返回函数
1. 高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
2. 闭包概念:https://blog.csdn.net/sc_lilei/article/details/80464645
https://www.cnblogs.com/ma6174/archive/2013/04/15/3022548.html
在一个内部函数中,对外部作用域的变量进行引用,(并且一般外部函数的返回值为内部函数),那么内部函数就被认为是闭包。例如:
def lazy_sum(*args): def sum(): ax = 0 for n in args: ax = ax + n return ax return sum
函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
4. 闭包无法修改外部函数的局部变量,或者使用nonlocal关键字,该关键字用来在函数或其他作用域中使用外层(非全局)变。nonlocal用于声明,修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量,如下实例:
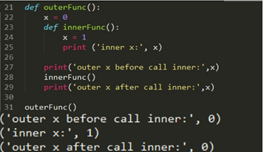
def hellocounter (name): count = 0 def counter(): nonlocal count count += 1 print('Hello,',name,',',str(count) + ' access!') return counter hello = hellocounter('ma6174') hello() hello() hello() # 结果 Hello, ma6174 , 1 access! Hello, ma6174 , 2 access! Hello, ma6174 , 3 access!
2. python循环中不包含域的概念,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
def count(): fs = [] for i in range(1, 4): def f(): return i*i fs.append(f) return fs fl = count() fl
fs在像列表中添加f的时候,并没有保存i的值,而是当执行fl()的时候才去取,这时候循环已经结束,i的值是3,所以结果都是9.修改如下:
def count(): def f(j): def g(): return j*j return g fs = [] for i in range(1, 4): fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f() return fs
def hellocounter (name): count=[0] def counter(): count[0]+=1 print 'Hello,',name,',',str(count[0])+' access!' return counter hello = hellocounter('ma6174') hello() hello() hello() 执行结果 Hello, ysisl , 1 access! Hello, ysisl , 2 access! Hello, ysisl , 3 access!
变量在函数外面声明的话,内部是不能的,除非用nonlocal申明变量在外面,或者global说明这个变量是全局变量;
def line_conf(a, b): def line(x): return a*x + b return line line1 = line_conf(1, 1) line2 = line_conf(4, 5) print(line1(5), line2(5))
我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的直线表达函数。由此,我们可以看到,闭包也具有提高代码可复用性的作用。
如果没有闭包,我们需要每次创建直线函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性。利用闭包,我们实际上创建了泛函。line函数定义一种广泛意义的函数。这个函数的一些方面已经确定(必须是直线),但另一些方面(比如a和b参数待定)。随后,我们根据line_conf传递来的参数,通过闭包的形式,将最终函数确定下来。也就是保存函数的状态信息,使函数的局部变量信息依然可以保存下来。
6)匿名函数
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
L = list(filter(lambda n:n%2, range(1, 20)))
7)装饰器
1.假设我们要增强函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
观察log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数
def log(func): def wrapper(*args, **kw): print('call %s():' % func.__name__) return func(*args, **kw) return wrapper
@logdef now(): print('2015-3-25') #相当于 now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。但是经过decorator装饰之后的函数,它们的__name__已经从原来的'now'变成了'wrapper',所以需要用Python内置的functools.wraps把原函数的属性复制过来。例如:
import functools def log(func): @functools.wraps(func) def wrapper(*args, **kw): print('call %s():' % func.__name__) return func(*args, **kw) return wrapper
8)偏函数
简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,例如
int2 = functools.partial(int, base=2) #相当于: #kw = { 'base': 2 } #int('10010', **kw)
max2 = functools.partial(max, 10) #相当于: #args = (10, 5, 6, 7) #max(*args)
9) 模块
1. 模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- ' a test module ' __author__ = 'Michael Liao' import sys def test(): args = sys.argv #sys.argv 是一个包含命令行参数的列表,只于用命令行窗口运行的时候,
进入文件所在目录,s ys.argv[0] 代表当前module的名字 if len(args)==1: print('Hello, world!') elif len(args)==2: print('Hello, %s!' % args[1]) else: print('Too many arguments!') if __name__=='__main__': test()
注: 第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;任何模块代码的第一个字符串都被视为模块的文档注释;
import 语句: Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN] ##[]表示可选参数
from … import 语句:Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]] ##[]表示可选参数
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3 # Filename: using_name.py if __name__ == '__main__': print('程序自身在运行') else: print('我来自另一模块') 运行输出如下: $ python using_name.py 程序自身在运行$ python >>> import using_name 我来自另一模块
说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
>>> import sys >>> dir(sys) ['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',…………………………]
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
>>> a = [1, 2, 3, 4, 5] >>> import fibo >>> fib = fibo.fib >>> dir() # 得到一个当前模块中定义的属性列表 ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] >>> a = 5 # 建立一个新的变量 'a' >>> dir() ['__builtins__', '__doc__', '__name__', 'a', 'sys'] >>> > >> del a # 删除变量名a >>> dir() ['__builtins__', '__doc__', '__name__', 'sys']
1. 包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。
2. 在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为 __all__变量赋值。
注:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
如果 __all__ 真的没有定义,那么使用from sound.effects import *这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
3. 注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 :exc:ImportError 异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
1.str.format() :括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。在括号中的数字用于指向传入对象在 format() 中的位置,使用了关键字参数, 那么它们的值会指向使用该名字的参数。
>>> import math >>> print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi)) ##:前的数字用于指向传入对象在 format() 中的位置 常量 PI 的值近似为 3.142。
可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。 下面的例子将 Pi 保留到小数点后三位:
>>> import math >>> print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))
##:前的数字用于指向传入对象在 format() 中的位置 常量 PI 的值近似为 3.142。
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> for name, number in table.items():
... print('{0:10} ==> {1:10d}'.format(name, number))
...
Google ==> 1
Runoob ==> 2
Taobao ==> 3
##字符串是左靠齐,数字是右靠齐
2. % 操作符也可以实现字符串格式化。 它将左边的参数作为类似 sprintf() 式的格式化字符串, 而将右边的代入, 然后返回格式化后的字符串. 例如:
>>> import math >>> print('常量 PI 的值近似为:%5.3f。' % math.pi) 常量 PI 的值近似为:3.142。
Python提供了 input() 内置函数从标准输入读入一行文本,默认的标准输入是键盘。
input 可以接收一个Python表达式作为输入,并将运算结果返回。
>>>str = input("请输入:"); >>>print ("你输入的内容是: ", str)
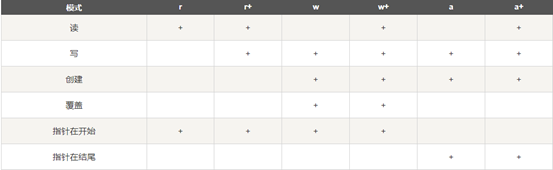
1. open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode) ## mode见下表
https://www.runoob.com/python3/python3-inputoutput.html
https://www.runoob.com/python3/python3-file-methods.html
|
检验权限模式 |
|
改变当前工作目录 |
|
设置路径的标记为数字标记。 |
|
更改权限 |
|
更改文件所有者 |
|
改变当前进程的根目录 |
|
关闭文件描述符 fd |
|
os.closerange(fd_low, fd_high)
关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
|
复制文件描述符 fd |
|
将一个文件描述符 fd 复制到另一个 fd2 |
|
通过文件描述符改变当前工作目录 |
|
改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
|
修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
|
强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
|
os.fdopen(fd[, mode[, bufsize]])
通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
|
返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
|
返回文件描述符fd的状态,像stat()。 |
|
返回包含文件描述符fd的文件的文件系统的信息,Python 3.3 相等于 statvfs()。 |
|
强制将文件描述符为fd的文件写入硬盘。 |
|
裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
|
返回当前工作目录 |
|
返回一个当前工作目录的Unicode对象 |
|
如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
|
设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
|
修改连接文件权限 |
|
更改文件所有者,类似 chown,但是不追踪链接。 |
|
创建硬链接,名为参数 dst,指向参数 src |
|
返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
|
设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
|
像stat(),但是没有软链接 |
|
从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
|
以major和minor设备号组成一个原始设备号 |
|
递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
|
从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
|
以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
|
创建命名管道,mode 为数字,默认为 0666 (八进制) |
|
os.mknod(filename[, mode=0600, device]) 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
|
打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
|
打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
|
返回相关文件的系统配置信息。 |
|
创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
|
os.popen(command[, mode[, bufsize]])
从一个 command 打开一个管道 |
|
从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
|
返回软链接所指向的文件 |
|
删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
|
递归删除目录。 |
|
重命名文件或目录,从 src 到 dst |
|
递归地对目录进行更名,也可以对文件进行更名。 |
|
删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
|
获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
|
os.stat_float_times([newvalue]) 决定stat_result是否以float对象显示时间戳 |
|
获取指定路径的文件系统统计信息 |
|
创建一个软链接 |
|
返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
|
设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
|
返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
|
删除文件路径 |
|
返回指定的path文件的访问和修改的时间。 |
|
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
|
写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
|
获取文件的属性信息。 |
12)命名空间和作用域
1. 命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
5. 内置名称(built-in names): Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
6. 全局名称(global names):模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
7. 局部名称(local names) : 函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
# var1 是全局名称 var1 = 5 def some_func(): # var2 是局部名称 var2 = 6 def some_inner_func(): # var3 是内嵌的局部名称 var3 = 7
Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 ,它将放弃查找并引发一个 NameError 异常。
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
2. 作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
8. L(Local):最内层,包含局部变量,比如一个函数/方法内部。
9. E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
10. G(Global):当前脚本的最外层,比如当前模块的全局变量。
11. B(Built-in): 包含了内建的变量/关键字等。,最后被搜索
g_count = 0 # 全局作用域 def outer(): o_count = 1 # 闭包函数外的函数中 def inner(): i_count = 2 # 局部作用域
注: Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问
内部调用外部变量时,不会改变外部变量的值,当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal(如:闭包)关键字。
a = 10
def test(): a = a + 1 print(a) test() 结果: Traceback (most recent call last): File "test.py", line 7, in <module> test() File "test.py", line 5, in test a = a + 1 UnboundLocalError: local variable 'a' referenced before assignment