第24课 - #pragma 使用分析

1. #pragma简介
(1)#pragma 是一条预处理器指令
(2)#pragma 指令比较依赖于具体的编译器,在不同的编译器之间不具有可移植性,表现为两点:
① 编译器A支持的 #pragma 指令在编译器B中也许并不支持,如果编译器B碰到这条不认识的指令就会忽略它。比如下文中介绍的 #pragma once指令,gcc编译器和VS编译器是支持的,但bcc编译器就不支持。
② 同一条 #pragma指令,不同的编译器可能会有不同的解读。
(3)一般用法:#pragma parameter // 注意,不同的 parameter参数 语法和含义是不同的
2. #pragma message指令
(1)message参数在大多数的编译器中都有相似的实现
(2)message参数在编译时输出消息到编译输出窗口中
(3)message用于条件编译可提示代码的版本信息
(4)与 #error 和 #warning不同,#pragma message仅仅代表一条编译消息,不代表程序错误。
【#pragma使用示例】
1 #include <stdio.h> 2 3 #if defined(ANDROID20) 4 #pragma message("Compile Android SDK 2.0...") 5 #define VERSION "Android 2.0" 6 #elif defined(ANDROID23) 7 #pragma message("Compile Android SDK 2.3...") 8 #define VERSION "Android 2.3" 9 #elif defined(ANDROID40) 10 #pragma message("Compile Android SDK 4.0...") 11 #define VERSION "Android 4.0" 12 #else 13 #error Compile Version is not provided! 14 #endif 15 16 int main() 17 { 18 printf("%s ", VERSION); 19 20 return 0; 21 }
使用 gcc 编译并观察输出结果

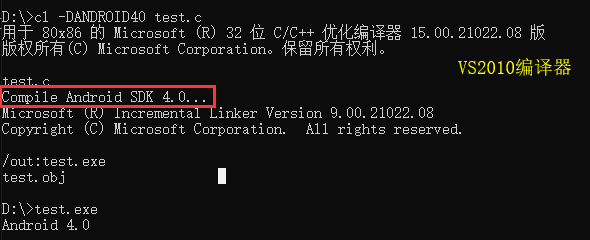
使用VS2010的编译器和BCC编译器分别对上述的示例代码进行编译,可以看到结果和gcc编译器的稍有不同,这也验证了上面说的,不同的编译器对同一条 #pragma 指令会有不同的解读。

使用 gcc -E 24-1.c -DANDROID40 编译代码,发现 #pragma message 并不是在预处理的时候输出的。
# 1 "24-1.c" # 1 "<built-in>" # 1 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 1 "<command-line>" 2 # 1 "24-1.c" # 10 "24-1.c" # 10 "24-1.c" #pragma message("Compile Android SDK 4.0...") # 10 "24-1.c" int main() { return 0; }
此时使用 gcc -S 24-1.c -DANDROID40 编译代码,发现编译报错,说明#pragma message是由编译器(狭义)输出的。
24-1.c:10:13: note: #pragma message: Compile Android SDK 4.0... #pragma message("Compile Android SDK 4.0...") ^
如果程序中有多个 #pragma message,由于编译器对每个c文件是自上而下编译的,所以会自上而下输出。
在做上面这个测试时,很疑惑为什么 #pragma经过预处理器处理后是原样输出,这样为啥还叫预处理指令?
咨询了唐老师,其实是自己钻了牛角尖,这里预处理器的处理方式就是将#pragma原封不动的交给编译器(狭义),不能机械的认为预处理指令完全要预处理器处理。
3. #pragma once指令
(1)#pragma once用于保证头文件只被编译一次
(2)#pragma once是编译器相关的,不一定被支持(下面的示例程序,gcc编译器和VS2010编译器可以编译通过,但BCC32编译器却编译失败)
(3)在第22课分析条件编译时,我们介绍了使用条件编译来防止头文件被多次包含。那 #pragma once 和条件编译有什么区别呢?
参考博客:https://www.hhcycj.com/post/item/383.html (博客截图)

// test.c
1 #include <stdio.h> 2 #include "global.h" 3 #include "global.h" 4 5 int main() 6 { 7 printf("g_value = %d ", g_value); 8 9 return 0; 10 }
// global.h
1 #pragma once 2 3 int g_value = 1;
使用 gcc 编译 ==> 编译通过
swj@ubuntu:~/c_course/ch_24$ gcc test.c swj@ubuntu:~/c_course/ch_24$ ./a.out g_value = 1
使用 VS2010 编译 ==> 编译通过
D:>cl test.c 用于 80x86 的 Microsoft (R) 32 位 C/C++ 优化编译器 15.00.21022.08 版 版权所有(C) Microsoft Corporation。保留所有权利。 test.c Microsoft (R) Incremental Linker Version 9.00.21022.08 Copyright (C) Microsoft Corporation. All rights reserved. /out:test.exe test.obj D:>test.exe g_value = 1
使用 BCC32 编译 ==> 编译失败
D:>bcc32 test.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland test.c: Error E2445 global.h 4: Variable 'g_value' is initialized more than once // g_value重定义 *** 1 errors in Compile ***
BCC32编译器不支持 #pragma once,遇到 #pragma once之后直接忽略它。
在实际工程中,如果既想有效率又想有移植性,那怎么做呢?一般使用如下的做法。
1 #pragma once 2 3 ifndef _HEADER_FILE_H_ 4 #define _HEADER_FILE_H_ 5 6 // source code 7 8 #endif
4. #pragma pack指令
(1)什么是内存对齐?
不同类型的数据在内存中按照一定的规则排列,而不一定是顺序的一个接一个的排列。
我们看下面这个例子,struct Test1 和 struct Test2 的成员都是相同的,只是在结构体中的位置不同,那两个结构体占用的内存大小相同吗?
1 #include <stdio.h> 2 3 #pragma pack(2) 4 struct Test1 5 { 6 char c1; 7 short s; 8 char c2; 9 int i; 10 }; 11 #pragma pack() 12 13 #pragma pack(4) 14 struct Test2 15 { 16 char c1; 17 char c2; 18 short s; 19 int i; 20 }; 21 #pragma pack() 22 23 int main() 24 25 { 26 printf("sizeof(Test1) = %zu ", sizeof(struct Test1)); 27 printf("sizeof(Test2) = %zu ", sizeof(struct Test2)); 28 29 return 0; 30 }
程序的输出结果如下,可见两个结构体的大小并不相同!!!

(2)为什么需要内存对齐?
① CPU对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16...字节
② 当读取操作的数据未对齐,则需要两次总线周期来访问内存,此性能会大打折扣
③ 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则产生硬件异常
(3)#pragma pack( )的功能
#pragma pack( ) 可以改变编译器的默认对齐方式(编译器默认为4字节对齐)
下面我们介绍结构体内存对齐的规则(重要!重要!重要!)
- 第一个成员起始于 0偏移处
- 对齐参数:每个结构体成员按照 其类型大小 和 pack参数 中较小的一个进行对齐(如果该成员也为结构体,那就取其内部长度最大的数据成员作为其大小)
- 偏移地址必须能够被对齐参数整除 (0可以被任何非0的整数整除)
- 结构体总长度必须为所有对齐参数的整数倍
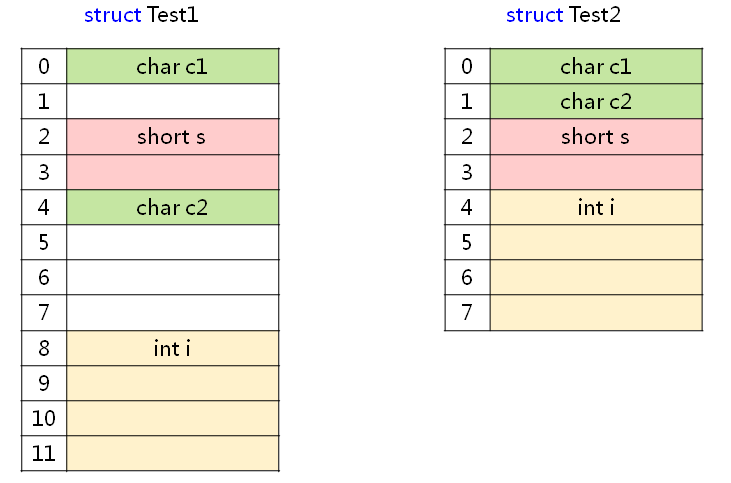
我们根据这个规则来分析一下前面 struct Test1 和 struct Test2 结构体
1 #pragma pack(2) // 以2字节对齐 2 struct Test1 3 { // 对齐参数 偏移地址 大小 4 char c1; // 1 0 1 5 short s; // 2 2 2 6 char c2; // 1 4 1 7 int i; // 2 6 4 8 }; // 在2字节对齐下,该结构体大小为10字节 9 #pragma pack() 10 11 #pragma pack(4) // 以4字节对齐 12 struct Test2 13 { // 对齐参数 偏移地址 大小 14 char c1; // 1 0 1 15 char c2; // 1 1 1 16 short s; // 2 2 2 17 int i; // 4 4 4 18 }; // 在4字节对齐下,该结构体大小为8字节 19 #pragma pack()
分析结果和前面程序的输出结果相同,结构体成员在内存中的位置如下图所示:
上面这个例子比较简单,我们再来看一下微软的一道笔试题
1 #include <stdio.h> 2 3 #pragma pack(8) // 以8字节对齐 4 struct S1 5 { // 对齐参数 偏移地址 大小 6 short a; // 2 0 2 7 long b; // 8 8 8 8 }; // 在8字节对齐下,该结构体大小为16字节 9 10 struct S2 // 结构体中包含了一个结构体成员,取其内部长度最大的数据成员作为其大小 11 { // 对齐参数 偏移地址 大小 12 char c; // 1 0 1 13 struct S1 d; // 8 8 16 14 double e; // 8 24 8 15 }; // 在8字节对齐下,该结构体大小为32字节 16 #pragma pack() 17 18 int main() 19 { 20 printf("%d ", sizeof(struct S1)); 21 printf("%d ", sizeof(struct S2)); 22 23 return 0; 24 }
使用gcc编译,程序执行结果如下,和我们分析的结果相同

【这里和唐老师课程中的结果不同,唐老师使用的编译器不支持8字节对齐,即 #pragma pack(8),我的这个gcc支持。】
我们再使用 VS2010编译器 和 BCC32编译器 测试一下上面的代码
VS2010编译器
D:>cl test.c 用于 80x86 的 Microsoft (R) 32 位 C/C++ 优化编译器 15.00.21022.08 版 版权所有(C) Microsoft Corporation。保留所有权利。 test.c Microsoft (R) Incremental Linker Version 9.00.21022.08 Copyright (C) Microsoft Corporation. All rights reserved. /out:test.exe test.obj D:>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4 8 24
BCC32编译器
D:>bcc32 test.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland test.c: Turbo Incremental Link 5.00 Copyright (c) 1997, 2000 Borland D:>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4 8 24