1.概述
一个region server上的所有region共用一个Hlog, hlog用来在系统异常down掉,MemStore中大量更新丢失时,对数据进行恢复。
然而,对每个region的更新在hlog里不是连续的,而是分散在Hlog里的。Hlog中的每项更新都会记录该更新所属的region, HBase要通过在每个region上应用hlog中的更新来恢复数据,因此需要把hlog中的更新按照region分组,这一把hlog中更新日志分组的过程就称为log split(日志分割)。
所谓的log split 是将一个WAL文件,按照不同的region拆分成为多个文件,每个文件里面只是包含一个region内容。log split发生在启动一个region server之前。
根据实现的不同,Hbase的日志切分分为三种模式:
- Log Splitting :效率极差,需要几个小时
- Distributed Log Splitting
- Distributed Log Replay
2.Log splitting
2.1触发的时机:
-
日志拆分(Log Split)发生在集群启动时(由HMaster负责完成)
-
在region server崩溃时(由ServerShutdownHandler负责完成)
在日志拆分时,受影响的region将不可用,直到拆分完成,数据完全重置。
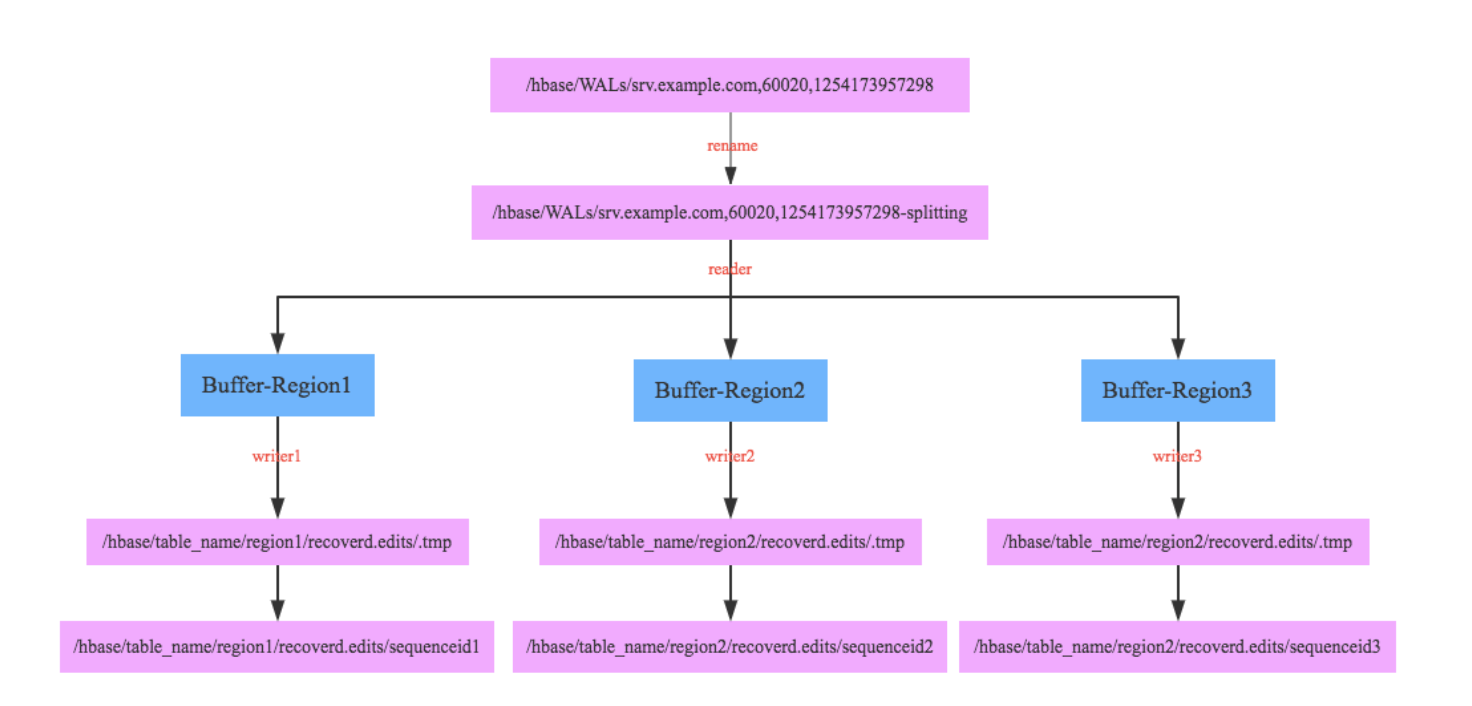
下图为日志拆分的过程:

Step1: rename log dir
将对应的region server的目录重命名,这样是为了确保不会出现如果master认为region server挂掉但是实际上region server还在serve的情况。重命名为 hbase.logs/
Step2: start write threads
启动多个线程来写(如果存在多个文件的话也可以使用多个线程来读取),但是事实上这样效率依然不高,因为存在很多机器空闲。
Step3: read edits from each log file, put edit entries in buffers, writers write edits to edits files.
读线程来进行拆分,将需要write的内容丢给写线程完成。
- 每个线程写入的文件为/hbase/<table_name>/<region_id>/recovered.edits/.temp
- 一旦写成功之后就会重命名为/hbase/<table_name>/<region_id>/recovered.edits/
,其中sequenceid是最后一条写入这个file的log对应的unique operation id.
Step4:close writers
关闭写线程以及对应的HDFS文件。
Step5: 指定新的region server来serve某些region,并且读取这个region对应的HDFS看是否有恢复文件,如果存在恢复文件的话那么就需要进行replay.
2.2.开启日志分割
/opt/mapr/hbase/hbase-
<property>
<name>hbase.master.distributed.log.splitting</name>
<value>true</value>
</property>
3.Distributed log splitting
机制非常简单,就是将所有需要被splitting的WAL分布式并行地来完成。首先将这些文件全部放在zookeeper上面,然后cluster里面的机器可以上去认领自己来进行split那个日志,当然也要考虑这个机器在split日志的时候自己挂掉的情况。

Hbase master 重启的时候,可以通过web UI 观察到hlog splitting task。

-
Master会将待切分日志路径发布到Zookeeper节点上(/hbase/splitWAL),每个日志作为一个任务,每个任务都会有对应状态,起始状态为TASK_UNASSIGNED
-
所有RegionServer启动之后都注册在这个节点上等待新任务,一旦Master发布任务之后,RegionServer就会抢占该任务
-
抢占任务实际上首先去查看任务状态,如果是TASK_UNASSIGNED状态,说明当前没有人占有,此时就去修改该节点状态为TASK_OWNED。如果修改失败,说明其他RegionServer也在抢占,修改成功表明任务抢占成功。
-
RegionServer抢占任务成功之后会分发给相应线程处理,如果处理成功,会将该任务对应zk节点状态修改为TASK_DONE,一旦失败会修改为TASK_ERR
-
Master会一直监听在该ZK节点上,一旦发生状态修改就会得到通知。任务状态变更为TASK_ERR的话,Master会重新发布该任务,而变更为TASK_DONE的话,Master会将对应的节点删除。
下图是RegionServer抢占任务以及抢占任务之后的工作流程:
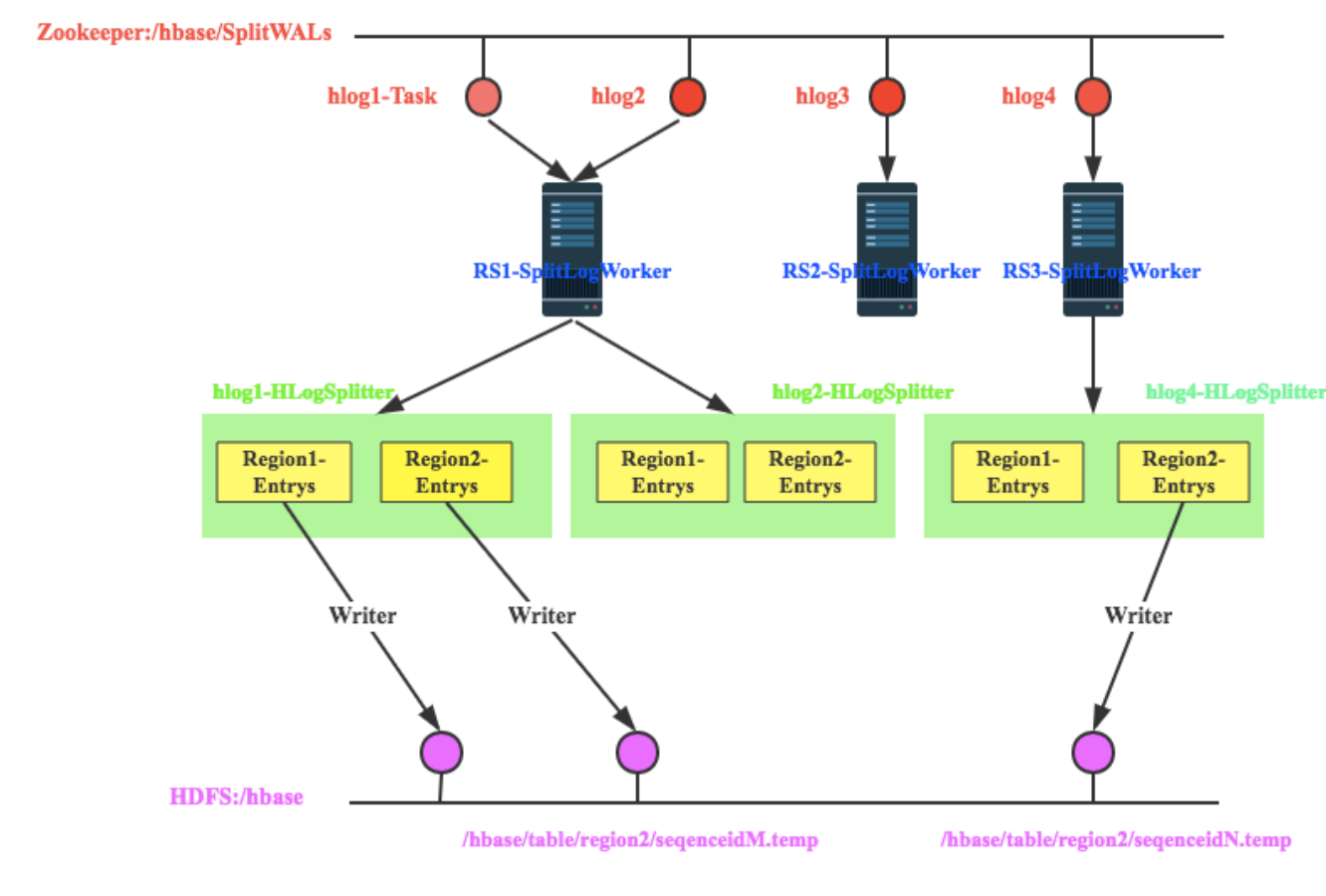
-
假设Master当前发布了4个任务,即当前需要回放4个日志文件,分别为hlog1、hlog2、hlog3和hlog4
-
RegionServer1抢占到了hlog1和hlog2日志,RegionServer2抢占到了hlog3日志,RegionServer3抢占到了hlog4日志
-
以RegionServer1为例,其抢占到hlog1和hlog2日志之后会分别分发给两个HLogSplitter线程进行处理,HLogSplitter负责对日志文件执行具体的切分,切分思路还是首先读出日志中每一个<HLogKey, WALEdit>数据对,根据HLogKey所属Region写入不同的Region Buffer
-
每个Region Buffer都会有一个对应的写线程,将buffer中的日志数据写入hdfs中,写入路径为/hbase/table/region2/seqenceid.temp,其中seqenceid是一个日志中某个region对应的最大sequenceid
-
针对某一region回放日志只需要将该region对应的所有文件按照sequenceid由小到大依次进行回放即可。
4.Distributed Log Replay

相比Distributed Log Splitting方案,流程上的改动主要有两点:先重新分配Region,再切分回放HLog;Region重新分配打开之后状态设置为recovering,核心在于recovering状态的Region可以对外提供写服务,不能提供读服务,而且不能执行split、merge等操作。
DLR的HLog切分回放基本框架类似于Distributed Log Splitting,但它在分解完HLog为Region-Buffer之后并没有去写入小文件,而是直接去执行回放。这样设计可以大大减少小文件的读写IO消耗,解决DLS的切身痛点。
果不写小文件,很难在分布式环境下对sequenceid进行排序,这里就有一个问题,不按顺序对HLog进行回放会不会出现问题?这个问题可以分为下面两个层面进行讨论:
-
不同时间更新的相同rowkey,不按顺序回放会不会有问题?比如WAL1中有<rowkey, t1>,WAL2中有<rowkey,t2>,正常情况下应该先回放<rowkey,t1>对应的日志数据,再回放<rowkey,t2>对应的日志数据,如果顺序颠倒会不会有问题?
第一眼看到这样的问题觉得一定不行啊,正常情况下<rowkey,t2>对应的日志数据才是最后的真正数据,一旦颠倒之后不就变成<rowkey,t1>对应的日志数据了。
这里需要关注更新时间的概念,rowkey回放时,如果写入时间戳定义为回放时间的话,肯定会有异常的。但是如果回放日志数据的时候rowkey写入时间戳被定义为当时rowkey数据写入日志的时间的话,就正常了。按照上面例子,顺序即使颠倒,先写<rowkey,t2>再写<rowkey,t1>,但是写入数据的时间戳(版本)依然保持不变时t2和t1的话,最大版本数据还是<rowkey,t2>,用户读取最新数据依然是<rowkey,t2>,和回放顺序并没有关系。
-
相同时间戳更新的相同rowkey,不按顺序回放会不会有问题?比如WAL1中有<rowkey, t0>,WAL2中有<rowkey,t0>,正常情况下也应该先回放前者,再回放后者,如果顺序颠倒会不会有问题?为什么同一时间会有多条相同rowkey的写入更新,而且还在不同的日志文件中?大家肯定会有这样的疑问。问题中‘同一时间’的单位是ms,在很多写入吞吐量很大的场景下同一毫秒写入大量数据并不是不可能,那先后写入两条相同rowkey的数据也必然可能,至于为什么在不同文件,假如刚好第一次更新完rowkey的时候日志截断了,第二次更新就会落入下一个日志。
那这种情况下前后两次更新时间戳还一致,颠倒顺序就办法分出哪个版本大了呀!莫慌,不是还有sequenceid~,只要在回放的时候将日志数据原生sequenceid也一同写入,不就可以在时间戳相同的情况下根据sequenceid进行判断了。具体实现只需要写入一个replay标示(用来表示该数据时回放写入)和相应的sequenceid,用户在读取的时候如果遇到两个都带有replay标示而且rowkey、cf、column、时间戳都相同的情况,还需要比较sequenceid就可以分辨出来哪个数据版本更大。
参考:
http://hbase.apache.org/book.html#regionserver.arch
https://blog.csdn.net/chicm/article/details/40952563