今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习。话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的。
python环境:python3.5
先看看网页的样子
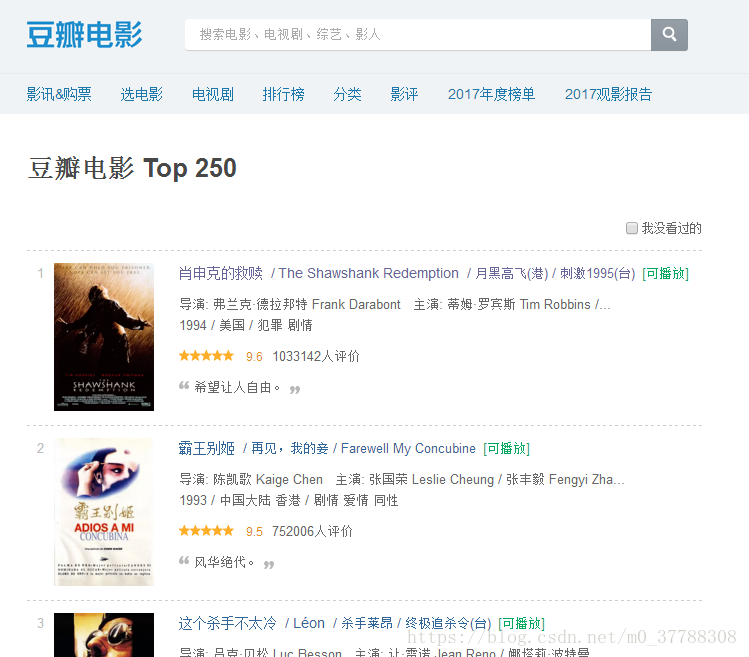
我们下面将要对电影的名字、链接、评分、评价人数和一句话描述这些信息进行提取
1、检查并复制电影名字的xPath信息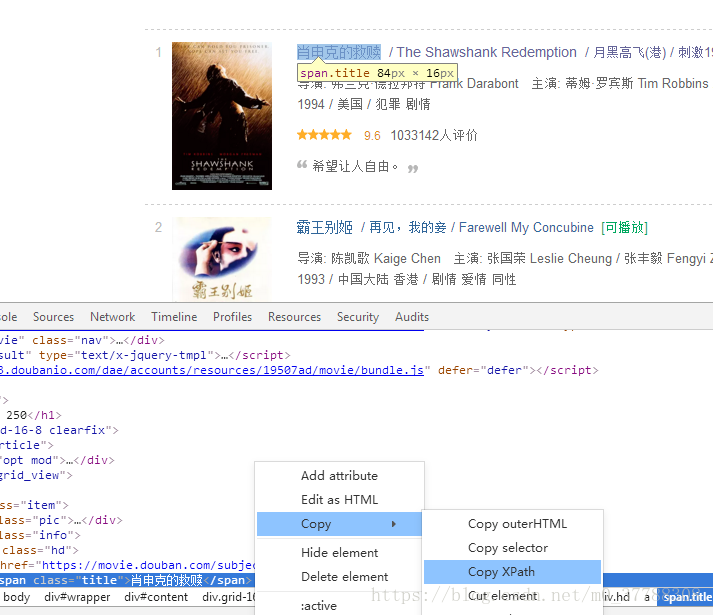
电影《肖申克的救赎》的xPath信息如下:
//*[@id=”content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
按照爬虫的代码套路来一波
from lxml import etree
import requests
def get_1_name():
'''
爬取豆瓣top250电影的第1个电影的名字
:return:
'''
url = 'https://movie.douban.com/top250' # #豆瓣top250网址
data = requests.get(url).text # #得到html内容
s = etree.HTML(data) # #etree.HTML用来解析html内容
xpath_test = '//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]'+'/text()' # #谷歌浏览器中选中文字,右键检查,复制xpath
title = s.xpath(xpath_test)[0] # #列表只有一个元素
print(title)
输出结果: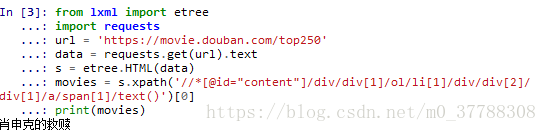
第六行代码最后加[0],是因为不加的话,返回的则会是一个列表,不好看。
2、对同一页的不同电影名字进行提取
根据《肖申克的救赎》同方法对《霸王别姬》、《这个杀手不太冷》和《阿甘正传》的xPath信息比较:
比较可以发现电影名的xPath信息仅仅li后面的序号不一样,并且和电影名的序号一样,所以去掉序号以后,就可以得到通用的xPath信息
//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]
接下来我们把这一页的电影名字个爬下来
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
title = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for movies in title:
print(movies)
输出结果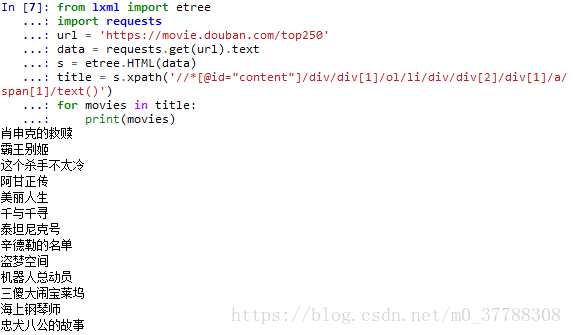
下面用类似的方法对电影评分进行提取
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
for i in score:
print(i)
输出结果为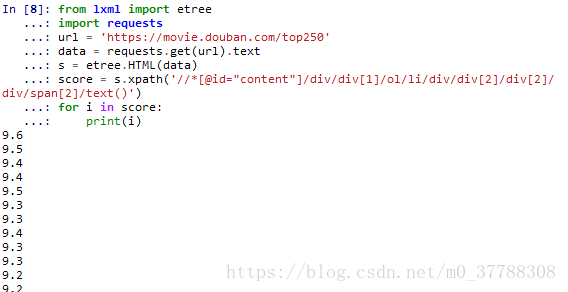
接下来要做的是输出电影及对应的评分
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
for i in range(25):
print("{} {}".format(file[i],score[i]))
输出结果为:
这里我们默认电影名字以及评分都是完整的、正确的信息,这种默认一般情况下是没问题的。但其实是有缺陷的。如果我们少爬了或者多爬了信息,就会发生匹配的错误,那么该怎么避免这种错误呢?
仔细思考下,发现我们若是以电影名字为单位,分别获取对应的信息,那么匹配肯定完全正确。
电影名字的标签肯定在这部电影的框架内,于是我们从电影名字的标签往上找,发现覆盖整部电影的标签,把xPath信息复制下来
//*[@id="content"]/div/div[1]/ol/li[1]
然后我们将整部电影和其他信息的xPath信息进行比较
//*[@id="content"]/div/div[1]/ol/li[1]
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
//*[@id="content"]/div/div[1]/ol/li[2]/div/div[2]/div[2]/div/span[2]
不难发现电影名和评分的前半部分与整部电影的前半部分是一样的。那我们就可以这样写xPath的方式来定位信息:
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li[1]')
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')
在实际的代码中体验一下
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li[1]')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
print("{} {}".format(movies_name,movies_score))
输出结果为
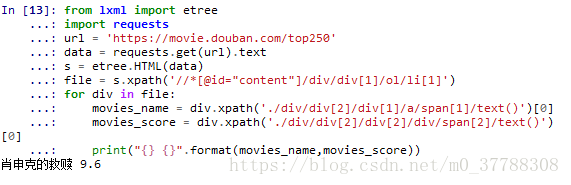
上面我们爬取了一部电影的信息,那么怎么爬取这一页的呢?很简单把li后面的[1]去掉就可以了。来看看新的代码
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
print("{} {}".format(movies_name,movies_score))
结果为: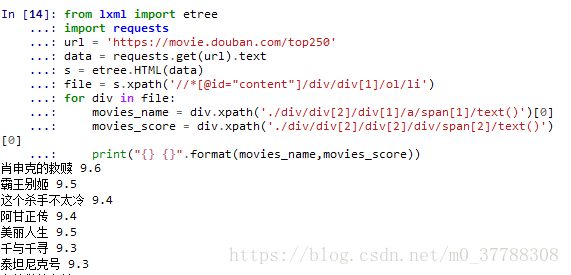
其他信息的提取与之类似,就不在细讲了,代码跑一遍
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
movies_href = div.xpath('./div/div[2]/div[1]/a/@href')[0]
movies_number = div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip("(").strip( ).strip(")")
movie_scrible = div.xpath('./div/div[2]/div[2]/p[2]/span/text()')
print("{} {} {} {} {}".format(movies_name,movies_href,movies_score,movies_number,movie_scrible[0]))
结果为: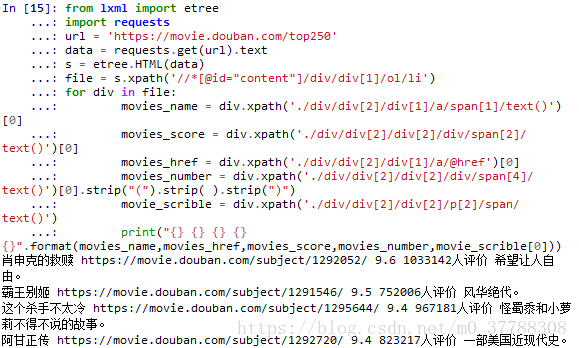
这样我们就对第一页的信息进行了提取,那么我么怎么把所有的页都提取呢?比较一下不同页的URL
第一页:https://movie.douban.com/top250?start=0
第二页:https://movie.douban.com/top250?start=25
第三页:https://movie.douban.com/top250?start=50
第四页:https://movie.douban.com/top250?start=75
......
URL的变化规律很简单,只是start=()的数字不一样,以25为单位递增,所以写个循环就可以了,下面把整个代码跑一下,所有25页的信息全部提取下来。
from lxml import etree
import requests
import time
for a in range(10):
url = 'https://movie.douban.com/top250?start={}'.format(a*25)
data = requests.get(url).text
# print(data)
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
movies_href = div.xpath('./div/div[2]/div[1]/a/@href')[0]
movies_number = div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip("(").strip( ).strip(")")
movie_scrible = div.xpath('./div/div[2]/div[2]/p[2]/span/text()')
# time.sleep(1)
if len(movie_scrible)>0:
print("{} {} {} {} {}".format(movies_name,movies_href,movies_score,movies_number,movie_scrible[0]))
else:
print("{} {} {} {}".format(movies_name,movies_href,movies_score,movies_number))
结果为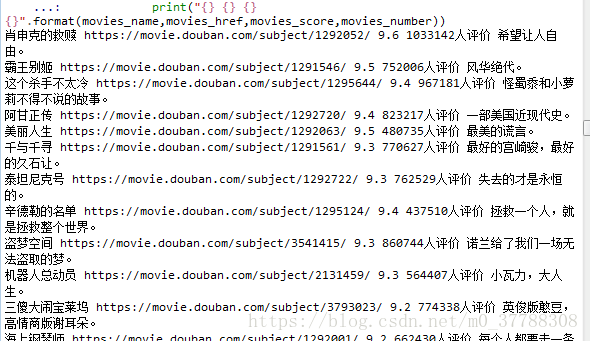
这只是一部分截图,整体的包含了250部电影。
注:这里加了个if语句,是因为发现有的电影没有一句话描述。Ok了,这个爬虫很简单,也是我刚开始学习xPath,适合新手学习
---------------------
作者:云南省高校数据化运营管理工程研究中心
来源:CSDN
原文:https://blog.csdn.net/m0_37788308/article/details/80378042
版权声明:本文为博主原创文章,转载请附上博文链接!