1.无向图
两种常用的图的表示方法:邻接矩阵和邻接表。
所谓的邻接矩阵的存储,就是用一个一维数组存储图中顶点的信息,用一个二维数组存储图中边的信息(即各顶点之间的邻接关系),存储顶点之间邻接关系的二维数组称为邻接矩阵。
所谓的邻接表的存储,就是使用一个以顶点为索引的列表数组,其中的每个元素都是和该顶点相邻的顶点列表。——下边我们全都使用邻接表的方式。
1.1深度优先搜索
深度优先搜索类似于树的先序遍历。尽可能的深。用栈实现。时间复杂度O(|v|+|e|)。深度优先生成树如下图所示:
1.2广度优先搜索
广度优先搜索类似于树的层序遍历。用队列实现。时间复杂度O(|v|+|e|)。深度优先生成树如下图所示:

1.3两种搜索方式总结
深度优先搜索可以解决:检测图是否连通,单点路径问题(搜索树就是路径),检测图是否有环,检测是否是二分图,……
广度优先搜索可以解决:检测图是否连通,求解单源最短路径问题,……
注意:深度优先搜索可以解决单点路径问题(只是求出路径而已),但是不能求最短的路径。
2.有向图
单点可达性。给定一副有向图和一个起点s,回答:是否存在一条从s到达给定顶点v的有向路径?
多点可达性。给定一幅有向图和顶点的集合,回答:是否存在一条从所有集合中人任意顶点到达给定顶点v的有向路径?——对集合中每个顶点进行深度优先搜索
多点可达性的重要应用是在典型的内存管理系统中,包括Java的实现,在一幅有向图中,一个顶点表示一个对象,一条边表示一个对象对另一个对象的引用。
2.1拓扑排序
拓扑排序——给定一幅有向图,将所有的顶点排序,使得所有的有向边均从排列在前面的元素指向排列在后面的元素(或者说无法做到这一点)。
有向环检测。——深度优先搜索,一旦找到一条有向边v→w且w已经存在于栈中,就找到了一个环,因为栈表示的是一条w到v的有向路径,而v→w正好补全这个环。
当且仅当一幅有向图是无环图时它才能进行拓扑排序。
2.1.1基于深度优先搜索的拓扑排序
深度优先搜索的三种排序:
前序:在递归调用之前将节点加入队列。
后序:在递归调用之后将顶点加入队列。
逆后序:在递归调用之后将节顶点压入栈。
一幅有向无环图的拓扑顺序即为所有顶点的逆后序排列。证明如下:

图示如下:

步骤:
1.用深度优先搜索判断是否有环;
2.用深度优先搜索求图的逆后续排列。
2.2.2基于队列的拓扑排序
步骤:
1.将图中所有入度为0的节点加入队列;
2.从队列中选择一个入度为0的节点,将该节点并输出;
3.从队列中删除该节点和所有以它为起点的有向边,并将这些边的入度减一,将入度为0的节点加入队列;
4.重复2和3步骤,直到图为空或当前图不存在无前驱的顶点为止。而后一种情况则说明有向图中必然存在环。
2.2有向图的强连通性——Kosarju算法
如果两个顶点v和w是互相可达的,就称他们为强连通的。
应用举例:
强连通分量可以帮助教科书作者决定哪些话题可以归为一类;
强连通分量可以帮助生物学家理解食物链的能量流动;
……
Kosaraju算法、Tarjan算法、Gabow算法皆为寻找有向图强连通分量的有效算法。但是在Tarjan 算法和 Gabow 算法的过程中,只需要进行一次的深度优先搜索,而Kosaraju算法需要两次DFS,因而相对 Kosaraju 算法较有效率。这些算法可简称为SSC(strongly connected components)算法;
Kosaraju 算法为《算法导论》和《算法 第四版》书中给出的算法,比较直观和易懂。这个算法可以说是最容易理解,最通用的算法,其比较关键的部分是同时应用了原图G和反图GT。 它利用了有向图的这样一个性质,一个图和他的transpose graph(边全部反向)具有相同的强连通分量!
Kosarju算法步骤:
1.在给定的一幅有向图G中,使用深度优先搜索来计算它的反向图GR的逆后序排列;
2.在G中进行标准的深度优先搜索,但是要按照刚才计算得到的顺序而非标准的顺序来访问所有未被标记的顶点;
3.所有在同一个递归中调用中被访问到的顶点都在同一个强连通分量中。

可以这儿通俗的想:

参考:
http://baike.baidu.com/link?url=c-wScoYqABTf66S2R69ix3fgNblLyKelKgUSLkhwLpYsgXuD32pqHTYI6VlWknCeQqXYw8ryWPZ67F1B4OLf9tdFxiLcJwwWnjGSWedoyeWuPVn0bBBF9SLtpQQ8ELMsN-CTJfbFKLZCUYerQV-VqK
http://www.acmerblog.com/strongly-connected-components-6099.html
http://m.blog.csdn.net/article/details?id=45692005
《算法 第四版》
《王道 联考复习指导2014》
《算法导论》
3.最小生成树
加权图是一种为每条边关联一个权值或是成本的图模型。这种图能够自然的表示许多应用。在一幅航空图中,边表示航线,权值则可以表示距离或是费用。在一幅电路图中,边表示导线,权值则可以表示成导线的长度即成本,或是信号通过这条线路所需要的时间。
切分:图的一种切分是将图的所有顶点分为两个非空且不重叠的两个集合。横切边是一条连接两个属于不同集合的顶点的边。
切分定理:在一幅加权图中,给定任意的切分,它的横切边中的权重最小者必须属于图的最小生成树。
切分定理是解决最小生成树问题的所有算法的基础。更确切的说,这些算法都是一种贪心算法的特殊情况;使用切分定理找到最小生成树的一条边,不断重复知道找到最小生成树的所有边。
3.1 Prim算法
prim算法的每一步都会为一棵成长中的树添加一条边。一开始这棵树只有一个顶点,然后会向它添加V-1条边,每次总是将下一条连接树中的顶点与不在树中的顶点且权重最小的边加入树中。
每当我们向树中添加一条边之后,也向树中添加了一个顶点。要维护一个包含所有横切边的集合,就要将连接这个顶点和其他所有不在树中的顶点的边加入优先队列。这里有两种方法:延迟实现和即时实现。
延迟实现:加入节点的同时,就把不在树中节点与该节点的所有边加入优先队列中。时间复杂度:ElogE(最坏情况)
延迟实现:加入优先队列的边有限制,把所有不在树中的节点与树的最短距离的边都加入优先队列中,将在优先队列中不满足这个条件的边删除掉。时间复杂度:ElogV(最坏情况)

3.2 Kuskal算法
Kuskal算法主要思想是按照边的权重顺序(从小到大)处理它们,将边加入最小生成树中,加入的边不会与已经加入的边构成环,直到树中含有V-1条边为止。
Prim算法是一条边一条边地来构造最小生成树,每一步都为一棵树添加一条边。Kuskal算法也是一条边一条边地构造,但不同的是它寻找的边会连接一片森林中的两棵树。直到最后只剩下一棵树,它就是最小生成树。时间复杂度:ElogE(最坏情况)
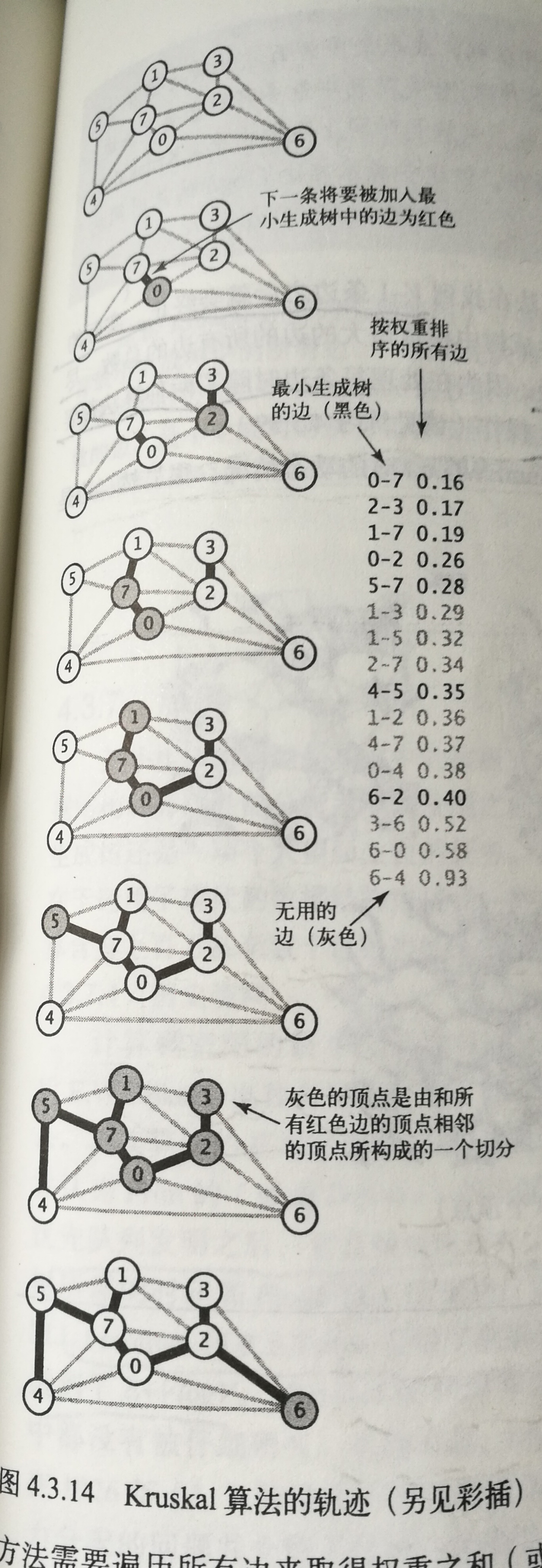
Kruskal算法比Prim算法要慢,因为Kruskal算法还要对不同的树进行连接操作。
目前还没有理论能够证明,不存在能在限行时间内得到任意图的最小生成树的算法。但是目前没有找到线性时间内的方法。
总的来说,我们可以认为实际应用中最小生成树的问题已经被“解决”了。对于大多数图来说,找到它的最小生成树的成本只比遍历图的所有边稍高一点。除了极为稀疏的图,这一点都能成立。