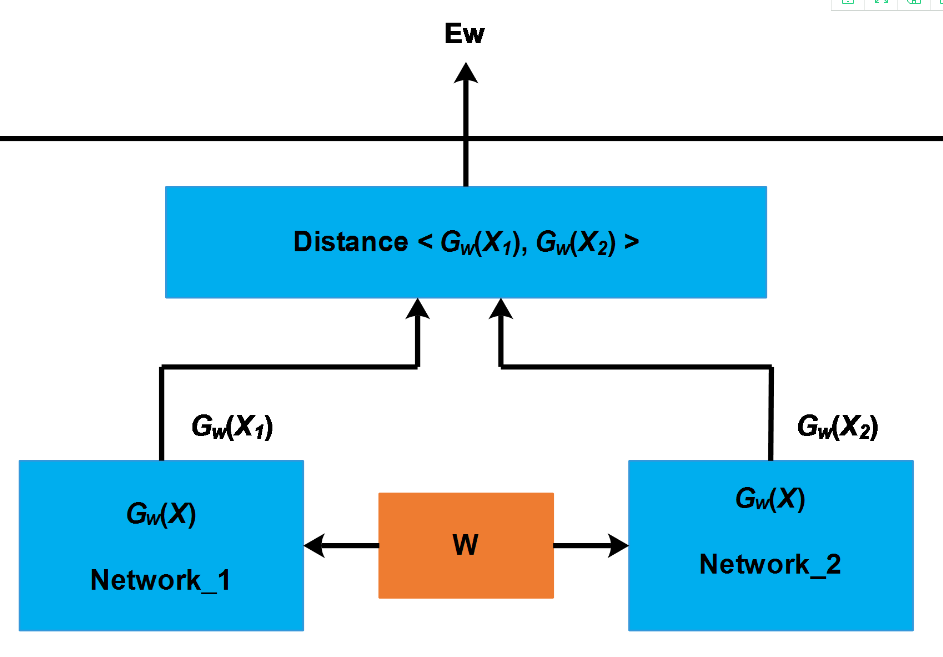
sianese_network用来判断文本相似度的一个网络,主要是用来判断两个文章的相似度的。
判断两个橘子的区别:
双层lstm:

文件1:人名匹配的是正例,随机配对的是负例。
文件2:两句话,句子级别比人名难一些,首先要对词进行词向量编码(不用训练,市面上很多,直接拿来用就可以了)
如何构造这个网络?
损失函数:
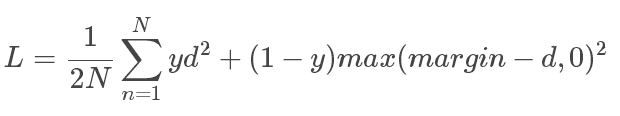
d表示的是欧式距离
第一种情况:y=1,说明两个样本相似的,加号后边的就为0,左边就是只和d(距离)有关了,所以相当于用距离来作为损失
第二种情况:y=0,说明两个样本不相似,加号左边为0,margin为1,即1-d,我们希望他们的距离越大越好,距离越接近1越好,这样损失函数就越小。
总结:相似样本,距离越接近0越好;不相似样本,距离越接近1越好。