1. 为网络的不同部分指定不同的学习率
1 class LeNet(t.nn.Module): 2 def __init__(self): 3 super(LeNet, self).__init__() 4 self.features = t.nn.Sequential( 5 t.nn.Conv2d(3, 6, 5), 6 t.nn.ReLU(), 7 t.nn.MaxPool2d(2, 2), 8 t.nn.Conv2d(6, 16, 5), 9 t.nn.ReLU(), 10 t.nn.MaxPool2d(2, 2) 11 ) 12 # 由于调整shape并不是一个class层, 13 # 所以在涉及这种操作(非nn.Module操作)需要拆分为多个模型 14 self.classifier = t.nn.Sequential( 15 t.nn.Linear(16*5*5, 120), 16 t.nn.ReLU(), 17 t.nn.Linear(120, 84), 18 t.nn.ReLU(), 19 t.nn.Linear(84, 10) 20 ) 21 22 def forward(self, x): 23 x = self.features(x) 24 x = x.view(-1, 16*5*5) 25 x = self.classifier(x) 26 return x
这里LeNet被拆解成features和classifier两个模型来实现。在训练时,可以为features和classifier分别指定不同的学习率。
1 model = LeNet() 2 optimizer = optim.SGD([{'params': model.features.parameters()}, 3 {'params': model.classifier.parameters(), 'lr': 1e-2} 4 ], lr = 1e-5)
对于{'params': model.classifier.parameters(), 'lr': 1e-2} 被指定了特殊的学习率 'lr': 1e-2,则按照该值优化。
对于{'params': model.features.parameters()} 没有特殊指定学习率,则使用 lr = 1e-5。
SGD的param_groups中保存着 'params', 'lr', 'momentum', 'dampening','weight_decay','nesterov'及对应值的字典。
在 CLASS torch.optim.Optimizer(params, defaults) 中,提供了 add_param_group(param_group) 函数,可以在optimizer中添加param group. 这在固定与训练网络模型部分,fine-tuning 训练层部分时很实用。
2. 动态调整网络模块的学习率
1 for p in optimizer.param_groups: 2 p['lr'] = rate()
如果需要动态设置学习率,可以以这种方式,将关于学习率的函数赋值给参数的['lr']属性。
还以以上定义的LeNet的optimizer为例,根据上面的定义,有两个param_groups, 一个是model.features.parameters(), 一个是{'params': model.classifier.parameters()。
那么在for的迭代中,可以分别为这两个param_group通过函数rate()实现动态赋予学习率的功能。
如果将optimizer定义为:
optimizer = optim.SGD(model.parameters(), lr = 0.001, momentum = 0.9)
那么param_groups中只有一个param group,也就是网络中各个模块共用同一个学习率。
3. 使用pytorch封装好的方法
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
torch.optim.lr_scheduler中提供了一些给予epochs的动态调整学习率的方法。
https://www.jianshu.com/p/a20d5a7ed6f3 这篇blog中绘制了一些学习率方法对应的图示。
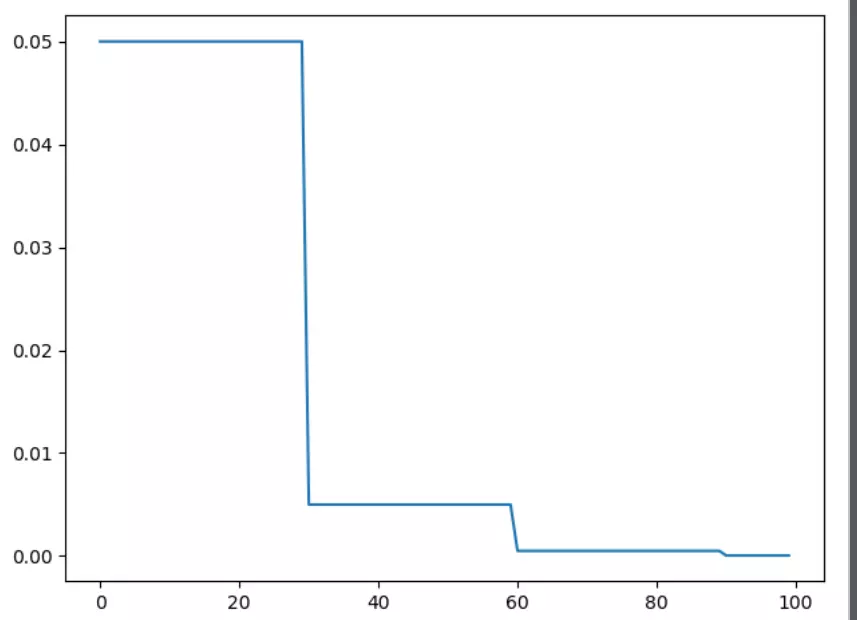
1)torch.optim.lr_scheduler.StepLR
1 import torch 2 import torch.optim as optim 3 from torch.optim import lr_scheduler 4 from torchvision.models import AlexNet 5 import matplotlib.pyplot as plt 6 7 model = AlexNet(num_classes=2) 8 optimizer = optim.SGD(params=model.parameters(), lr=0.05) 9 10 # lr_scheduler.StepLR() 11 # Assuming optimizer uses lr = 0.05 for all groups 12 # lr = 0.05 if epoch < 30 13 # lr = 0.005 if 30 <= epoch < 60 14 # lr = 0.0005 if 60 <= epoch < 90 15 16 scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1) 17 plt.figure() 18 x = list(range(100)) 19 y = [] 20 for epoch in range(100): 21 scheduler.step() 22 lr = scheduler.get_lr() 23 print(epoch, scheduler.get_lr()[0]) 24 y.append(scheduler.get_lr()[0]) 25 26 plt.plot(x, y)
2)torch.optim.lr_scheduler.MultiStepLR
与StepLR相比,MultiStepLR可以设置指定的区间
1 # --------------------------------------------------------------- 2 # 可以指定区间 3 # lr_scheduler.MultiStepLR() 4 # Assuming optimizer uses lr = 0.05 for all groups 5 # lr = 0.05 if epoch < 30 6 # lr = 0.005 if 30 <= epoch < 80 7 # lr = 0.0005 if epoch >= 80 8 print() 9 plt.figure() 10 y.clear() 11 scheduler = lr_scheduler.MultiStepLR(optimizer, [30, 80], 0.1) 12 for epoch in range(100): 13 scheduler.step() 14 print(epoch, 'lr={:.6f}'.format(scheduler.get_lr()[0])) 15 y.append(scheduler.get_lr()[0]) 16 17 plt.plot(x, y) 18 plt.show()

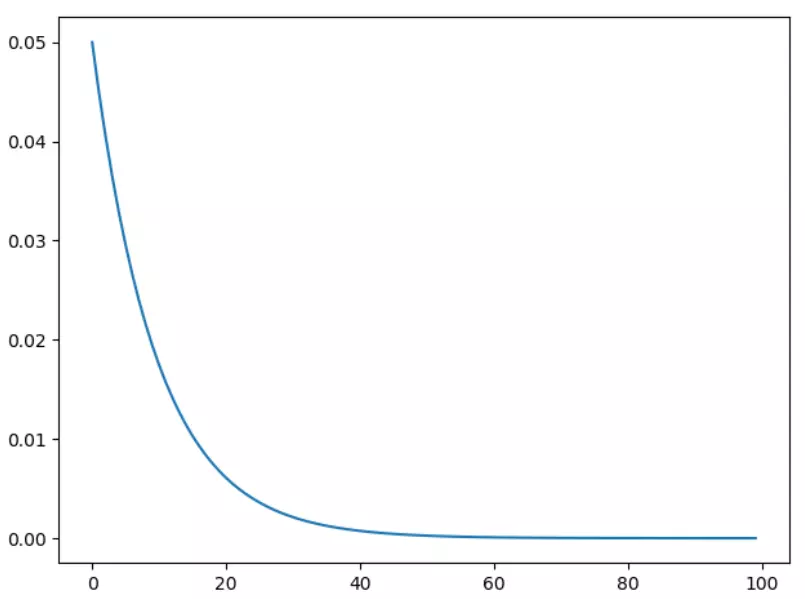
3)torch.optim.lr_scheduler.ExponentialLR
指数衰减
1 scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9) 2 print() 3 plt.figure() 4 y.clear() 5 for epoch in range(100): 6 scheduler.step() 7 print(epoch, 'lr={:.6f}'.format(scheduler.get_lr()[0])) 8 y.append(scheduler.get_lr()[0]) 9 10 plt.plot(x, y) 11 plt.show()