hadoop的核心
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,Hadoop旗下有很多经典子项目,比如HBase、Hive等,这些都是基于HDFS和MapReduce发展出来的。要想了解Hadoop,就必须知道HDFS和MapReduce是什么。
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
MapReduce
通俗说MapReduce是一套从海量·源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
Hadoop安装教程分布式配置_CentOS6.5/Hadoop2.6.5
1 创建hadoop用户
su # 上述提到的以 root 用户登录 # useradd -m hadoop -s /bin/bash # 创建新用户hadoop
如下图所示,这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为shell。
# passwd hadoop
修改用户的密码
# visudo
为用户增加管理员权限
如下图,找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示:
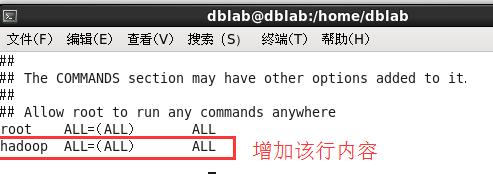
添加好内容后,先按一下键盘上的 ESC 键,然后输入 :wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
最后注销当前用户(点击屏幕右上角的用户名,选择退出->注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。(如果已经是 hadoop 用户,且在终端中使用 su 登录了 root 用户,那么需要执行 exit 退出 root 用户状态)
2 安装SSH、配置SSH无密码登陆
CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验
# rpm -qa | grep ssh
如果返回的结果如下图所示,包含了 SSH client 跟 SSH server,则不需要再安装
若需要安装,则可以通过 yum 进行安装(安装过程中会让你输入 [y/N],输入 y 即可):
$ sudo yum install openssh-clients $ sudo yum install openssh-server
接着执行如下命令测试一下 SSH 是否可用:
$ ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
$ exit # 退出刚才的 ssh localhost $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost $ ssh-keygen -t rsa # 会有提示,都按回车就可以 $ cat id_rsa.pub >> authorized_keys # 加入授权 $ chmod 600 ./authorized_keys # 修改文件权限

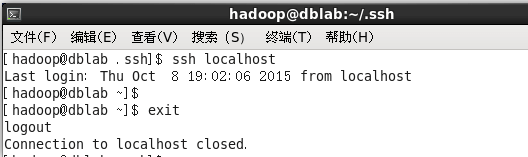
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
3 安装Java环境
(1)卸载自带OPENJDK
用 java -version 命令查看当前jdk版本信息
#java -version
用rpm -qa | grep java 命令查询操作系统自身安装的java
#rpm -qa | grep java
执行结果如下

python-javapackages-3.4.1-11.el7.noarch
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
tzdata-java-2015g-1.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
用rpm命令卸载下面这些文件(操作系统自身带的java相关文件)
#rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64 #rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64 #rpm -e --nodeps tzdata-java-2015g-1.el7.noarch #rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64 #rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
如果卸载错了,可使用yum install 来安装
(2)下载解压jdk
# wget --no-check-certificate --no-cookies --header "Cookies: oraclelicense=accept-securebackup-cookies" http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz
可以直接在终端下载也可以直接在网上下载默认的下载位置在主文件(/home/hadoop)
将"/hadoop/下载/jdk-8u141-linux-x64.tar.gz"文件拷贝到/usr/java 目录下
[root@localhost 下载]# cp jdk-7u80-linux-x64.tar.gz /usr/java
解压缩该压缩文件到 /usr/java目录
[root@localhost java]#tar -zxvf jdk-7u80-linux-x64.tar.gz
使用rm -f命令删除该jdk压缩文件
[root@localhost java]#rm -f jdk-7u80-linux-x64.tar.gz
(3)配置jdk环境变量
[root@localhost java]#vim /etc/profile
在最后一行加上如下值
#java environment
export JAVA_HOME=/usr/java/jdk1.7.0_80
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
注:CentOS6上面的是JAVAHOME,CentOS7是{JAVA_HOME}
source /etc/profile
#如果后卸载OPENJDK,就必须再次使用生效命令
我之前以为这样配好就不行了后来在运行hadoop报错找不到JAVA_HOME 还需要做一些配置
$ vim ~/.bashrc
在文件最前面添加单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为上述命令得到的路径,并保存:
|
1
|
export JAVA_HOME=/usr/local/java/jdk1.8.0_141 |
设置 HADOOP 环 境变量,执行如下命令在 ~/.bashrc 中设置:
最好在文件中配置下面的hadoop环境
|
1
2
3
4
5
6
7
8
9
|
# Hadoop Environment Variablesexport HADOOP_HOME=/usr/local/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin |
PATH配置hadoop环境那么以后我们在任意目录中都可以直接通过执行start-dfs.sh 来启动 Hadoop 或者执行 hdfs dfs -ls input 查看 HDFS 文件了,读者不妨现在就执行 hdfs dfs -ls input 。
着还需要让该环境变量生效,执行如下代码:
$ source ~/.bashrc # 使变量设置生效
设置好后我们来检验一下是否设置正确:
$ echo $JAVA_HOME # 检验变量值 $ java -version $ $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样
4 安装 Hadoop 2.6.5
下载hadoop-2.6.5.tar.gz 解压到
$ sudo tar -zxf ~/下载/hadoop-2.6.5.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-2.6.5/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息
$ cd /usr/local/hadoop $ ./bin/hadoop version
5 hadoop集群配置
完成上面的基础为配置hadoop集群的基础。准备两台机子Master(主节点),slave1(子节点)在两个节点上配置hadoop用户,java环境,ssh无密码登录,hadoop安装。
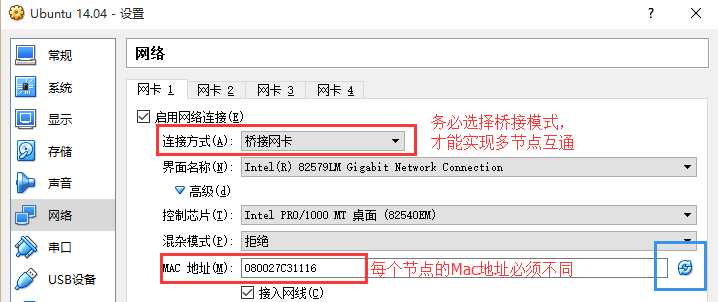
如果使用的是虚拟机安装的系统,那么需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连,例如在 VirturalBox 中的设置如下图。此外,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的 Mac 地址不同(可以点右边的按钮随机生成 MAC 地址,否则 IP 会冲突)
为了便于区分,可以修改各个节点的主机名(在终端标题、命令行中可以看到主机名,以便区分)。在 Ubuntu/CentOS 7 中,我们在 Master 节点上执行如下命令修改主机名(即改为 Master,注意是区分大小写的)
$ sudo vim /etc/hostname
如果是用 CentOS 6.x 系统,则是修改 /etc/sysconfig/network 文件,改为 HOSTNAME=Master,如下图所示:

然后执行如下命令修改自己所用节点的IP映射:
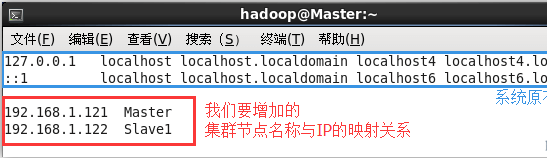
$ sudo vim /etc/hosts
我们在 /etc/hosts 中将该映射关系填写上去即可,如下图所示(一般该文件中只有一个 127.0.0.1,其对应名为 localhost,如果有多余的应删除,特别是不能有 “127.0.0.1 Master” 这样的记录):
修改完成后需要重启一下,重启后在终端中才会看到机器名的变化。接下来的教程中请注意区分 Master 节点与 Slave 节点的操作。

配置好后需要在各个节点上执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功
ping Master -c 3 # 只ping 3次,否则要按 Ctrl+c 中断 ping Slave1 -c 3
例如我在 Master 节点上 ping Slave1,ping 通的话会显示 time,显示的结果如下图所示
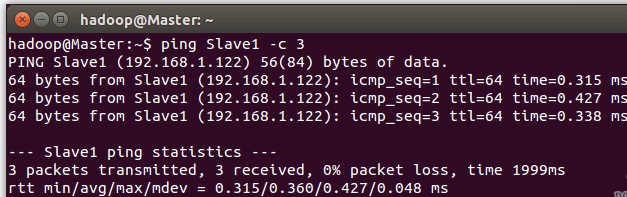
继续下一步配置前,请先完成所有节点的网络配置,修改过主机名的话需重启才能生效。
SSH无密码登陆节点
这个操作是要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次)
$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost $ rm ./id_rsa* # 删除之前生成的公匙(如果有) $ ssh-keygen -t rsa # 一直按回车就可以
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
$ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 Slave1 上 hadoop 用户的密码(hadoop),输入完成后会提示传输完毕,如下图所示:

接着在 Slave1 节点上,将 ssh 公匙加入授权:
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys $ rm ~/id_rsa.pub # 用完就可以删掉了
如果有其他 Slave 节点,也要执行将 Master 公匙传输到 Slave 节点、在 Slave 节点上加入授权这两步。
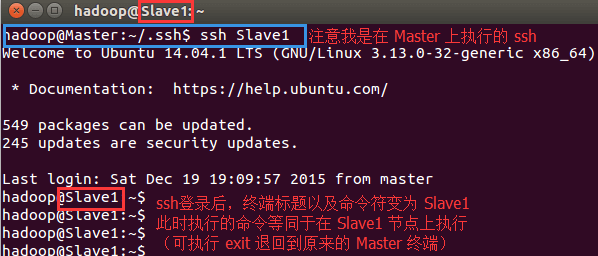
这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验,如下图所示:
$ ssh Slave1
配置集群/分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:Slave1。
2, 文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
5, 文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
$ cd /usr/local $ sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件 $ sudo rm -r ./hadoop/logs/* # 删除日志文件 $ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制 $ cd ~ $ scp ./hadoop.master.tar.gz Slave1:/home/hadoop
在 Slave1 节点上执行:
$ sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在) $ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local $ sudo chown -R hadop /usr/local/hadoop
同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
$ hdfs namenode -format # 首次运行需要执行初始化,之后不需要
zhuanzi https://www.cnblogs.com/xzjf/p/7231519.html