序言
天王盖地虎,
老婆马上生孩子了,在家待产,老婆喜欢玩消消乐类似的休闲游戏,闲置状态,无聊的分析一下消消乐游戏的一些技术问题;
由于我主要是服务器研发,客户端属于半吊子,所以就分析一下消消乐排行榜问题;
第一章
消消乐排行榜大致分为好友排行榜和全国排行榜;
好友排行榜和全国排行榜的其实是重合的只是需要从全国排行榜中提取出来而已;
那么就需要记录所有玩家的通关记录已进行查询;
也许你说全国排行榜只显示前xxx名就好;但是你的好友记录必须要的吧?你的好友不可能全部进入全国排行榜吧;
而好友排行榜基本都是要去全部显示出来排名;
所有那么问题来了:
我们加入400万用户,那么每一关卡都会有400万记录;
目前消消乐关卡开始1200关,那么就是400万 x 1200 = 48亿条数据;这他妈的吓死人啊;
消消乐游戏,最大的技术关键是排行榜查询问题,反而写入速度,和频率却不高;
还有重要的一点是每一关卡的玩家流失率大约:0.xx%;
由于我在家休息中,家里开发环境限制所以设定数据存在是sqlite、mysql数据库,其他数据库有待研究;如果redis 牵涉排序问题,搜索问题,么有想到好的方案;
第二章
我首先设计通关记录存储表结构模型;
需要,玩家id,通关关卡,通关星级,通关积分,通关时间


1 class TopList extends DataBaseModel implements Serializable, Cloneable { 2 3 /*玩家id*/ 4 private long pid; 5 /*关卡*/ 6 private int point; 7 /*星级*/ 8 private int star; 9 /*通关时间*/ 10 private long time; 11 /*积分*/ 12 private int integral; 13 14 public long getPid() { 15 return pid; 16 } 17 18 public void setPid(long pid) { 19 this.pid = pid; 20 } 21 22 public int getPoint() { 23 return point; 24 } 25 26 public void setPoint(int point) { 27 this.point = point; 28 } 29 30 public int getStar() { 31 return star; 32 } 33 34 public void setStar(int star) { 35 this.star = star; 36 } 37 38 public long getTime() { 39 return time; 40 } 41 42 public void setTime(long time) { 43 this.time = time; 44 } 45 46 public int getIntegral() { 47 return integral; 48 } 49 50 public void setIntegral(int integral) { 51 this.integral = integral; 52 } 53 54 @Override 55 public Object clone() { 56 try { 57 return super.clone(); //To change body of generated methods, choose Tools | Templates. 58 } catch (CloneNotSupportedException ex) { 59 } 60 return null; 61 } 62 63 }
测试代码
1 public static void main(String[] args) throws Exception { 2 3 SqliteDaoImpl sdi = new SqliteDaoImpl("/home/toplist.db"); 4 TopList topList = new TopList(); 5 6 CUDThread cudt = new CUDThread(sdi, "top-list-thread"); 7 /*设置异步操作的缓冲容量*/ 8 cudt.setMaxTaskCount(500000); 9 /*设置单次写入的数据量*/ 10 cudt.setGetTaskMax(5000); 11 /*创建表*/ 12 sdi.createTable(topList); 13 14 /*id生成器*/ 15 LongId0 longId0 = new LongId0(); 16 17 /*模拟5万个玩家*/ 18 for (int i = 0; i < 50000; i++) { 19 long id = longId0.getId(); 20 /*模拟500关卡*/ 21 for (int j = 1; j <= 500; j++) { 22 23 TopList clone = (TopList) topList.clone(); 24 clone.setPid(id); 25 clone.setTime(System.currentTimeMillis()); 26 clone.setPoint(j); 27 clone.setStar(3); 28 /*随机积分*/ 29 clone.setIntegral(RandomUtils.random(20000, 400000)); 30 31 cudt.insert_Sync(clone); 32 } 33 } 34 35 }
sqlite插入速度非常快,
[07-25 11:28:20:368:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:115 [07-25 11:28:20:368:DEBUG:CUDThread.run():246] 当前待处理剩余数量:7257 [07-25 11:28:20:524:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:155 [07-25 11:28:20:524:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8342 [07-25 11:28:20:696:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:172 [07-25 11:28:20:696:DEBUG:CUDThread.run():246] 当前待处理剩余数量:9129 [07-25 11:28:20:818:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:122 [07-25 11:28:20:818:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8188 [07-25 11:28:20:973:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:154 [07-25 11:28:20:973:DEBUG:CUDThread.run():246] 当前待处理剩余数量:8424
我们查询一下数据库;
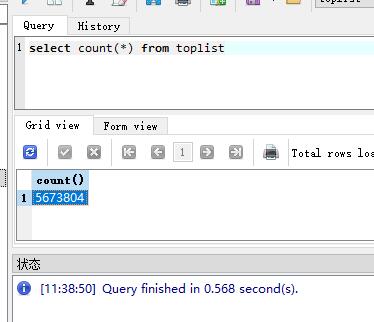
总数据是560多万行数据;
查询一下关卡数据
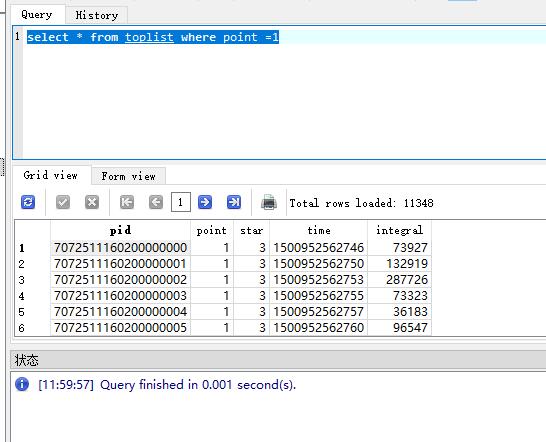
查询关卡数据很快;
但是我需要排序
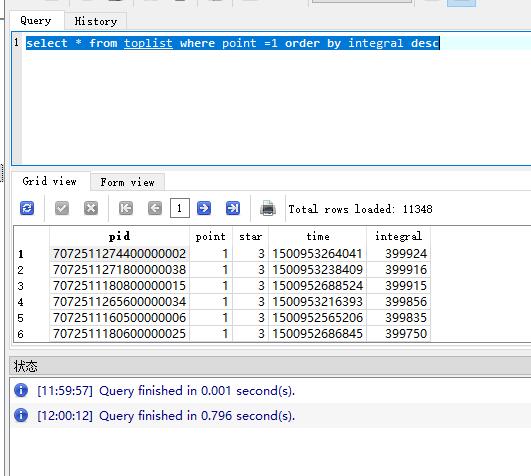
这些就看出对比了吧,这仅仅只有不到600万条数据呢;而且我们仅仅是查询了全国总排行,还么有牵涉好友排行榜,多条件搜索;
第三章
数据库可以增加索引的,加入索引后,查询会快很多;
那么接下来我们修改模型,测试
1 class TopList extends DataBaseModel implements Serializable, Cloneable { 2 3 /*玩家id*/ 4 @AttColumn(index = true) 5 private long pid; 6 /*关卡*/ 7 @AttColumn(index = true) 8 private int point; 9 /*积分*/ 10 @AttColumn(index = true) 11 private int integral; 12 /*星级*/ 13 private int star; 14 /*通关时间*/ 15 private long time; 16 17 public long getPid() { 18 return pid; 19 } 20 21 public void setPid(long pid) { 22 this.pid = pid; 23 } 24 25 public int getPoint() { 26 return point; 27 } 28 29 public void setPoint(int point) { 30 this.point = point; 31 } 32 33 public int getStar() { 34 return star; 35 } 36 37 public void setStar(int star) { 38 this.star = star; 39 } 40 41 public long getTime() { 42 return time; 43 } 44 45 public void setTime(long time) { 46 this.time = time; 47 } 48 49 public int getIntegral() { 50 return integral; 51 } 52 53 public void setIntegral(int integral) { 54 this.integral = integral; 55 } 56 57 @Override 58 public Object clone() { 59 try { 60 return super.clone(); //To change body of generated methods, choose Tools | Templates. 61 } catch (CloneNotSupportedException ex) { 62 } 63 return null; 64 } 65 66 }
修改模型,在玩家id,分数,关卡,这三个地方加入索引;
1 [07-25 13:11:04:759:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:662 2 [07-25 13:11:04:760:DEBUG:CUDThread.run():246] 当前待处理剩余数量:22525 3 [07-25 13:11:05:549:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:787 4 [07-25 13:11:05:550:DEBUG:CUDThread.run():246] 当前待处理剩余数量:24975 5 [07-25 13:11:06:437:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:885 6 [07-25 13:11:06:438:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27030 7 [07-25 13:11:07:198:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:759 8 [07-25 13:11:07:199:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27454 9 [07-25 13:11:08:023:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:823 10 [07-25 13:11:08:027:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27449 11 [07-25 13:11:08:966:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:936 12 [07-25 13:11:08:967:DEBUG:CUDThread.run():246] 当前待处理剩余数量:27900 13 [07-25 13:11:09:945:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:977
数据库数据越来越多的时候,插入速度就会越来越慢;看下图,是不是很吓人?
1 [07-25 13:15:06:511:DEBUG:CUDThread.run():246] 当前待处理剩余数量:23473 2 [07-25 13:15:10:948:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:4434 3 [07-25 13:15:10:950:DEBUG:CUDThread.run():246] 当前待处理剩余数量:42028 4 [07-25 13:15:14:666:DEBUG:CUDThread.run():219] 新增数据插入影响行数:5000 耗时:3715 5 [07-25 13:15:14:668:DEBUG:CUDThread.run():246] 当前待处理剩余数量:49338
也许与我当前笔记本硬盘有关系;电脑性能占用问题;

插入速度是慢了,我们来看看查询速度吧,
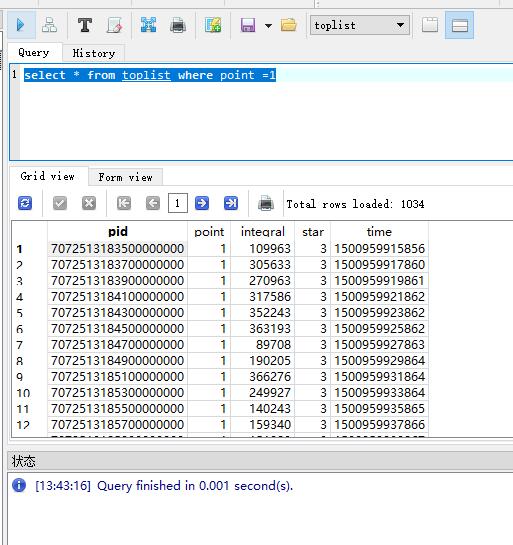
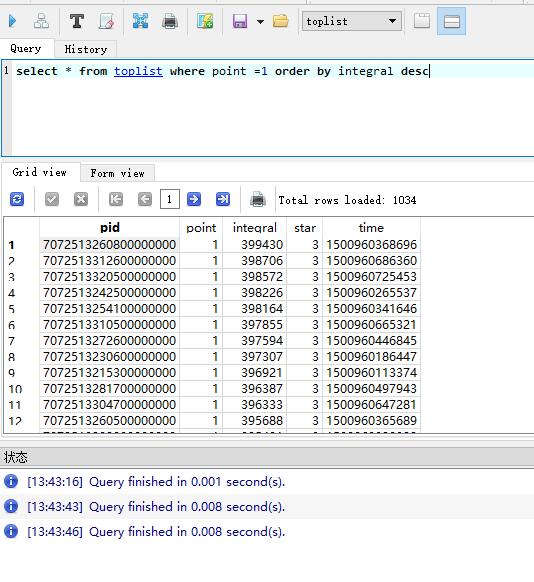
我们可以看到插入速度快很多;
当然此时的数据量确实么有之前的多,因为测试问题,插入的数据的确实很慢,
如果是mysql 数据库,还需要加入联合索引查询才会翻倍提升性能;mysql插入速度会比sqlite好一点,因为sqlie本身就不适用于大型数据集合;
第四章
其实以上工作只是做到了索引优化问题;但是也抵不住越来越多的数据;对不对?
所以还是的寻求其他方式来解决问题;
我们先来分析情况
可以建立分区表形式;但是建立分区表,数据也只是在一个表内大hash集合,然后区分的小hash集合,然后就算mysql这种官方建议的分区表都是200万条数据;
所以没有尝试过;有兴趣的同学可以研究研究;
我想到的第二种方式,分表,之前在做游戏运营后台,接受来之多个游戏的运营日志数据,就采用了这种方式,分表,每一天一张表,来划分;
所以我很快又想到了这种方式,我以每一个关卡划分通关数据记录,
可是仔细一想肯定不行啊,因为按照现在消消乐这种游戏来说1200关,1000多张表,维护都得忙死;而且越往后越更新越多,依然不可行!
任何游戏只要在生存周期内,就有有人加入,有人流失;
那么消消乐这种关卡类的游戏,那么数据量永远都在前面关卡,越往后越少,就跟我前面说的一样,每一关卡都会流失0.xxx%;
那么我们可以设计30张表,30张总能接受了吧?
起码我是能接受了;
可是如何优雅的利用30张表数据的呢?
我们分析可得越靠前的关卡,数据越多,
那么我们设计前800关卡的数据存入20张表;
后面的所以表记录到剩余的10张表中;
创建表,获取表名的简易算法;
1 /** 2 * 获取表名 3 * 4 * @param point 5 * @return 6 */ 7 static String getTableName(int point) { 8 int tableId = 0; 9 if (point < 300) { 10 /*第一段前300关存入15张表*/ 11 tableId = 1000 + point % 15; 12 } else if (point < 800) { 13 /*第二段后500关卡存入5张表*/ 14 tableId = 2000 + point % 5; 15 } else { 16 /*800关卡以后的数据存入剩余10张表*/ 17 tableId = 3000 + point % 10; 18 } 19 20 return TopList.class.getSimpleName().toLowerCase() + tableId; 21 }
创建表
1 int points = 1200; 2 3 TopList topList = new TopList(); 4 for (int i = 1; i <= points; i++) { 5 topList.setDataTableName(getTableName(i)); 6 /*创建表*/ 7 sdi.createTable(topList); 8 }
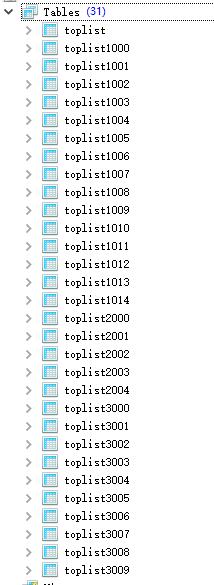
表自动创建完成;
1 /*模拟5万个玩家*/ 2 for (int i = 1; i <= 50000; i++) { 3 long id = longId0.getId(); 4 /*模拟关卡*/ 5 int j = 1; 6 for (; j <= points; j++) { 7 8 TopList clone = (TopList) topList.clone(); 9 clone.setDataTableName(getTableName(j)); 10 clone.setPid(id); 11 clone.setTime(System.currentTimeMillis()); 12 clone.setPoint(j); 13 clone.setStar(3); 14 /*随机积分*/ 15 clone.setIntegral(RandomUtils.random(20000, 400000)); 16 17 cudt.insert_Sync(clone); 18 } 19 log.info("总共写入数据量:" + (i * (j - 1))); 20 Thread.sleep(1000); 21 }
写入速度,已经得到提升了,
1 [07-25 14:24:12:293:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2750 2 [07-25 14:24:12:294:DEBUG:CUDThread.run():246] 当前待处理剩余数量:3600 3 [07-25 14:24:12:605:INFO :TopTest.main():68] 总共写入数据量:222185 4 [07-25 14:24:13:619:INFO :TopTest.main():68] 总共写入数据量:223386 5 [07-25 14:24:14:647:INFO :TopTest.main():68] 总共写入数据量:224587 6 [07-25 14:24:14:757:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2463 7 [07-25 14:24:14:758:DEBUG:CUDThread.run():246] 当前待处理剩余数量:4200 8 [07-25 14:24:15:690:INFO :TopTest.main():68] 总共写入数据量:225788 9 [07-25 14:24:16:709:INFO :TopTest.main():68] 总共写入数据量:226989 10 [07-25 14:24:17:502:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2744 11 [07-25 14:24:17:502:DEBUG:CUDThread.run():246] 当前待处理剩余数量:3600 12 [07-25 14:24:17:743:INFO :TopTest.main():68] 总共写入数据量:228190 13 [07-25 14:24:18:755:INFO :TopTest.main():68] 总共写入数据量:229391 14 [07-25 14:24:19:783:INFO :TopTest.main():68] 总共写入数据量:230592 15 [07-25 14:24:20:250:DEBUG:CUDThread.run():219] 新增数据插入影响行数:3000 耗时:2748 16 [07-25 14:24:20:250:DEBUG:CUDThread.run():246] 当前待处理剩余数量:4200 17 [07-25 14:24:20:824:INFO :TopTest.main():68] 总共写入数据量:231793 18 [07-25 14:24:21:843:INFO :TopTest.main():68] 总共写入数据量:232994
查询速度在第三章已经验证了,就不在验证;
总结
像消消乐这类型游戏重点就在于排行榜数据存储和读取,然后写入和读取相比,写入的需求远远小于读取的需求;
我做的是实时数据排行榜区分;
当然我们还可以利用mysql的主从关系,提供读写分离情况,做非实时排行榜数据;
也可以利用非滑动缓存来做非实时排行榜,解决写入和读取的性能平衡问题,缓存可以设置比如每5分钟或者每10分钟更新一次排行榜数据来完成;
以上分析就不再做代码测试;
这是我分析和我的解决方案,不知道屌大的园友们还要更好的解决方案吗?


