从一个例子开始,两个人进行猜数游戏,其中一个人写下一个数字,另外一个人猜,每猜一个数,给这个人说大了还是小了,继续猜,比如猜一个100以内的数,写下的数是64,最多猜7次就可以猜到这个数,这里就使用了二分思想。
二分思想是一个应用很广泛的思想,比如对于一个有序数组,它能将查找效率从O(n)优化到O(logn),因为每次可以将范围缩小为上一次的一半。这是在数组中的应用场景,我们以这个为基础来分析一下二分查找的时间复杂度
对于一个有 n 个元素的有序数组中,每次查找后缩小数据范围为上一次的二分之一,所以有 n/2 , n/4 , n/8, … , n/(2^k)
当 n/(2^k) = 1 时,得到最终结果,则 k = logn,记作二分查找的时间复杂度 O(logn),是一个非常高效的算法;举个例子,如果我们在一个40亿的数据中查找某个数,也只需要32次,相对于顺序查找效率提升了太多,可见其威力。
总结一下,二分查找是针对一个有序集合,每次通过将要查找的数据范围缩小为上一次的一半,直到找到目标值,或者区间缩小为0。二分查找正是在有序数组上应用了二分思想。
二分思想其实是一种解决问题的思想,为了加速查找效率而生,所谓的二分并不代表一定是二,也可以是三,可以是N,只是一种表述,表达的意思是以最快的速率将搜索数据的范围缩小。
1 public class BinarySearch {
2 // 二分查找实现
3 public static int search(int[] arr, int target) {
4 int low = 0, high = arr.length - 1;
5
6 // 这里的中止条件是 low <= high, 因为 high = arr.length - 1
7 while (low <= high) {
8 // 使用 low + (high - low) / 2, 而不使用 (high + low) / 2, 是因为 high + low 可能造成整型溢出
9 // int mid = low + (high - low) / 2; // 这种方式是可以的,不如位运算效率高
10 int mid = low + ((high - low) >> 1); // 这种方式是最优的,效率最高
11
12 if (arr[mid] == target) {
13 return mid;
14 } else if (arr[mid] > target) {
15 high = mid - 1;
16 } else {
17 low = mid + 1;
18 }
19 }
20 return -1;
21 }
22
23 // 利用递归实现二分查找
24 public static int searchRecursive(int[] arr, int target) {
25 return recurSearch(arr, target, 0, arr.length - 1);
26 }
27 private static int recurSearch(int[] arr, int target, int left, int right) {
28 // terminator
29 if (left > right)
30 return -1;
31
32 int mid = left + ((right - left) >> 1);
33
34 if (arr[mid] == target) {
35 return mid;
36 } else if (arr[mid] > target) {
37 return recurSearch(arr, target, left, mid - 1);
38 } else {
39 return recurSearch(arr, target, mid + 1, right);
40 }
41 }
42 }
以上是一个常规的二分查找实现,这个数组中没有重复元素,查找给定值的元素,但是还有更难的:
- 查找第一个值等于给定值的元素位置
- 查找最后一个值等于给定值的元素位置
- 查找第一个大于等于给定值的元素位置
- 查找最后一个小于等于给定值的元素位置
这几个问题的代码都相对难写,代码实现如下:
1 class BinarySearchExt {
2 // 查找第一个值等于给定值的元素位置
3 public static int searchFirst(int[] arr, int target) {
4 int left = 0, high = arr.length - 1;
5
6 while (left <= right) {
7 int mid = left + (right - left) / 2;
8 if (arr[mid] > target) {
9 right = mid - 1;
10 } else if (arr[mid] < target) {
11 left = mid + 1;
12 } else {
13 if (mid == 0 || arr[mid - 1] != target) return mid;
14 else high = mid - 1;
15 }
16 }
17
18 return -1;
19 }
20
21 // 查找最后一个值等于给定值的元素位置
22 public static int searchLast(int[] arr, int target) {
23 int left = 0, high = arr.length - 1;
24 while (left <= right) {
25 int mid = left + (right - left) / 2;
26 if (arr[mid] > target) {
27 right = mid - 1;
28 } else if (arr[mid] < target) {
29 left = mid + 1;
30 } else {
31 if ((mid == arr.length - 1) || (arr[mid + 1] != target)) return mid;
32 else left = mid + 1;
33 }
34 }
35 return -1;
36 }
37
38 // 查找第一个大于等于给定值的元素位置
39 public static int searchGte(int[] arr, int target) {
40 int left = 0, right = arr.length - 1;
41 while (left <= right) {
42 int mid = left + ((right - left) >> 1);
43 if (arr[mid] >= target) {
44 if ((mid == 0) || (arr[mid - 1] < target)) return mid;
45 else right = mid - 1;
46 } else {
47 left = mid + 1;
48 }
49 }
50 return -1;
51 }
52
53 // 查找最后一个小于等于给定值的元素位置
54 public static int searchLte(int[] arr, int target) {
55 int left = 0, right = arr.length - 1;
56 while (left <= right) {
57 int mid = left + ((right - left) >> 1);
58 if (arr[mid] <= target) {
59 if ((mid == arr.length - 1) || (arr[mid + 1] > target)) return mid;
60 else left = mid + 1;
61 } else {
62 right = mid - 1;
63 }
64 }
65 return -1;
66 }
67 }
做个总结,分析一下二分查找的应用场景:
- 二分查找依赖于顺序表结构,如数组;在链表上直接运用二分查找效率低
- 二分查找需要数据是有序的,乱序的数据集合中无法应用,因为没有办法二分;所以对于相对静态的数据,排序后应用二分查找的效率还是很不错的;而对于动态变化的数据集合,维护成本会很高
- 数据量太小,发挥不出二分查找的威力;但是如果比较操作比较耗时,还是推荐使用二分查找
- 数据量太大,内存放不下
一个思考题:如何在1000万整数中快速查找某个整数呢?要求内存限制是100M,可以使用二分查找,先对1000万整数分配一个数组,然后进行排序,然后再使用二分查找。其他的方法,可能无法满足内存限制的问题,比如散列表、跳表、AVL树等。
另外一个思考题:如何快速定位一个IP的归属地?假设有10万+的IP地址段和归属地的映射关系,我们先对IP地址段的起始地址转成整数后排序,利用二分查找“在有序数组中,查找最后一个小于等于给定值的元素位置“,这样就可以找到一个ip段,然后取出来判断是不是在这个段里,不在的话,返回未找到;否则返回对应的归属地。
延伸之链表上的二分思想应用
上面,我们分析说在链表上应用二分查找的效率很低,那么为什么呢?分析一下
假设有n个元素的有序链表,现在用二分查找搜索数据,第一次移动指针次数 n/2,第二次移动 n/4,一直到 1,所以总的移动次数相加就是 n-1 次 可见时间复杂度是 O(n), 这个和顺序查找链表的时间复杂度 O(n) 是同级别的,其实二分查找比顺序查找的效率更低,因为它做了更多次无谓的指针移动
我们知道了二分思想直接应用到链表上是不可行的,有没有其他的办法,其实有,就是为有序链表增加多级索引,在搜索的时候根据索引应用二分思想。
跳表就是这样一种数据结构,它既可以维护链表的有序性,还可以动态更新删除数据,而且提供了 O(logn) 时间复杂度,但是相比于链表的 O(1) 空间复杂度,跳表是 O(n) 的时间复杂度。跳表如下:
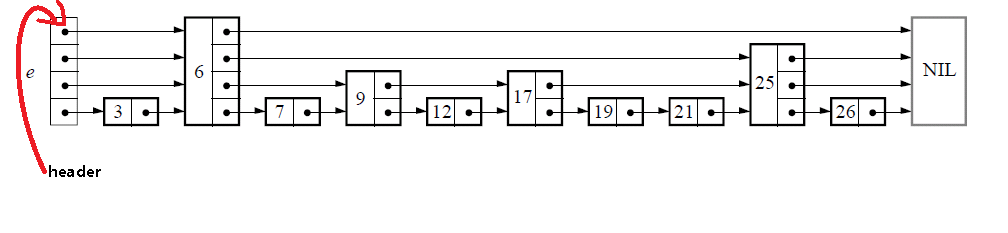
其核心思想是每m个节点(m可以是2,3,5…,根据实际情况指定)就提取一个节点出来作为上级的索引节点,我们可以提取k层,这样在查询时就可以根据每层索引快速的查询到链表上的数据,整个的思想其实和AVL树是很像的,尤其是 B+ 树;
跳表支持的核心功能:
- 动态插入一个数据 O(logn)
- 动态删除一个数据 O(logn)
- 查找一个数据 O(logn)
- 按照区间查找数据 O(logn)
- 迭代输出有序序列
其中,插入、删除、查找以及迭代输出有序序列,像红黑树这种近似AVL树也能够完成,但是按照区间输出这个功能,红黑树的效率没有跳表高。
我们在实现跳表的时候,有一些关键点需要注意:
- 选取跳表的最大索引层次以及如何选取多少个节点提取一个上级索引?一般情况下是选取16层/32层/64层,可根据实际的数据和应用常见来选择,以免层数太少,数据量太大导致退化到链表的时间复杂度;此外,每个节点要建立几级索引,一般的做法是使用一个随机函数,这个函数要够随机,通过随机函数的计算得到该节点的最大层数
- 在删除和插入数据时,跳表需要动态维护索引和数据,要尽量保证索引大小和数据大小的平衡性
- 此外,和红黑树相比,跳表的实现难度要小于红黑树,代码实现更加可读、不易出错,同时还更加灵活,通过改变索引构建策略有效平衡执行效率和内存消耗
1 public class SkipList implements Printer { 2 private final static int MAX_LEVEL = 16; 3 private final static double SKIPLIST_P = 0.5; 4 5 private Node head = new Node(); 6 private int levelCnt = 1; 7 8 // 插入 9 public void insert(int score) { 10 int level = randomLevel(); 11 Node newNode = new Node(); 12 newNode.score = score; 13 newNode.maxLevel = level; 14 15 // update,记录每一层的指针,方便对每一层做更新 16 Node[] update = new Node[level]; 17 for (int i = 0; i < level; i++) { 18 update[i] = head; 19 } 20 21 Node p = head; 22 for (int i = level - 1; i >= 0; i--) { 23 while (p.forwards[i] != null && p.forwards[i].score < score) { 24 p = p.forwards[i]; 25 } 26 // 找到每一层合适的插入位置 27 update[i] = p; 28 } 29 30 for (int i = 0; i < level; i++) { 31 // update[i] 指向 head or 第 i 层的 合适位置 的索引 32 // update[i].forwards[i] 相当于 head.forwards[i] 33 // 修改指针,让newNode插入update[i]后面 34 newNode.forwards[i] = update[i].forwards[i]; 35 update[i].forwards[i] = newNode; 36 } 37 38 // update the skip list node level 39 if (levelCnt < level) { 40 levelCnt = level; 41 } 42 } 43 44 // 删除 45 public void delete(int score) { 46 Node[] update = new Node[levelCnt]; 47 Node p = head; 48 for (int i = levelCnt - 1; i >= 0; i--) { 49 while (p.forwards[i] != null && p.forwards[i].score < score) { 50 p = p.forwards[i]; 51 } 52 update[i] = p; 53 } 54 55 if (p.forwards[0] != null && p.forwards[0].score == score) { 56 for (int i = levelCnt - 1; i >= 0; i--) { 57 if (update[i].forwards[i] != null && update[i].forwards[i].score == score) { 58 update[i].forwards[i] = update[i].forwards[i].forwards[i]; 59 } 60 } 61 } 62 63 while (levelCnt > 1 && head.forwards[levelCnt - 1] == null) { 64 levelCnt--; 65 } 66 } 67 68 // 查找 69 public Node find(int score) { 70 Node p = head; 71 for (int i = levelCnt - 1; i >= 0; i--) { 72 while (p.forwards[i] != null && p.forwards[i].score < score) { 73 p = p.forwards[i]; 74 } 75 } 76 77 if (p.forwards[0] != null && p.forwards[0].score == score) { 78 return p.forwards[0]; 79 } 80 81 return null; 82 } 83 84 // 随机函数 85 // 要保证随机性 86 // 50% 返回 1 87 // 25% 返回 2 88 // 12.5% 返回 3 89 // ... 90 private int randomLevel() { 91 int level = 1; 92 while (Math.random() < SKIPLIST_P && level < MAX_LEVEL) { 93 level += 1; 94 } 95 return level; 96 } 97 98 // 顺序输出所有元素 99 @Override 100 public void print() { 101 Node p = head; 102 System.out.println("-----"); 103 while (p.forwards[0] != null) { 104 System.out.println(p.forwards[0]); 105 p = p.forwards[0]; 106 } 107 System.out.println("-----"); 108 } 109 110 class Node { 111 private String key; // 暂不使用 112 113 // 根据 score 进行排序 114 private int score; 115 116 private Node[] forwards; 117 private int maxLevel; 118 119 public Node() { 120 this(-1, MAX_LEVEL, 0); 121 } 122 123 public Node(int score, int maxNodeLevel, int maxLevel) { 124 this.score = score; 125 this.forwards = new Node[maxNodeLevel]; 126 this.maxLevel = maxLevel; 127 } 128 129 @Override 130 public String toString() { 131 StringBuilder sb = new StringBuilder(); 132 sb.append("{ score: "); 133 sb.append(score); 134 sb.append(", levels: "); 135 sb.append(maxLevel); 136 sb.append(" }"); 137 return sb.toString(); 138 } 139 } 140 }
跳表是一个高性能的数据结构,在Redis中得到了应用。Redis 的有序集合的底层数据结构就有用到跳表(Skiplist);
二分查找常见的算法题目
搜索插入位置,这是一道二分查找的直接应用
实现如下
1 class Solution {
2 public int searchInsert(int[] nums, int target) {
3 int left = 0, right = nums.length - 1;
4
5 int pos = -1;
6 while (left <= right) {
7 int mid = left + (right - left) / 2;
8 if (nums[mid] == target) {
9 pos = mid;
10 break;
11 } else if (nums[mid] > target) {
12 right = mid - 1;
13 } else {
14 left = mid + 1;
15 }
16 }
17 return pos == -1 ? left : pos;
18 }
19 }
这个题目也是二分查找的一个拓展题目,代码实现如下
1 class Solution {
2 public int search(int[] nums, int target) {
3 if (nums.length == 1) return nums[0] == target ? 0 : -1;
4 int low = 0, high = nums.length - 1;
5
6 while (low <= high) {
7 int mid = low + (high - low) / 2;
8
9 if (nums[mid] == target) return mid;
10
11 // 这里是关键
12 // nums[low] <= target && target < nums[mid] 表示 low mid 是有序的,且target在它们中间,需要将high向前移动
13 // nums[low] > nums[mid] && target > nums[high] 表示 low ~ mid 是无序的,而且 target 比 high 位置的元素还要大,因为 mid ~ high 是有序的,所以必然在 low ~ mid 中间,移动high
14 // nums[low] > nums[mid] && target < nums[mid] 表示 low ~ mid 是无序的, 而且 target 比mid位置处的值还要小,因为 mid ~ high 是有序的,所以必然在 low ~ mid 中间,移动high
15 // 否则,就是移动low
16 if ((nums[low] <= target && target < nums[mid]) ||
17 (nums[low] > nums[mid] && target > nums[high]) ||
18 (nums[low] > nums[mid] && target < nums[mid])) {
19 // 这里是
20 high = mid - 1;
21 } else {
22 low = mid + 1;
23 }
24 }
25
26 return low == high && nums[low] == target ? low : -1;
27 }
28 }
Pow(x,n)
x的平方根,如果是精确到小数后6位呢?
1 class Solution {
2 // 关键是边界
3 public int findMin(int[] nums) {
4 int low = 0, high = nums.length - 1;
5 int lastElement = nums[high];
6 while (low < high) {
7 int mid = low + ((high - low) >> 1);
8 // 比最后一个元素小,说明转折点必定在mid的左边, 搜索左边
9 if (nums[mid] < lastElement) high = mid;
10 // 否则在右边
11 else low = mid + 1;
12 }
13 return nums[low];
14 }
15 }