0. 定义
知识图谱本质上是语义网络(Semantic Network)的知识库
==> 从实际应用的角度出发,可以简单地把知识图谱理解成多关系图(Multi-relational Graph)
图
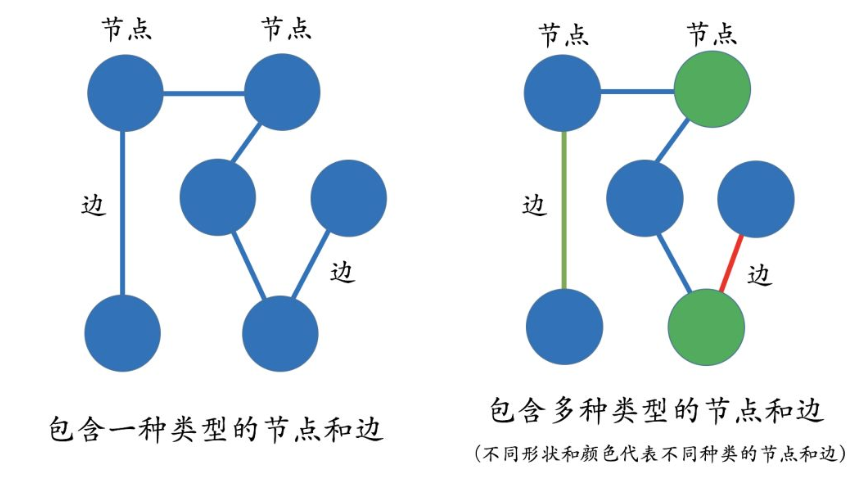
图(Graph)是由节点(Vertex)和边(Edge)来构成,多关系图一般包含多种类型的节点和多种类型的边。实体(节点)指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系(边)则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
Schema
限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性
- 作用:规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中
- 例:
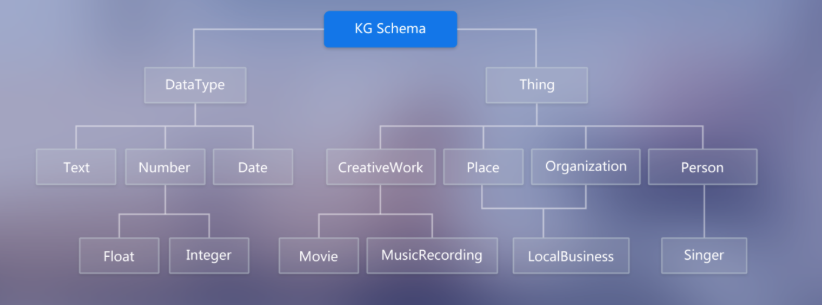
- 图中的DataType限定了知识图谱节点值的类型为文本、日期、数字(浮点型与整型)
- 图中的Thing限定了节点的类型及其属性(即图1-1中的边)
-
- ==> 基于该Schema构建的知识图谱中仅可含作品、地方组织、人物;其中作品的属性为电影与音乐、地方组织的属性为当地的商业(eg:饭店、俱乐部等)、人物的属性为歌手
1. 数据来源
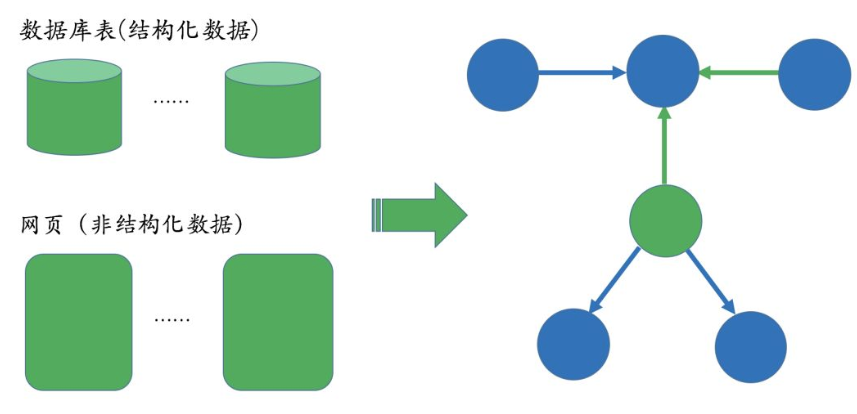
- 业务本身的数据。这部分数据通常包含在公司内的数据库表并以结构化的方式存储,一般只需要简单预处理即可以作为后续AI系统的输入;
- 网络上公开、抓取的数据。(难点)这些数据通常是以网页的形式存在所以是非结构化的数据,一般需要借助于自然语言处理等技术来提取出结构化信息。例如:
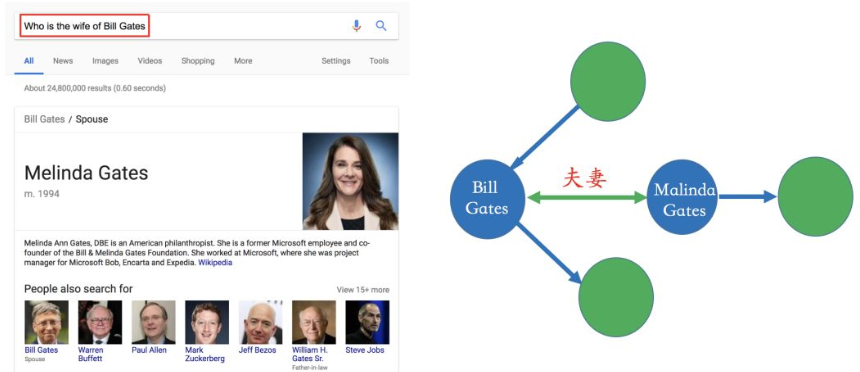
Bill Gates和Malinda Gate的关系就可以从非结构化数据中提炼出来,比如维基百科等数据源。
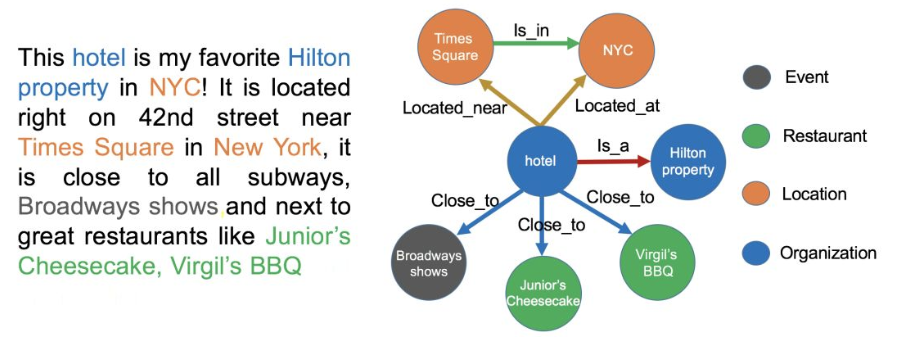
左边是一段非结构化的英文文本,右边是从这些文本中抽取出来的实体和关系。
2. 相关技术
在构建类似的图谱过程当中,主要涉及以下几个方面的自然语言处理技术:
2.1 实体命名识别(NER, Name Entity Recognition)
- 目标:从文本里提取出实体并对每个实体做分类/打标签;
- 举例:下述示例图文本里,提取出实体-“NYC”,标记实体类型为 “Location”;同理,提取出“Virgil's BBQ”,标记实体类型为“Restarant”。
2.2 关系抽取(RE, Relation Extraction)
- 目标:通过关系抽取技术,把实体间的关系从文本中提取出来;
- 举例:实体“hotel”和“Hilton property”之间的关系为“in”;“hotel”和“Time Square”的关系为“near”。

2.3 实体统一(ER, Entity Resolution)
- 目标:有些实体写法上不一样,实际指向同一个实体 ==> 减少实体的种类,降低图谱的稀疏性(Sparsity);
- 举例:“NYC”和“New York”表面上是不同的字符串,实际指的都是纽约这个城市,需要合并。
2.4 指代消解(Coreference Resolution)
- 目标:确认文本中出现的“it”, “he”, “she”等代词的确切实体指向,在下述图例中,两个被标记出来的“it”都指向“hotel”这个实体。

3. 知识图谱的存储
主要有两种存储方式:
- 基于RDF的存储;
- 基于图数据库的存储。

RDF重点在数据的易发布以及共享,存储三元组,无属性;图数据库则把重点放在了高效的图查询和搜索,包含属性。
对于RDF的存储系统,Jena或许一个比较不错的选择。
对于图数据库,Neo4J系统目前仍是使用率最高的图数据库,它拥有活跃的社区,系统本身的查询效率高,唯一的不足是不支持准分布式。
OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃。
Neo4J实战
参考上述教程的实践笔记:
Neo4J分为社区版和企业版,企业版在横向扩展、权限控制、运行性能、HA等方面都比社区版好,适合正式的生产环境,普通的学习和开发采用免费社区版就好。
1. 首先,我们删除数据库中以往的图,确保一个空白的环境进行操作:
MATCH (n) DETACH DELETE n这里,MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
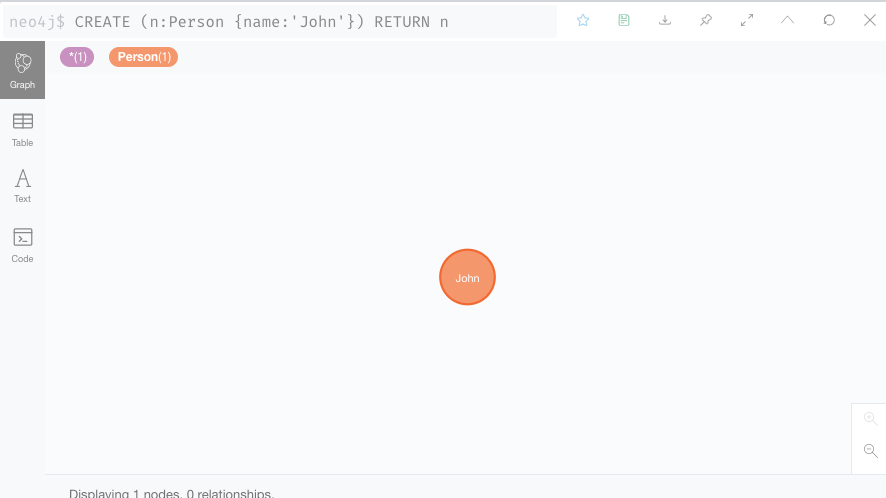
2. 接着,我们创建一个人物节点:
CREATE (n:Person {name:'John'}) RETURN nCREATE是创建操作,Person是标签,代表节点的类型。花括号{}代表节点的属性,属性类似Python的字典。这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
3. 我们继续来创建更多的人物节点,并分别命名:
CREATE (n:Person {name:'Sally'}) RETURN n
CREATE (n:Person {name:'Steve'}) RETURN n
CREATE (n:Person {name:'Mike'}) RETURN n
CREATE (n:Person {name:'Liz'}) RETURN n
CREATE (n:Person {name:'Shawn'}) RETURN n如图所示,6个人物节点创建成功

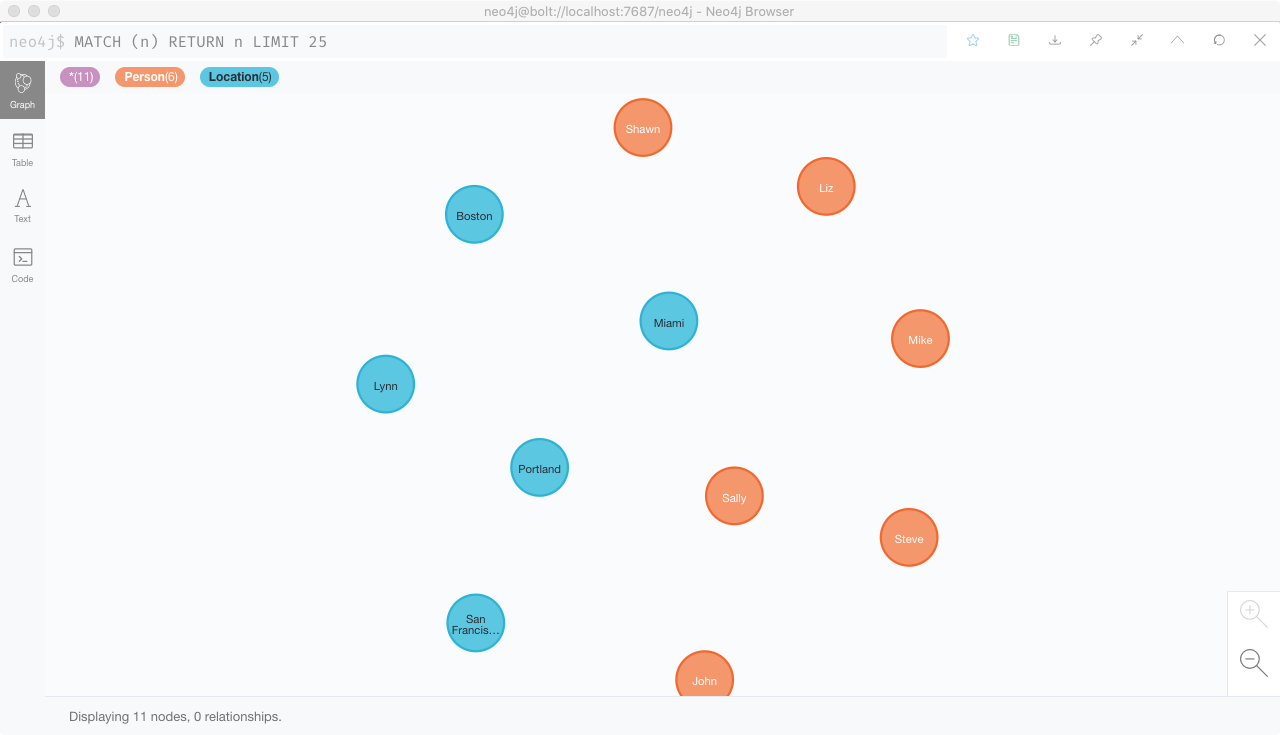
4. 接下来创建地区节点
CREATE (n:Location {city:'Miami', state:'FL'})
CREATE (n:Location {city:'Boston', state:'MA'})
CREATE (n:Location {city:'Lynn', state:'MA'})
CREATE (n:Location {city:'Portland', state:'ME'})
CREATE (n:Location {city:'San Francisco', state:'CA'})可以看到,节点类型为Location,属性包括city和state。
如图所示,共有6个人物节点、5个地区节点,Neo4J贴心地使用不用的颜色来表示不同类型的节点。
5. 接下来创建关系
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)这里的方括号[]即为关系,FRIENDS为关系的类型。注意这里的箭头-->是有方向的,表示是从a到b的关系。 如图,Liz和Mike之间建立了FRIENDS关系,通过Neo4J的可视化很明显的可以看出:
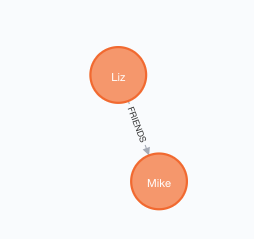
6. 关系也可以增加属性
MATCH (a:Person {name:'Shawn'}),
(b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)在关系中,同样的使用花括号{}来增加关系的属性,也是类似Python的字典,这里给FRIENDS关系增加了since属性,属性值为2001,表示他们建立朋友关系的时间。
7. 接下来增加更多的关系
MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Sally'}), (b:Person {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)如图,人物关系图已建立好,有点图谱的意思了吧?[有呀!]
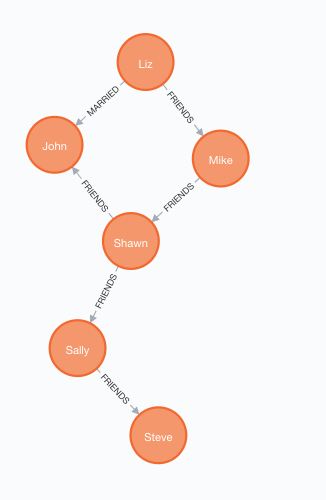
8. 然后,我们需要建立不同类型节点之间的关系-人物和地点的关系
MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b)这里的关系是BORN_IN,表示出生地,同样有一个属性,表示出生年份。
如图,在人物节点和地区节点之间,人物出生地关系已建立好。
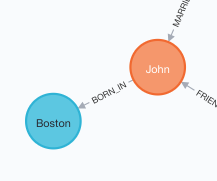
9. 同样建立更多人的出生地
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)建好以后,整个图如下
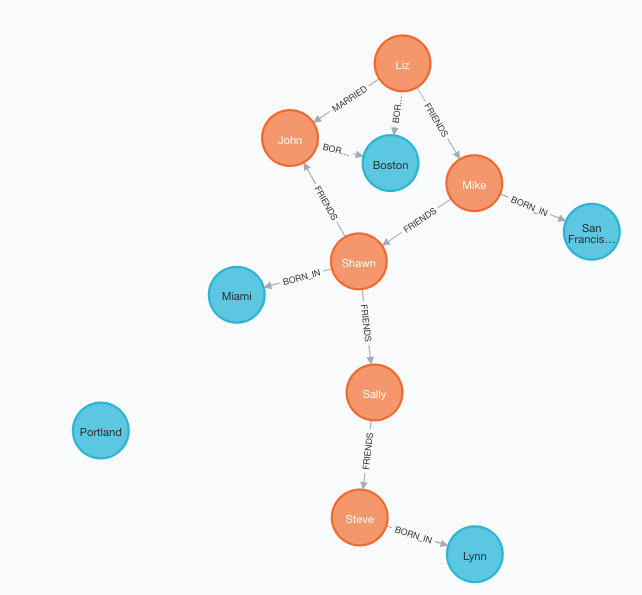
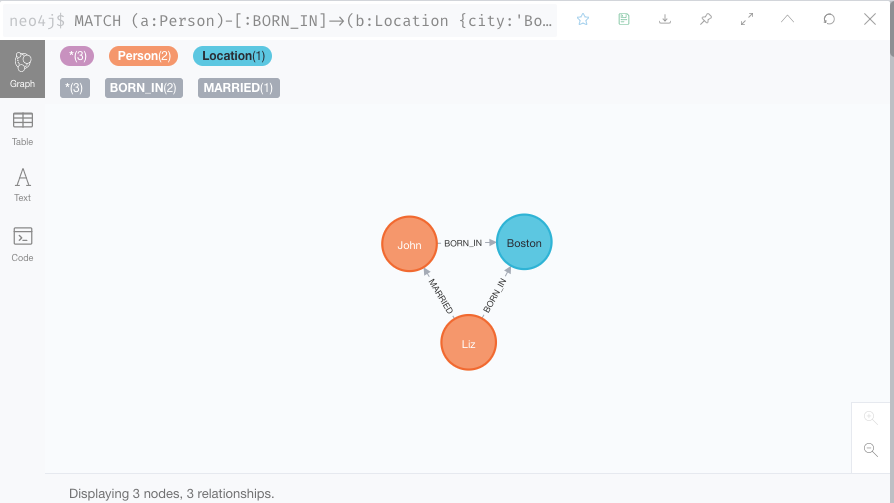
10. 至此,知识图谱的数据已经插入完毕,可以开始做查询了。我们查询下所有在Boston出生的人物
MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b结果如图
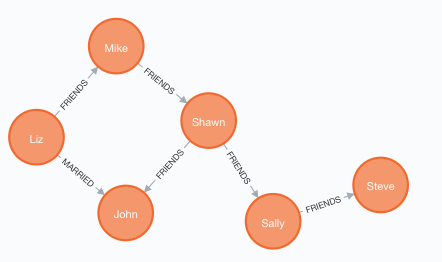
11. 查询所有对外有关系的节点
MATCH (a)-->() RETURN a注意这里箭头的方向,返回结果不含任何地区节点,因为地区并没有指向其他节点(只是被指向)
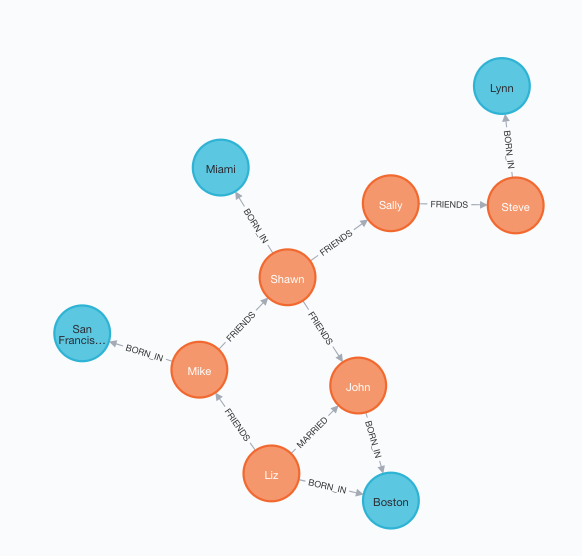
12. 查询所有有关系的节点
MATCH (a)--() RETURN a结果如图
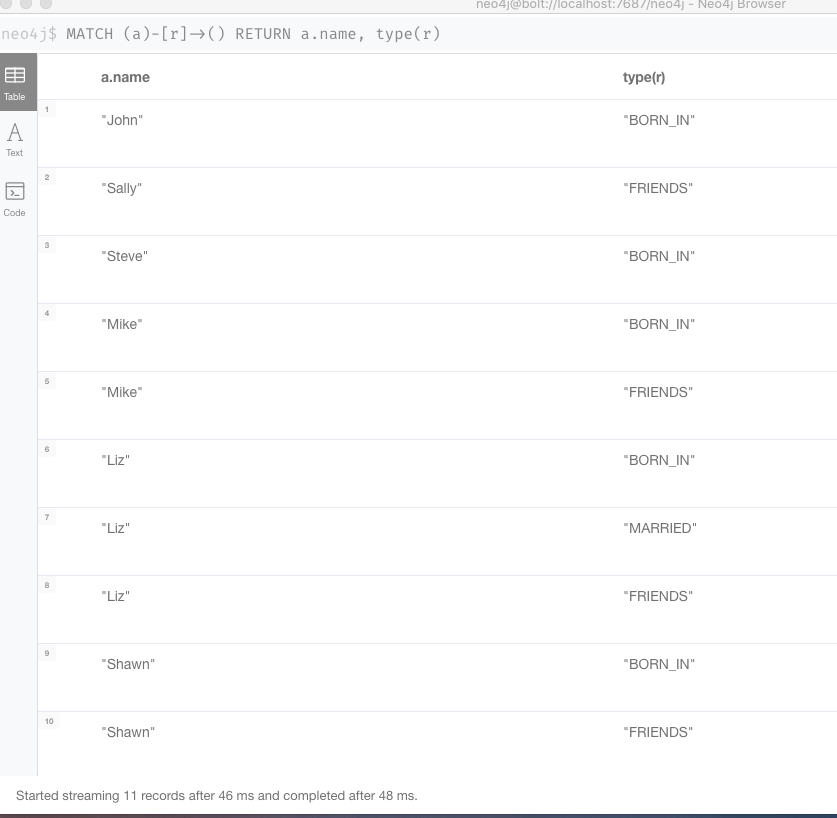
13. 查询所有对外有关系的节点,以及关系类型
MATCH (a)-[r]->() RETURN a.name, type(r)结果如图
14. 查询所有有结婚关系的节点
MATCH (n)-[:MARRIED]-() RETURN n结果如图
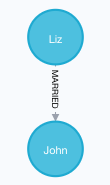
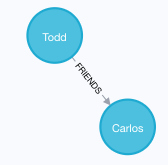
15. 创建节点的时候就建好关系
CREATE (a:Person {name:'Todd'})-[r:FRIENDS]->(b:Person {name:'Carlos'})结果如图
16. 查找某人的朋友的朋友
MATCH (a:Person {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName返回Mike的朋友的朋友:

17. 增加/修改节点的属性
MATCH (a:Person {name:'Liz'}) SET a.age=34
MATCH (a:Person {name:'Shawn'}) SET a.age=32
MATCH (a:Person {name:'John'}) SET a.age=44
MATCH (a:Person {name:'Mike'}) SET a.age=25这里,SET表示修改操作
18. 删除节点的属性
MATCH (a:Person {name:'Mike'}) SET a.test='test'
MATCH (a:Person {name:'Mike'}) REMOVE a.test删除属性操作主要通过REMOVE
19. 删除节点
MATCH (a:Location {city:'Portland'}) DELETE a删除节点操作是DELETE
20. 删除有关系的节点
MATCH (a:Person {name:'Todd'})-[rel]-(b:Person) DELETE a,b,rel