一、读写过程
1、读:
(1)先读cache,如果数据命中则返回
(2)如果数据未命中则读db
(3)将db中读取出来的数据入缓存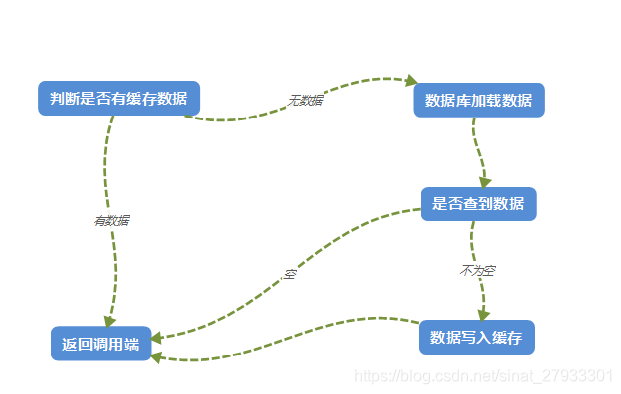
2、写:
(1)先淘汰cache
(2)再写db
二、数据不一致原因
先操作缓存,在写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致。
在分布式环境下,数据的读写都是并发的,上游有多个应用,通过一个服务的多个部署(为了保证可用性,一定是部署多份的),对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序,也就是说后发出的读请求很可能先完成(读出脏数据)。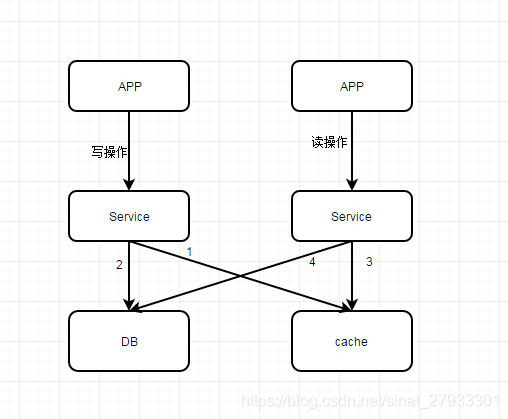
上图解析: 写操作先执行1,删除缓存,再执行2,更新db;而读操作先执行3,读取cache数据,未找到数据时执行4,查询db。
问题所在: 写操作2没执行完时,读操作4执行了,则读到了脏数据到cache中,造成了cache和db的数据不一致问题。
三、解决方案
方案1:Redis设置key的过期时间。
方案2:采用延时双删策略。
(1)先淘汰缓存
(2)再写数据库(这两步和原来一样)
(3)休眠1秒,再次淘汰缓存
这么做,可以将1秒内所造成的缓存脏数据,再次删除。(为何是1秒?需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。当然这种策略还要考虑redis和数据库主从同步的耗时。)