背景
阿里集团针对故障处理提出了“1/5/10”的目标-- 1 分钟发现、5 分钟定位、10 分钟恢复,这对我们的定位能力提出了更高的要求。
EMonitor 是一款集成 Tracing 和 Metrics,服务于饿了么所有技术部门的一站式监控系统,其覆盖了
- 前端监控、接入层监控;
- 业务 Trace 和 Metric 监控;
- 所有的中间件监控;
- 容器监控、物理机监控、机房网络监控。
每日处理总数据量近 PB,每日写入指标数据量上百 T,日均几千万的指标查询量,内含上万个图表、数千个指标看板,并且已经将所有层的监控数据打通并串联了起来。但是在故障来临时,用户仍然需要花费大量时间来查看和分析 EMonitor 上的数据
比如阿里本地生活的下单业务,涉及到诸多应用,每个应用诸多 SOA 服务之间错综复杂的调用关系,每个应用还依赖 DB、Redis、MQ 等等资源,在下单成功率下跌时,这些应用的负责人都要在 EMonitor 上查看指标曲线以及链路信息来进行人肉排障以自证清白,耗时耗力,所以自动化的根因分析必不可少。
根因分析建模
业界已经有好多在做根因分析的了,但是大都准确率不高,大部分还在 40% 到 70% 之间,从侧面说明根因分析确实是一个难啃的骨头。
根因分析看起来很庞大,很抽象,无从下手,从不同的角度(可能是表象)去看它,就可能走向不同的路。那如何才能透过表象来看到本质呢?
我这里并不会一开始就给你列出高大上的算法解决方案,而是要带你重新认知根因分析要解决的问题到底是什么。其实好多人对要解决的问题都模糊不清,你只有对问题理解清楚了,才能有更好的方案来解决它。
要解决什么样的问题
举个例子:现有一个应用,拥有一堆容器资源,对外提供了诸多 SOA 服务或者 Http 服务,同时它也依赖了其他应用提供的服务,以及 DB 资源、Redis 资源、MQ 资源等等;那我们如何才能够全面的掌控这个应用的健康状况呢?
我们需要掌控:
- 掌控这个应用的所有入口服务的「耗时」和「状态」
- 掌控每个入口服务之后每种操作的「耗时」和「状态」
一个应用都有哪些入口?
- SOA 服务入口;
- Http 服务入口;
- MQ 消费消息入口;
- 定时 job 入口;
- 其他的一些入口。
进入每个入口之后,都可能会有一系列的如下 5 种操作和 1 种行为(下面的操作属性都是以阿里本地生活的实际情况为例,并且都包含所在机房的属性):
- DB 远程操作:有 dal group、table、operation(比如select、update、insert等)、sql 的操作属性;
- Redis 远程操作:有 command 的操作属性;
- MQ 远程操作(向MQ中写消息):有 exchange、routingKey、vhost 的操作属性;
- RPC 远程操作:有 远程依赖的 appId、远程 method 的操作属性;
- Local 操作(即除了上述4种远程操作之外的本地操作): 暂无属性;
- 抛出异常的行为:有异常 name 的属性。
那我们其实就是要去统计每个入口之后的 5 种操作的耗时情况以及状态情况,以及抛出异常的统计情况。
针对远程操作其实还要明细化,上述远程操作的每一次耗时是包含如下 3 大部分:
- 客户端建立连接、发送请求和接收响应的耗时;
- 网络的耗时;
- 服务器端执行的耗时。
有了上述三要素,才能去确定远程操作到底是哪出了问题,不过实际情况可能并没有上述三要素。
故障的结论
有了上述数据的全面掌控,当一个故障来临的时候,我们可以给出什么样的结论?
- 哪些入口受到影响了?
- 受影响的入口的本地操作受到影响了?
- 受影响的入口的哪些远程操作受到影响了?
- 具体是哪些远程操作属性受到影响了?
- 是客户端到服务器端的网络受到影响了?
- 是服务器端出了问题吗?
- 受影响的入口都抛出了哪些异常?
上述的这些结论是可以做到非常高的准确性的,因为他们都是可以用数据来证明的。
然而第二类根因,却是无法证明的:
- GC 问题;
- 容器问题。
他们一旦出问题,更多的表现是让上述 5 种操作耗时变长,并且是没法给出数据来明确证明他们和 5 种操作之间的关联,只是以一种推测的方式来怀疑,从理论上来说这里就会存在误定位的情况。
还有第三类更加无法证明的根因:
- 变更问题
昨天的变更或者当前的变更到底和当前的故障之间有没有关联,更是无法给出一个证明的,所以也只能是瞎推测。
我们可以明确的是 5 种操作的根因,还需要进一步去查看是否是上述第二类根因或者第三类根因,他们只能作为一些辅助结论,因为没法给出严谨的数据证明。
根因分析实现
在明确了我们要解决的问题以及要求的故障结论之后,我们要采取什么样的方案来解决呢?下面首先会介绍一个基本功能「指标下钻分析」。
指标下钻分析
一个指标,有多个 tag,当该指标总体波动时,指标下钻分析能够帮你分析出是哪些 tag 组合导致的波动。
比如客户端的 DB 操作抖动了,利用指标下钻分析就可以分析出
- 哪个机房抖动了?
- 哪个 dal group 抖动了?
- 哪张表抖动了?
- 哪种操作抖动了?
- 哪个 sql 抖动了?
再比如远程 RPC 操作抖动了,利用指标下钻分析就可以分析出
- 哪个机房抖动了?
- 哪个远程 appId 抖动了?
- 哪个远程 method 抖动了?
其实这个就是去年 AIOPS 竞赛的题目,详细见:
http://iops.ai/competition_detail/?competition_id=8&flag=1
通常的方案:
- 对每个时序曲线都要进行数据预测,拿到预测值;
- 针对每个方案根据实际值和预测值的差异算出一个方案分数;
- 遍历所有可能性方案,挑选出分数最高的方案(通过蒙特卡洛树搜索进行剪枝优化)。
我们的方案:
- 确定整体的波动范围;
- 确定计算范围 = 该波动范围 + 前面一段正常范围,在计算范围内算出每根时间线的波动值(比如波动的方差,实际肯定不会这么简单,有很多的优化点);
- 对所有时间曲线进行一些过滤(比如和整体抖动方法相反,整体都向上抖动,它向下抖动);
- 对过滤后的时间曲线按照波动值进行 KMeans 聚类;
- 从排名靠前的分类中挑选出方案,为每个方案计算方案分数(这个方案个数就非常之少了);
- 得出分数最高的方案。
针对去年的决赛题目,我们的这个方案的跑分达到了 0.95 以上,应该就在前三名了。
根因分析流程
有了指标下钻分析功能之后,我们来看如何进行根因分析:
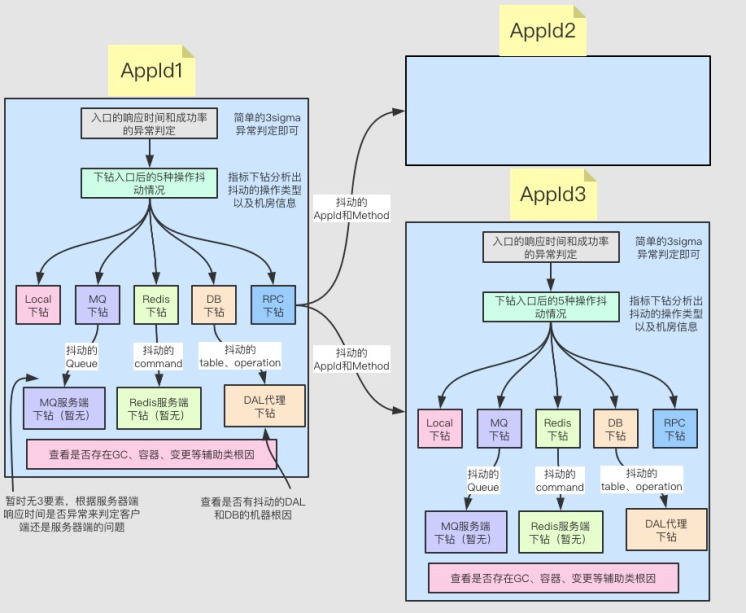
- 针对入口服务的响应时间和成功率判断是否异常,若无异常则无根因可分析;
- 针对入口服务的 5 种操作进行指标下钻分析,得出异常波动的操作类型有哪些;
- 然后到对应操作类型的指标中再次进行指标下钻分析,得出该操作下:
- 哪些入口受到该操作的波动影响了?
- 哪些操作属性异常波动了?
- 假如该操作是远程操作,还要继续深入服务器端进行分析:
假如你有远程操作数据的 3 要素的话,那么是可以分析出:
- 客户端建立连接、发送请求和接收响应耗时问题;
- 网络耗时问题;
- 服务器端耗时问题。
假如没有相关数据的话,那就只能相对来说进行推测了(准确率也会受到影响):
- 假如服务器端耗时正常的话,那就相对划分为客户端发送请求或接收响应耗时是根因;
- 假如服务器端耗时异常抖动的话,那么就需要到服务器端进行深入分析;
- 比如 DB 操作来说,可以继续深入到 DAL 层面分析:DAL 是我们的分库分表的数据库代理层,同时起到一些熔断限流的作用,所以一条 SQL 执行时间会包含在 DAL 代理层的停留时间、以及在 DB 层的执行时间,利用指标下钻分析,可以分析出如下的一些根因:
- 某个 table 的所有操作耗时抖动?
- 某条sql操作耗时抖动?
- 某台具体DB实例抖动?
- SQL的停留时间 or 执行时间抖动?
- 比如客户端的 RPC 操作来说,可以继续递归到远程 appId 的;- 针对受影响的这些入口使用指标下钻分析,哪些异常也抖动了(有些异常一直在抛,但是跟本次故障无关);
- 再次查看上述抖动的操作是否是由 GC 问题、容器问题、变更问题等引起的。
落地情况
阿里本地生活的根因分析能力,1 个月内从产生根因分析的想法到实现方案上线到生产(不包括指标下钻分析的实现,这个是之前就已经实现好的了),1 个月内在生产上实验和优化并推广开来,总共 2 个月内实现了从 0 到 1 并取得了如下成绩
- 50 个详细记载的案例中准确定位 48 次,准确率 96%;
- 最高一天执行定位 500 多次;
- 平均定位耗时 1 秒;
- 详细的定位结果展示。
我们对定位准确性的要求如下:
- 要明确给出受到影响的入口服务有哪些;
- 每个受到影响的入口服务抖动的操作根因以及操作属性都要正确;
每个入口服务抖动的根因很可能不一样的,比如当前应用的 SOA1 是由于 Redis 操作抖动,当前应用的 SOA2 是由于远程 RPC 依赖的其他 SOA3 抖动导致,SOA3 是由于 Redis 操作抖动导致;
- 客户端操作耗时抖动到底是客户端原因还是服务器端原因要保证正确;
- 容器问题时,要保证不能定位到错误的容器上。
准确率为什么这么高?
我认为主要是以下 3 个方面:
数据的完整度
假如是基于采样链路去分析,必然会存在因为漏采导致误判的问题。
我们分析的数据是全量链路数据转化成的指标数据,不存在采样的问题,同时在分析时可以直接基于指标进行快速分析,临时查采样的方式分析速度也是跟不上的。
建模的准确性
你的建模方案能回答出每个 SOA 服务抖动的根因分别是什么吗?
绝大部分的建模方案可能都给不出严谨的数据证明,以 DB 是根因为例,他们的建模可能是 SOA 服务是一个指标,DB 操作耗时是一个指标,2 者之间是没有任何关联的,没有数据关联你就给不出严谨的证明,即没法证明 DB 的这点抖动跟那个 SOA 服务之间到底有没有关联,然后就只能处于瞎推测的状态,这里就必然存在误判的情况。
而我们上述的建模是建立了相关的关联,我们会统计每个入口后的每种操作的耗时,是可以给到严谨的数据证明。
异常判定的自适应性
比如 1 次 SOA 服务整体耗时 1s,远程调用 RPC1 耗时 200ms,远程调用 RPC2 耗时 500ms,到底是哪个 RPC 调用耗时抖动呢?耗时最长的吗?超过一定阈值的 RPC 吗?
假如你有阈值、同环比的限制,那么准确率一定不高的。我们的指标下钻分析在解决此类问题的时候,是通过当前情况下的波动贡献度的方式来计算,即使你耗时比较高,但是和之前正常情况波动不大,那么就不是波动的根因。
速度为什么这么快?
我认为主要是以下 2 方面的原因:
业内领先的时序数据库 LinDB
根因分析需要对诸多指标的全量维度数据进行 group by 查询,因此背后就需要依靠一个强大的分布式时序数据库来提供实时的数据查询能力。
LinDB 时序数据库是我们阿里本地生活监控系统 E-Monitor 上一阶段的自研产物,在查询方面:
- 强悍的数据压缩:时序数据原始数据量和实际存储量之比达到 58:1,相同 PageCache 的内存可以比别的系统容纳更多的数据;
- 高效的索引设计:索引的预过滤,改造版的 RoaringBitmap 之间的 and or 操作来进行高效的索引过滤;
- 单机内充分并行化的查询机制:利用 akka 框架对整个查询流程异步化。
整体查询效率是 InfluxDB 的几倍到几百倍,详细见文章
分布式时序数据库 - LinDB https://zhuanlan.zhihu.com/p/35998778
指标下钻分析算法的高效
- 我们不需要每个时间线都进行预测;
- 实际要计算的方案个数非常之少;
- 方案算分上可以适应于任何加减乘除之类的指标计算上,比如根因定位中的平均响应时间 = 总时间 / 总次数
SOA1 的平均响应时间 t1 和 SOA2 的平均响应时间 t2,SOA1 和 SOA2 的总体平均响应时间并不是 t1 和 t2 的算术平均而是加权平均,如果是加权平均,那么久需要多存储一些额外的信息,并且需要进行额外的加权计算
实际案例
案例 1
故障现场如下,某个应用的 SOA 服务抖动上升:
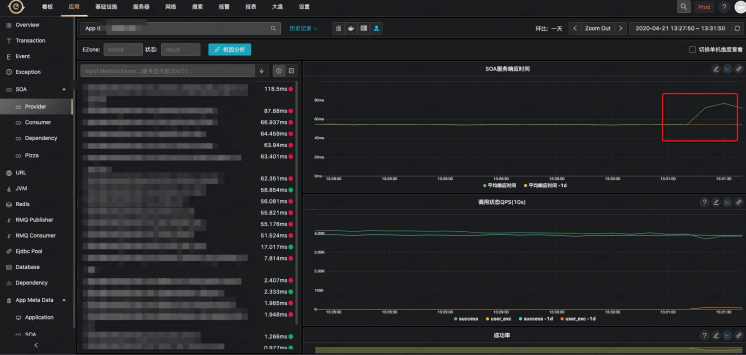
直接点击根因分析,就可以分析到如下结果
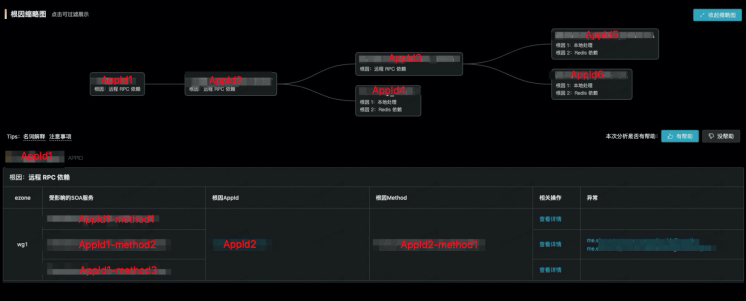
AppId1 的 SOA 服务在某个机房下抖动了
- 依赖的 AppId2 的 SOA 服务抖动
- 依赖的 AppId3 的 SOA 服务抖动
- 依赖的 AppId5 的本地处理和 Redis 操作耗时抖动
- 依赖的 AppId6 的本地处理和 Redis 操作耗时抖动
- 依赖的 AppId4 的本地处理和 Redis 操作耗时抖动
这里的本地处理包含获取 Redis 连接对象 Jedis 的耗时,这一块没有耗时打点就导致划分到本地处理上了,后续会进行优化。这里没有给出详细的 Redis 集群或者机器跟我们的实际情况有关,可以暂时忽略这一点。
点击上面的每个应用,下面的表格都会列出所点击应用的详细故障信息
- 受影响的 SOA 服务有哪些,比如 AppId1 的 3 个 SOA 服务受到影响;
- 每个 SOA 服务抖动的根因,比如 AppId1 的 3 个 SOA 服务都受到 AppId2 的 1 个 SOA 服务的抖动影响;
- 表格中每一个链接都可以跳转到对应的指标曲线监控面板上。
再比如点击 AppId4,显示如下:
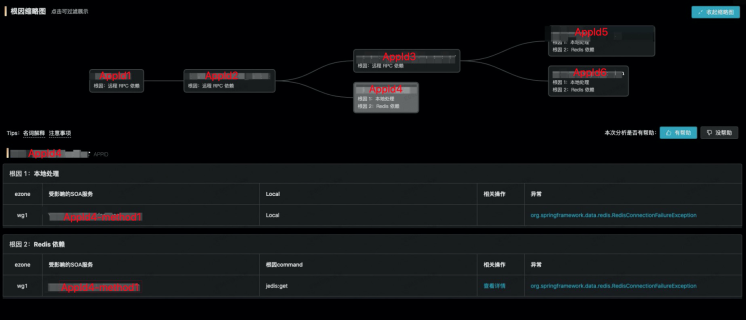
AppId4 的 1 个 SOA 方法抖动
- 该方法的本地处理抖动(实际是获取 Redis 连接对象 Jedis 的耗时抖动);
- 该方法依赖的 Redis 操作抖动;
- 该方法抛出 Redis 连接异常;
案例2
故障现场如下,某个应用的 SOA 服务抖动上升
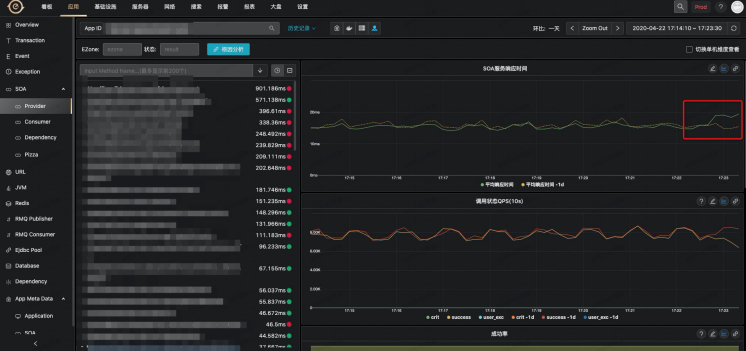
点击根因分析,就可以帮你分析到如下结果
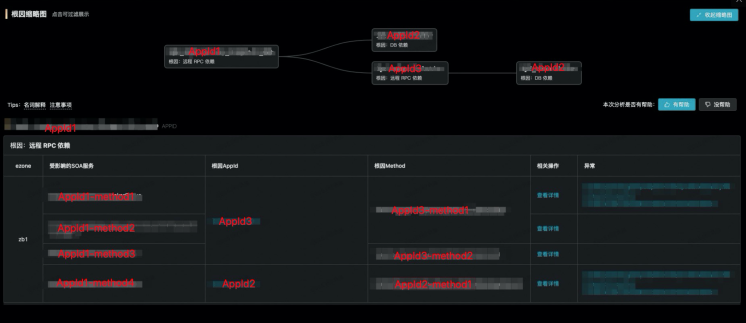
AppId1 的 SOA 服务在某个机房下抖动了
- 依赖的 AppId2 的 SOA 服务抖动
- 依赖的 DB 服务抖动
- 依赖的 AppId3 的 SOA 服务抖动
- 依赖的 AppId2 的 SOA 服务抖动
- 依赖的 DB 服务抖动
点击 AppId2,可以看下详细情况,如下所示:
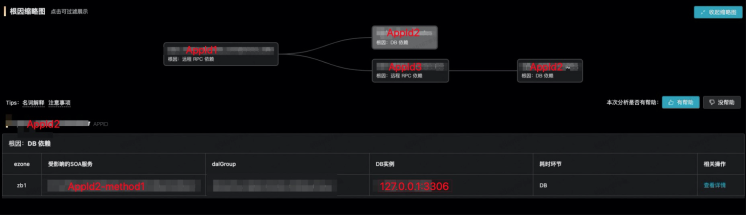
从表格中就可以看到,根因是 DB 的一台实例抖动导致这个 dal group 所有操作抖动。
作者
李刚,网名乒乓狂魔,饿了么监控组研发专家,饿了么内部时序数据库 LinDB 的项目负责人,饿了么根因分析项目负责人,目前致力于监控的智能分析领域以及下一代全景监控的体系化构建;
林滨(予谱),饿了么监控组前端工程师,现负责一站式监控系统 EMonitor 的前端开发,旨在将繁杂的数据以高可视化输出。
上云就看云栖号:更多云资讯,上云案例,最佳实践,产品入门,访问:https://yqh.aliyun.com/
本文为阿里云原创内容,未经允许不得转载。