face r-cnn是腾讯ai实验室的作品,而且登录过腾讯ai实验室官网,发现果然硕果累累,不得不佩服。
1 引言
人脸检测虽然相对之前有了不小的进步,可是还是因为真实世界中人脸图像的明显变化导致仍然极具挑战。

图1中的人脸就同时包含了遮挡,光照,尺度,姿态和表情。
而随着近来faster rcnn的流行,也有不少人直接基于此去训练适合人脸检测任务的。可是faster rcnn原生态的模型还是有许多不足的,比如
- softmax loss函数:该函数倾向于区分特征之间的类间可分性,不能获取类内的紧凑性。
而前人的工作已经证明了对于CNN特征,不管是类间可分性,还是类内紧凑性都十分重要。为了减少类内变化并且拉大类间距离,作者在Faster R-CNN框架的原有loss函数上增加了一个新的loss函数叫做center loss。通过增加center loss,类内变化可以有效的减小,相对的让学到的特征辨别力增强。
为了进一步提升检测的准确度,这里采用了在线硬样本挖掘(online hard example mining, OHEM)和多尺度训练策略。
2 结构
为了延续faster rcnn的辉煌,作者:
- 在该架构上增加了一个新的多任务loss函数去扶助训练有无人脸的二值分类器;
- 用在线硬样本挖掘算法生成硬样本以供后续处理;
- 使用多尺度训练策略去帮助提升检测性能。
如图所示该网络结构包含一个ConvNet,一个RPN,和一个Fast RCNN模块:- ConvNet:是一个卷积层和最大池化层的堆叠,用来生成卷积feature map;
- RPN:该模块生成一系列的矩形区域候选框,这些候选框大概率都包含了人脸。是一个全卷积网络,构建在卷积feature map上。该RPN的loss层包含一个二值分类层和一个边界框回归层;
- Fast R-CNN:生成的区域候选框会被送入Fast RCNN模块,并作为ROI区域。ROI层处理这些ROIs去提取固定长度的特征向量。最终输出到两个分开的全连接层用于分类和回归。
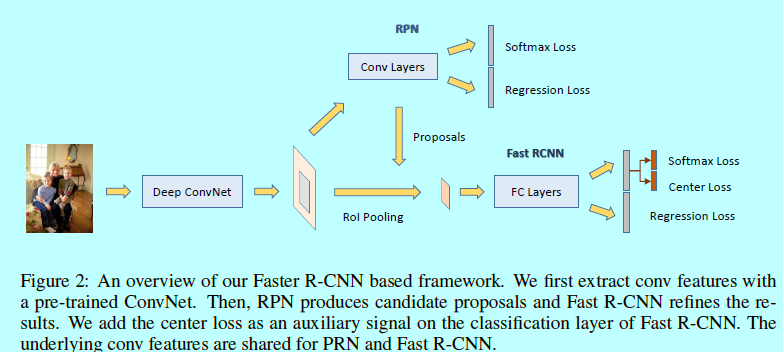
face rcnn与经典的faster rcnn的差别不在RPN部分,而是在对应的fast r-cnn中,作者基于一个新提出的center loss,设计了一个新的多任务loss函数。如下面所述。
3 Loss 函数
3.1 center loss
center loss函数被证明在人脸识别任务中有很好的效果,center loss的基本思想是鼓励网络学习辨识性特征,以此来最小化类内变化,同时扩大类间变化。center loss的公式:
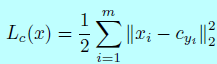
这里(x)表示输入的特征向量,(c_{y_i})表示第(y_i)个类中心。这些类中心是在每次的mini-batch迭代时更新的,所以它可以很容易的通过SGD训练。对于人脸检测任务,只有2个中心:有人脸和没有人脸。我们的目的是最小化类内变化。
center loss支持与softmax loss联合最优化。而且center loss可以很大程度上减少类内变化,同时softmax loss在最大化类间变化上有些优势。所以就很自然的将center loss和softmax结合起来去共同推进特征的辨识性。
3.2 多任务loss
对于RPN阶段,采用的是多任务loss,该loss是基于结合box-分类loss和box-回归loss:
- 分类loss:关于是前景还是背景的二分类的softmax loss;
- 回归loss:这里采用的是平滑L1范式。
对于fast r-cnn阶段,我们基于之前提到的center loss设计了一个多任务loss。我们使用center loss和softmax loss结合来作为分类任务的loss;然后用平滑L1 loss作为边界框回归的任务。整个loss函数形式如下:
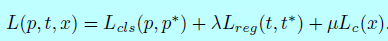
这里(p)是预测当前候选框是人脸的概率。(p^*)是ground-truth,如果为1则表示是正样本,为0则表示负样本。t是一个向量,对应着预测边界框的4个参数化坐标,(t_*)是对应的ground-truth。这里平滑L1 用于回归。超参数(lambda,mu)用来可能告知三个loss之间的平衡。
3.3 在线硬样本挖掘
在线硬样本挖掘(online hard example mining, OHEM)是一个简单但是十分有效的引导技术。关键的想法是收集硬样本,即那些预测不正确的,将这些样本输送给网络以增强分辨性。因为loss可以表示当前网络拟合的程度,所以可以通过他们的loss将生成的候选框进行排序,然后只提取前N个最差的样本作为硬样本。
标准的OHEM会遇到数据不平衡的问题,因为选择的硬样本可能其中负样本的量很可能压倒性的超过正样本的量(或者反过来)。并且注意到,当使用center loss的时候,保持正和负的训练样本的平衡对于训练阶段来说十分重要。最后,我们在正样本和负样本上分别独立使用OHEM,并在每个mini-batch中将正负样本的比例保持1:1.
在训练的时候,OHEM与SGD交替的执行。对于一次SGD迭代,OHEM是通过前向一次当前的网络实现的。然后将选择的硬样本在下一次迭代中使用。
3.4 多尺度训练
作者设计了一个多尺度训练方法:在训练过程中,将原始图片缩放到不同尺寸,这样学到的模型就能更适应小分辨率的人脸;在预测阶段,也进行对应的多尺度预测,然后将不同尺度下预测的边界框在结合到最终的输出中。
4 实现
4.1 实现细节
我们使用在基于ImageNet上预训练好的VGG19,在RPN阶段,锚是具有多个尺度和长宽比例的:
- 与ground-truth的IOU超过0.7的视为正样本;
- 与ground-truth的IOU低于0.3的视为负样本。
在fast rcnn阶段:
- 将IOU超过0.5的为正样本;
- IOU在0.1到0.5之间的视为负样本。
在RPN的候选框上需要执行NMS,在其阈值为0.7,一共生成2k个候选框,这些候选框随后通过OHEM方法选择硬样本用于给fast rcnn做训练。其中RPN的batch-size为256;fast rcnn的batch-size为128.
在预测阶段,NMS的阈值为0.3。
参考文献:
- [1] [CMS-RCNN] C. Zhu, Y. Zheng, K. Luu, and M. Savvides. CMS-RCNN: Contextual multi-scale region-based cnn for unconstrained face detection. arXiv preprint arXiv:1606.05413, 2014.
- [2] H. Jiang and E. Learned-Miller. Face detection with the Faster R-CNN. arXiv preprint arXiv:1606.03473, 2016.
- [3] S. Wan, Z. Chen, T. Zhang, B. Zhang, and K. Wong. Bootstrapping face detection with hard negative examples. arXiv preprint arXiv:1608.02236, 2016.
- [4] X. Sun, P. Wu, and S. Hoi. Face Detection using Deep Learning: An Improved Faster RCNN Approach. arXiv preprint arXiv:1701.08289, 2016.
- [5] A. Shrivastava, A. Gupta, and R. Girshick. Training Region-based Object Detectors with Online Hard Example Mining. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016