该文来自《SSH: Single Stage Headless Face Detector》,本文时间线2017年8月。
不同于face rcnn那种两阶段的方法,SSH和ssd一样是一阶段的方法。其从一个分类网络的前面卷积层直接检测人脸。这里所谓的Headless是移除潜在的分类网络的"头",而且SSH本身就是基于尺度不变设计的,所以不需要做图像金字塔。通过不同层上同时检测不同尺度的人脸。这些属性使得SSH即快而且轻量。而且实测发现,在WIDER数据集上采用headless VGG16的效果超过了ResNet-101.而且SSH不使用图像金字塔,所以有5X的加速,而如果SSH配合图像金字塔使用,则可以全面超过其他方法。
0 引言
现在最好的人脸检测方法都需要大量的参数去保证尺度鲁棒性或者上下文整合,所以速度都很慢或者需要很大的内存,如《finding tiny faces》需要超过1s才能处理一张图片。而SSH的Headless表示的是去除网络的头。对于VGG-16,其中的fc6-8层可以看成是该网络的head,其计算代价很大(VGG-16网络头包含大约120M个参数,ResNet-101的头包含大约12M个参数),而且在二阶段模型中,必须在所有提出的候选框上都计算一次。
相对而言,本文中SSH模型就更轻量一些。和RPN一样,分类网络的前面feature maps都可以用来回归一系列预定义的锚。然而,不同于2阶段的检测器,这里最后的分类部分也同时会对这些锚进行回归拟合:
- SSH的headless,正是因为去除了具有大量的参数部分,从而变得更快更轻量;
- 不依赖外部多尺度图像金字塔保证尺度不变性,SSH从网络的不同层上检测人脸。

1 SSH
SSH设计的初衷是为了减少inference时间,并且只需要很少的内存,同时具有尺度不变性。
1.1 结构
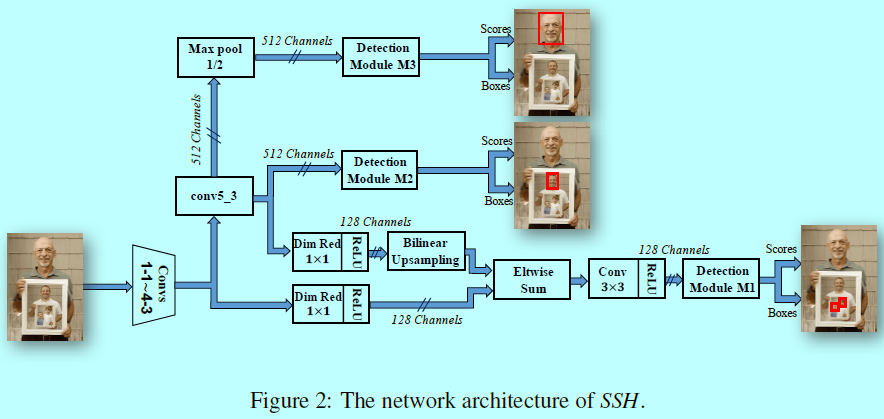
如图2所示,SSH是一个全卷积网络,通过在feature maps顶层增加检测模块来完成人脸定位和分类,对应的strides是8,16,32,分别表示为(M_1,M_2,M_3)。检测模块包含一个卷积二值分类器和为了检测人脸和定位的回归器。
为了解决定位问题,SSH将一些预定义的边界框(称为锚)与ground-truth进行回归。作者通过使用一个与RPN相似的策略:
- 在每一个划窗位置上,定义K个锚,其中包含了不同的尺度;
- 只考虑长宽比为1的锚来减少锚的个数。
作者发现在实验中使用不同的长宽比对人脸检测效果提升不大,而且SSH中连接着(W_i imes H_i)大小feature map的检测模块(M_i),有(W_i imes H_i imes K_i)个长宽比为1的锚,其对应尺度为({S_i^1,S_i^2,...S_i^{K_i}})。
对于检测模块
一系列卷积层被用来提取特征以供人脸检测和定位,如图3
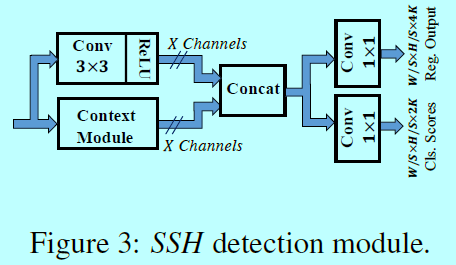
这包含了一个简单的上下文模块来增加感受野的有效性。上下文模块的输出通道数量(图3 和图4的“X”)在(M_1)被设为128,在(M_2,M_3)中被设为256。最后2个卷积层用来进行边界框回归和分类。在(M_i)中每个卷积位置,分类器判别当前以滤波器为中心的,不同尺度({S_i^K}_{k=1}^K)的划窗是否包含人脸。
- 这里的分类器:就是一个1x1的卷积层与2xK个输出通道组成的结构;
- 这里的回归器:就是一个1x1的卷积层与4xK个输出通道组成的结构。
1.2 尺度不变的设计
SSH可以在一次前向传输中同时检测大人脸和小人脸,受到《Feature pyramid networks for object detection》的启发,SSH从三个不同的卷积层上检测人脸,对应的检测模块(M_1,M_2,M_3)。这三个模块对应的strides为(8,16,32),就是分别用来检测小型,中型,大型人脸。
检测模块(M_2)是接在VGG-16的conv5-3上的,虽然可以直接将检测模块(M_1)接在conv4-3上,不过这里还是考虑了feature map融合的方式。为了减少内存的消耗,feature map中的通道数通过1x1卷积从512减少到128。conv5-3 feature map会上采样(双线性上采样)然后与conv4-3 feature map结合起来,然后跟一个3x3的卷积层。为了检测更大的人脸,在conv5-3上接一个stride等于2的最大池化,使其stride增大到32。检测模型(M_3)放在新加的层上面。
在训练阶段,每个检测模块(M_i)是用来训练检测不同尺度范围的;在预测阶段,会将所有尺度上的预测结果通过NMS进行处理并生成最后的检测。
1.3 上下文模块
在二阶段检测器中,通常都是扩大候选框来融合上下文;而SSH是通过简单的卷积层来模拟这种策略。

如图4,将上下文层融合进检测模块。因为锚是以卷积方式进行分类和回归,所以采用更大的滤波器就类似二阶段中的扩大候选框方式。本文中上下文模块中是采用5x5和7x7的滤波器。以这种方式对上下文进行建模增加了对应层的感受野,同时也增加了每个检测模块中的目标尺度。为了减少模型参数量,作者使用类似《Going deeper with convolutions》的方法,并采用了序列3x3的滤波器代替较大的卷积滤波器。检测模块的输出通道的个数(图4中"X")(M_1)中为128,(M_2,M_3)中分别为256。在本文中使用的带上下文滤波器的检测模块相比《Faster r-cnn: Towards real-time object detection with region proposal networks》拥有更少的参数。作者在实验中还发现上下文模块提升了WIDER上的MAP。
1.4 训练和loss函数
本文算法中,只有当IOU大于0.5的时候才将该锚与ground-truth相对比,而Faster rcnn中是每个ground-truth至少有一个锚(与最高IOU对比),所以这里BP不会迭代与ground-truth不匹配的锚。SSH是一个多任务loss,该loss公式为:

- 这里(ell_c)是人脸分类loss,这里使用的是标准的多项log的 loss。索引K表示第几个检测模块(M= {M_k}_1^K),并且(A_K)表示定义在(M_k)中的锚的集合。在(M_k)中第(i)个锚和对应的ground-truth标签表示为(p_i,q_i)。这里锚中正样本为与ground-truth的IOU超过0.5;而负样本是与任何ground-truth的IOU都小于0.3的那些锚。(N_k^c)是模块(M_k)中锚的个数,会参与分类loss的计算。
- (ell_r)表示边界框回归的loss,如《Faster r-cnn: Towards real-time object detection with region proposal networks》一样,回归空间是基于框维度的log空间迁移和尺度不变性的变换,使用(ell_1)平滑loss。在这个参数化空间中,(b_i)表示预测框的值,(t_i)表示ground-truth的值。(I(dot))是指示函数,用于限制回归loss只对可能关联的锚负责,(N_k^r=sum_{i in A_k}I(g_i=1))。
1.5 在线硬负和正样本挖掘
这里使用《Training regionbased object detectors with online hard example mining》中的OHEM。并且对于每个检测模块独立的使用各自的OHEM。也就是对每个模块(M_k),基于最高得分选择负锚,基于最低得分选择正锚。因为负锚的数量超过正锚,如《Fast r-cnn》,mini-batch中25%保留下来用于做正锚。
2 实验
在实验中,主要分析了:
- 尺度不变性设计;
- 输入尺寸的影响;
- OHEM的影响;
- 特征融合的影响;
- 锚尺度的选择等等。