高并发解决方案 之限流-基础
- 高并发之扩容思路

- 高并发之缓存




- 缓存并发问题--枷锁

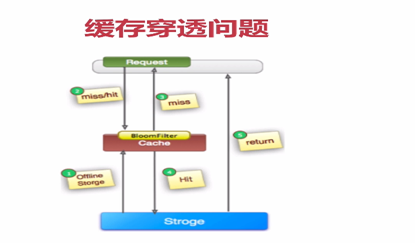
缓存穿透问题
如何避免缓存穿透
1.缓存空对象,对查询结果为空的对象也进行缓存,如果是集合可以缓存一个空集合但不是null,如果是缓存单个对象可以通过字段标识来区分,
这样避免请求穿透到后端数据库,同时也需要保存缓存数据的实效性。
2.单独过滤处理,对所有可能对应数据为空的key做统一存放,适合命中不高且跟新不频繁数据。
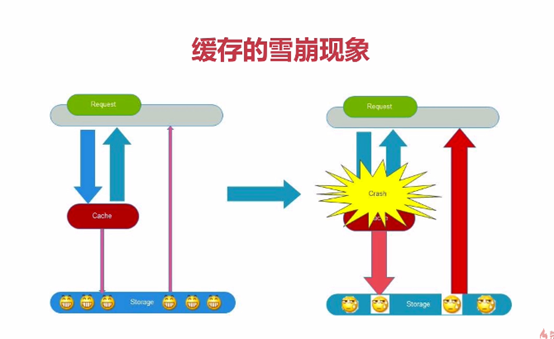
缓存的雪崩现象
缓存抖动-----缓存节点故障导致的
举例股票分时线缓存使用:
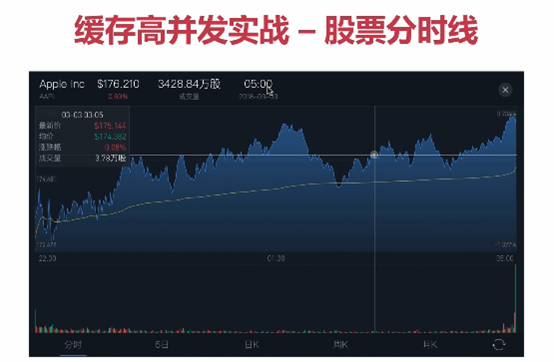
首先利用guava cache 缓存 最近几分钟内所有股票的分时数据,key 是数据时间,单位是分钟,一分钟内多次推送 会覆盖, 每分钟最多缓存一条数据,再用一个定时任务每分钟将最近几分钟的数据都写到redis中,保证redis中数据一直是最新的,用redis hash数据结构
- 高并发之消息队
-
为什么需要消息队列
生产和消费的速度或稳定性等因素不一致。
-
消息队列的好处
- 业务解耦
- 最终一致性---主要用记录和补偿方式处理,结果分三种,成功失败,不确定(超时等)对失败和不确定,我们可以用定时器 将失败的任务重新做一次。
- 广播
- 错峰与流控
- 高并发之应用拆分
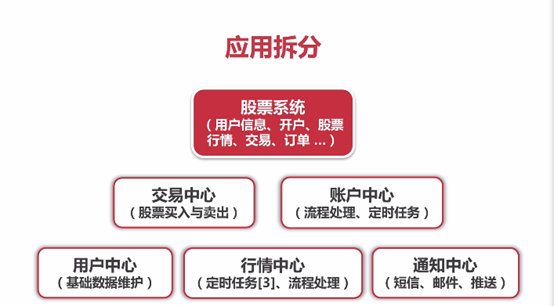

dubbo 框架, 微服务
- 高并发之应用限流
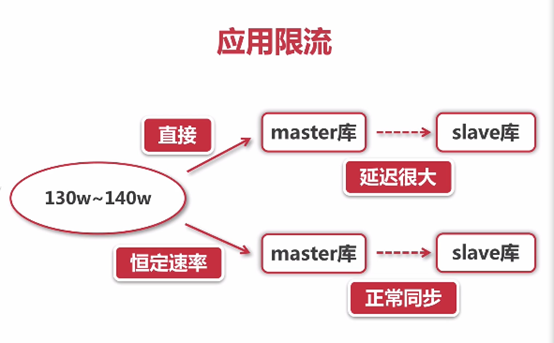
1.限制总并发数
2.限制瞬时并发数
3.限制时间窗口内的平均速率

- 限流算法-计数器法(最简单 )
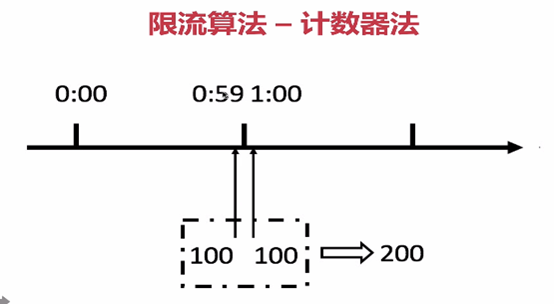
例:对a接口来说 一分钟访问次数不能超过100次,
- 做法如下: 最开始设置一个计数器counter,每当一个请求过来 counter就加1,当counter大于100并且该请求与第一个请求时间间隔在1分钟内,
那么说明请求数过多,如果大于一分钟,并且counter在100以内 就重置counter

问题:瞬间请求过多
一个用户在0:59秒 瞬间请求100,并在1分钟时请求了100,那么其实这个用户在1秒里面,瞬间发送了200个请求。用户通过在时间窗口这个重置节点发请求 可以瞬间超过数据限制,
用户可以通过这个算法的漏洞瞬间压垮我们的应用。原因是统计精度太低了。
- 限流算法-滑动窗口
下图 整个红色巨型 代表的是一个时间窗口假设他是1分钟,我们相当于将这个时间窗口进行了划分,下图相当于把时间窗口划分成6格,每个代表 10秒钟,每过10秒,时间窗口就向右滑动一格,
每个格子都有 自己独立的计数器 ,看滑动窗口如何解决上面的临界问题:
0:59秒来的100个请求,会落在灰色格子中,1分钟到达的请求会落在橘黄色的格子中,当时间到达一分是滑动窗口会向前移动一格,此时时间窗口中总请求数量是100+100=200,超过限制,可以检测出来触发了限流。所以格子分的越细,滑动窗口过度越平滑。

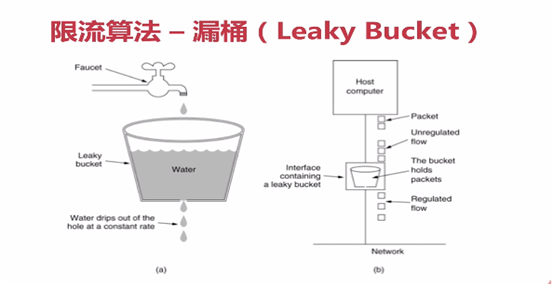
- 限流算法 -漏桶算法(Leaky Bucket)
如下图,首先有一个固定容量的桶,有水溜进来,也有水溜出去,对于流进来的水来说,我们无法预计一共有多少水回流进来,也无法预计水流的速度,但对于流出去的水来说,
这个桶可以固定水溜出去的速率,而且当桶满了之后 多余的水还会溢出去。
我们将算法的水换成实际应用中的请求,漏桶算法天生就限制了请求的速度,当时用了漏桶算法,我们可以保证接口可以一个恒定的速率处理请求,所以漏桶算法天生不会出现临界问题。
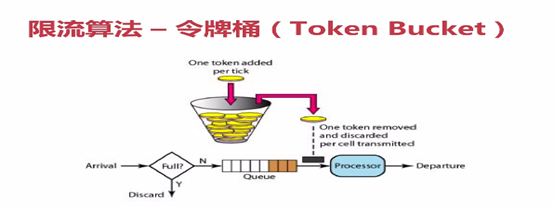
- 限流算法-令牌桶(Token Bucket)
首先有一个固定容量的桶,桶里存放着令牌就是Token,桶一开始是空的,Token是以一个固定速率往桶里填充,直到达到痛的容量,多余的令牌才会被丢弃掉,当一个请求过来时,我们会尝试从桶里移除一个令牌,如果没有令牌,请求就没办法通过。令牌桶算法也可以很好解决临界问题
- 对比
- 计数器算法和滑动窗口对比:
计数器算法是最简单的限流算法,可以理解为他是滑动窗口的低精度版本,
滑动窗口由于需要存储多分计数器,所以需要跟多的存储空间
- 漏桶算法和令牌桶算法
令牌桶算法允许流量一定程度的突发,因为默认的令牌桶算法取走token是不需要耗费时间的,假设桶内有100个token时,那么可以瞬间允许100个请求通过,令牌桶算法由于实现简单,允许流量突发,
对用户跟友好,所以 应用的更多,当然了 具体情况具体分析
- 高并发之服务降级与服务熔断思路
1. 服务降级
当服务器压力剧增时,根据当前业务情况及流量,对一些服务和页面有策略的降级,以此缓解服务器资源的压力,以保证核心任务的正常运转,也保证部分甚至大部分客户能得到正确的响应,(就是如果当前请求处理不了,给一个默认的返回 )
分类:
自动降级:超时(异步机制探测恢复情况),
失败次数(异步机制探测恢复情况),
故障(有故障可以直接降级,补偿方案:兜底数据,缓存,默认值等),
限流(处理方案:排队的页面,无货,错误页等等)。
人工降级:秒杀、双十一大促
降级非重要的服务
2. 服务熔断
软件系统里 由于某些原因使得服务出现过载的现象,为了防止造成整个系统故障,从而采用的一种保护措施,也成为过载保护
3. 服务降级和服务熔断的对比

4. 服务降级要考虑的问题

一个功能强大的类Hystrix可以简单实现服务降级和熔断:

hystrix 号称防雪崩利器,通过隔离保护和自调节机制提供了强大的容错能力他可以避免任何一个第三方单点故障带来的级联影响,避免应用的阻塞

Hystrix在用户请求和服务之间加入了线程池。
Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间。线程数是可以被设定的。
原理:
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
熔断
熔断模式
该模式借鉴了电路熔断的理念,如果一条线路电压过高,保险丝会熔断,防止火灾。
熔断器
熔断器是位于线程池之前的组件。
用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。
熔断器的工作原理:
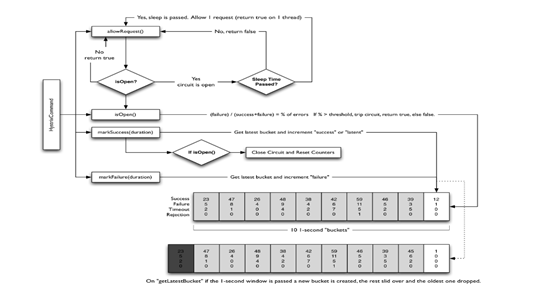
每个熔断器默认维护10个bucket;每秒创建一个bucket;每个blucket记录成功,失败,超时,拒绝的次数;
当有新的bucket被创建时,最旧的bucket会被抛弃
熔断算法
判断是否进行熔断的依据是:
根据bucket中记录的次数,计算错误率。
计算算法:(failure)/(success+failure)=% of errors if %>threshold,trip circuit, return true, else false
熔断恢复
对于被熔断的请求,并不是永久被切断,而是被暂停一段时间之后,允许部分请求通过,若请求都是健康的,则对请求健康恢复(取消熔断),如果不是健康的,则继续熔断。
服务调用的各种结果(成功,异常,超时,拒绝),都会上报给熔断器,计入bucket参与计算
- 高并发之数据库分库分表

1. 读写分离
动态数据源切换:

2. 数据库分表
例子:股票行情,把一张表分成520表 根据股票id对520取余分别将对应的分时数据存到不同的表里
3. 分表的好处
- 1.单表的并发能力提高了,io性能,写操作效率都提高了。
- 2.查询一次的时间短了
- 3.读写算影响数据量变小,插入数据库需要重新建立索引时间变少
4. 分表策略
横向分表:
把大表结果横向切割为同样的表,这时表结构是完全一样的,根据某些特定规则划分表,像上面说的 根据股票id取模进行画分,根据数据量的估摸画分,可以保证单表容量不会太大,从而单表的查询处理能力
纵向分表:
是将本来可以放到一个表里的内容,人为画分为多个表,通常根据数据活跃度来画分,因为不同活跃度的数据,处理方式是不同的。比如一个博客系统,文章标题作者分类,创建时间等,属于变化频率慢,查询次数多,需要有很好实时性的数据(叫做冷数据),而 博客的访问量博客数等等这些类似的统计信息或者别的变化频率高的数据(叫做活跃数据),根据活跃度把它们分到不通表里,来提高单表的处理能力
5. 分表实现mybatis分表插件shardbatis2.0:
以股票举例,当前在线股票9000+,每天开市期间每只股票最多会产生391条分时数据(就是大家看股票时的蜡烛图,开市时长为391分钟,每分钟至多1条数据),那样一天下来分时数据在 400 * 9000 = 360w 这个量级,实际存储的数据在130w~140w之间,这些数据都需要插入到数据库中。我们知道对于一般的数据库而言,单表达到百万甚至千万级别时,任何操作即使是select count(1) 也会变得很慢,这时分表是必须的。具体说一下我们分表的策略:每次对表执行插入时,找到对应的股票(对应本地的symbols表) 的 id,使用股票id%512作为表后缀。举个例子,股票的分时数据存储的表为timetrend_000 ~ timetrend_511, 股票A在symbols表里的id为513,那么A对应的分时数据存储表为:513%512=1 -> timetrend_001, 股票B在symbols表里的id为1128,那么B对应的分时数据存储表为:1128%512=104 -> timetrend_104。相信这个不难理解,接下来的问题就是如何从插入时动态选择表了
未完待续:
后期安排 :
- nginx限流
- openresty+LUA 限流
- 高并发之秒杀
- 高并发之抢红包