之前学习了Cousera上华盛顿大学的机器学习课程,近期准备整理当时的学习笔记。本篇总结是基于该专项课程中第一篇的内容
分类算法:
1.分类算法实际用途:情感分析等,比如分析餐馆的评论,根据某个人的评论内容推测他对餐馆的评分;又如根据网页文本预测网页标签(如金融,教育,科技等)
垃圾邮件过滤(Spam filtering)、
图片分类
情感分析线性分类器:
比如我们为某个APP构建一个简单的评论分类器,预测某个评论是积极还是消极,算法伪代码如下:
if(评论中词性为正的数量>评论中词性为负的数量) 该评论为积极评论 else ...
尽管算法看上去很直观,但仍存在一些问题:
1.单词的词性从哪来?
2.不能简单将词分为积极和消极,即便同样是积极词性的单词也有权重之分,比如good, awesome, perfect我们需要给予它们不同的权重。
3.我们不能仅仅根据某个单词判断它的词性,比如一个词是good,很可能评论是not good。
算法2:
根据每个单词的权重,将所有单词词性求和:
比如我们有一个权重表,如下:
awesome | 1 |
----------------------
awful | -1.5 |
-----------------------
我们给予不同的词不同权重(当然这里仅仅是一个事例,权重表中只有两个单词)在给评论打分时,可以进行如下计算
score(x) = 1*awesome在评论中出现的次数+(-1.5)*awful在评论中出现的次数
对于每个评论,我们都计算出它的得分,如果得分小于某个阈值,评论为负向评论,反之为正。
2.聚类算法和相似度:
1.聚类算法实际用途:对于一篇给定的文章,找出与它相似的文章,类似今日头条等网站对网页内容进行聚类。
2.工作原理:
文档表示方法:词袋模型,之所以用‘词袋‘这个词是因为在该算法中我们不关心网页中单词出现的先后顺序。
比如对一篇体育报道我们可以通过如下方式表示:
| 单词 | football | the | calls | sport | .... |
| 个数 | 1 | 2 | 2 | 2 | ..... |
当我们希望计算这篇文档与另一文档的相似度时可以简单使用矩阵点乘的方式。
但仍存在一个问题:即便某个单词比如The在句子中出现了2次,我们能认为它比football对这篇文章的分类更具决定性作用吗?显然不可能,那么怎么减少类似the 这种单词
对句子分类起的作用呢?我们可以根据文档中的每个单词在语料库中出现的文档数决定其权重,比如,the这个单词在我们的语料库中所有文档中都出现了,那么我们就给它一个
非常低的权重,而football这个单词出现的文档很少,我们就给它一大较大的权重,认为它是这篇文章的一个Important word。
3.TF-IDF算法:
终于引出了这个著名的算法:词频-逆向文档频率法(Term frequency-inverse document frequency), 顾名思义,该算法权衡了两个变量,即词频和逆向文档频率 ,
词频的含义是一个单词在当前文档中出现的次数,比如上文中football出现了1次,而逆向文档频率有个公式:
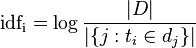
即用语料库中总文档数量除以包含该单词的文档数量,这里之所以取对数可以这样考虑:语料库中的总文档数显然会非常大,当某个词在大多数文档都出现时,该值近似为总文档数量,因此分子分母比值近似为1,再取对数,该值无限接近0。反之,如果某个词只在其他文档中从未出现,那么显然该值会非常大。
最后我们可以将词频和逆向文档频率相乘,这就得到了一个词的权重,对每个词都这样计算,我们就得到了一个权重向量(如下图)
4.聚类算法:
Nearest neight search(最近邻搜索)
输入:查询文档
输出:最相似文档
for 库中每篇文档 :预料库中所有文档 s = similarity(查询文档,库中每篇文档) if(s>best) best = s return best
这里的similarity相似度计算我们可以使用刚才介绍的TF-IDF算法将文档转化为向量,再通过余弦相似度等计算文档相似性。
变体:著名的K近邻算法,仅仅在上述算法中加一个优先队列即可。
K-means:
刚才讨论的算法大多都需要训练集,属于有监督算法(Supervised learning),无监督学习中没有提供训练集。输入一些文档,算法自动打标签
此文持续更新。。。。