大家好,今天分享的是HBase体系架构和HBase集群安装。承接上两篇文章《HBase简介》和《HBase数据模型》,点击回顾这2篇文章,有助于更好地理解本文。
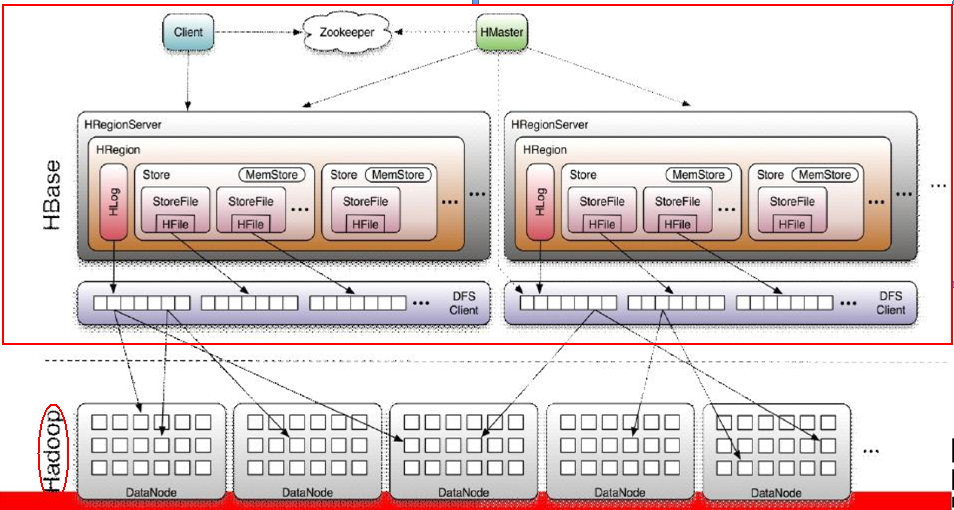
Hbase体系架构图
• 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
• 存贮所有Region的寻址入口;
• 实时监控Region server的上线和下线信息,并实时通知Master;
• 存储HBase的schema和table元数据;
• 负责Region server的负载均衡;
• 发现失效的Region server并重新分配其上的region;
• 管理用户对table的增删改操作;
• Region server负责切分在运行过程中变得过大的region
• store包括位于内存中的memstore和位于磁盘的storefile,写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile;当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
• 当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
• 客户端检索数据,先在memstore找,找不到再找storefile
• HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
• HRegion由一个或者多个Store组成,每个store保存一个columns family。
• 每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
https://hbase.apache.org 这是hbase官网。
2、修改hbase-env.sh中配置JAVA_HOME:

不使用HBase的默认zookeeper配置:

3、修改配置hbase-site.xml

4、配置regionservers 添加你配置的regionservers 的主机名,如hadoop1,hadoop2,hadoop3 ...
5、vi并配置backup-masters 添加你配置的master备份的主机名

6、拷贝Hadoop的conf下配置文件hdfs-site.xml到当前conf下
7、启动:Zookeeper集群主机
8、启动hbase :因为HBase依赖于Hadoop和zookeeper之上的所以要Hadoop集群启动正常和Zookeeper集群启动正常之后,再启动hbase。

9、启动后

10、启动浏览器访问
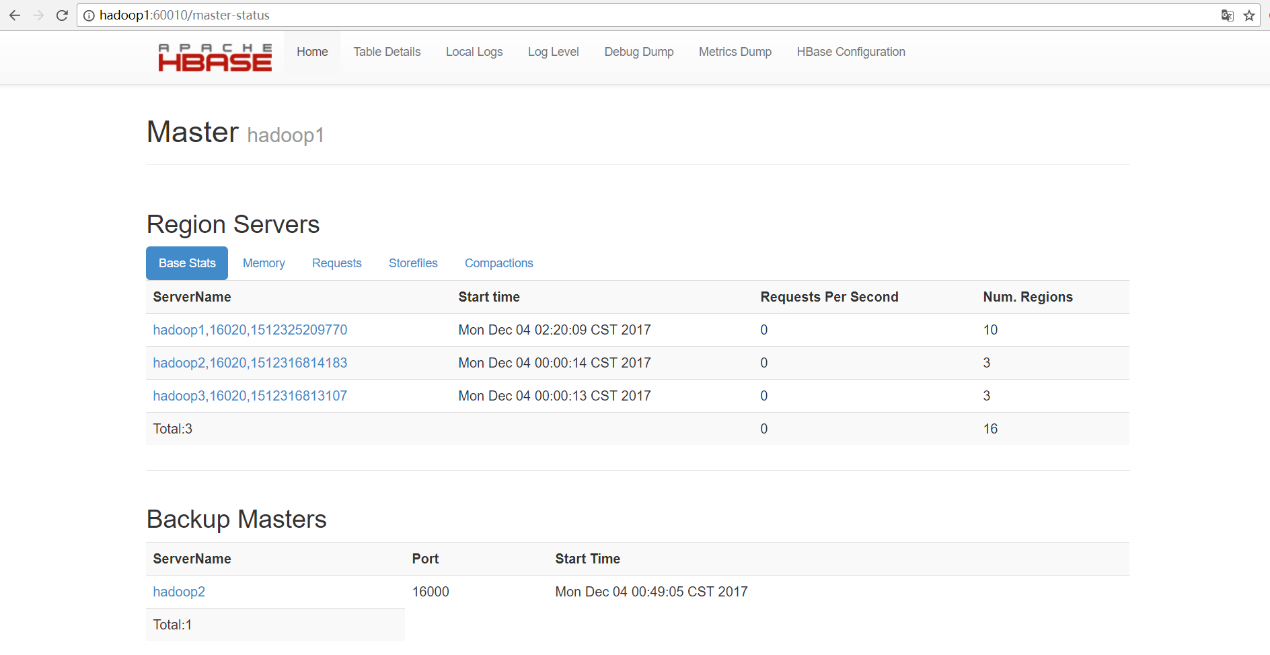
如果能成功显示出此页面,那么我们的hbase集群安装就算大功告成啦~。
好了,本次分享先告一段落,下次我们将继续为大家介绍hbase,下次见~~~
一、HBase体系架构
Hbase体系架构图
1.1、 Client
• 包含访问HBase的接口并维护cache来加快对HBase的访问1.2、Region
• HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变);• 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
1.3、Zookeeper
• 保证任何时候,集群中只有一个master;• 存贮所有Region的寻址入口;
• 实时监控Region server的上线和下线信息,并实时通知Master;
• 存储HBase的schema和table元数据;
1.4、Master
• 为Region server分配region;• 负责Region server的负载均衡;
• 发现失效的Region server并重新分配其上的region;
• 管理用户对table的增删改操作;
1.5、RegionServer
• Region server维护region,处理对这些region的IO请求• Region server负责切分在运行过程中变得过大的region
1.6、Memstore与storefile
• 一个region由多个store组成,一个store对应一个CF(列族)• store包括位于内存中的memstore和位于磁盘的storefile,写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile;当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
• 当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
• 客户端检索数据,先在memstore找,找不到再找storefile
• HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
• HRegion由一个或者多个Store组成,每个store保存一个columns family。
• 每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
二、Hbase集群安装
1、上传tar包到集群里,这里我选择的是hbase-1.1.2-bin.tar包。https://hbase.apache.org 这是hbase官网。
2、修改hbase-env.sh中配置JAVA_HOME:
不使用HBase的默认zookeeper配置:
3、修改配置hbase-site.xml
4、配置regionservers 添加你配置的regionservers 的主机名,如hadoop1,hadoop2,hadoop3 ...
5、vi并配置backup-masters 添加你配置的master备份的主机名
6、拷贝Hadoop的conf下配置文件hdfs-site.xml到当前conf下
7、启动:Zookeeper集群主机
8、启动hbase :因为HBase依赖于Hadoop和zookeeper之上的所以要Hadoop集群启动正常和Zookeeper集群启动正常之后,再启动hbase。
9、启动后
10、启动浏览器访问
如果能成功显示出此页面,那么我们的hbase集群安装就算大功告成啦~。
好了,本次分享先告一段落,下次我们将继续为大家介绍hbase,下次见~~~
有问题的或者想获取更多资料的请茄薇 java8733