精准率和召回率是两个不同的评价指标,很多时候它们之间存在着差异,具体在使用的时候如何解读精准率和召回率,应该视具体使用场景而定
有些场景,人们可能更注重精准率,如股票预测系统,我们定义股票升为1,股票降为0,我们更关心的是未来升的股票的比例,而在另外一些场景中,人们更加注重召回率,如癌症预测系统,定义健康为1,患病为0,我们更关心癌症患者检查的遗漏情况。
F1 Score
F1 Score 兼顾精准率和召回率,它是两者的调和平均值
[frac{1}{F1} = frac{1}{2}(frac{1}{Precision} + frac{1}{recall})
]
[F1 = frac{2cdot precisioncdot recall}{precision+recall}
]
定义F1 Score
def f1_score(precision,recall):
try:
return 2*precision*recall/(precision+recall)
except:
return 0

由上看出,F1 Score更偏向于分数小的那个指标
Precision-Pecall的平衡
精准率和召回率是两个互相矛盾的目标,提高一个指标,另一个指标就会不可避免的下降。如何达到两者之间的一个平衡呢?
回忆逻辑回归算法的原理:将一个结果发生的概率大于0.5,就把它分类为1,发生的概率小于0.5,就把它分类为0,决策边界为:( heta ^T cdot X_b = 0)
这条直线或曲线决定了分类的结果,平移决策边界,使( heta ^T cdot X_b)不等于0而是一个阈值:( heta ^T cdot X_b = threshold)

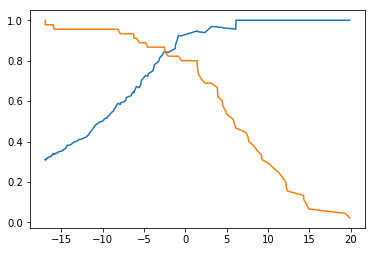
圆形代表分类结果为0,五角星代表分类结果为1,由上图可以看出,精准率和召回率是两个互相矛盾的指标,随着阈值的逐渐增大,召回率逐渐降低,精准率逐渐增大。
编程实现不同阀值下的预测结果及混淆矩阵
from sklearn.linear_model import LogisticRegression
# 数据使用前一节处理后的手写识别数据集
log_reg = LogisticRegression()
log_reg.fit(x_train,y_train)
求每个测试数据在逻辑回归算法中的score值:
decision_score = log_reg.decision_function(x_test)

不同阀值下预测的结果
y_predict_1 = numpy.array(decision_score>=-5,dtype='int')
y_predict_2 = numpy.array(decision_score>=0,dtype='int')
y_predict_3 = numpy.array(decision_score>=5,dtype='int')
查看不同阈值下的混淆矩阵:

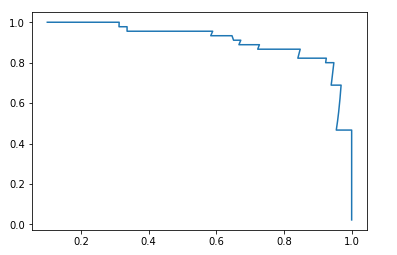
精准率-召回率曲线
求出0.1步长下,阈值在[min,max]区间下的精准率和召回率,查看其曲线特征:
threshold_scores = numpy.arange(numpy.min(decision_score),numpy.max(decision_score),0.1)
precision_scores = []
recall_scores = []
# 求出每个分类阈值下的预测值、精准率和召回率
for score in threshold_scores:
y_predict = numpy.array(decision_score>=score,dtype='int')
precision_scores.append(precision_score(y_test,y_predict))
recall_scores.append(recall_score(y_test,y_predict))
画出精准率和召回率随阈值变化的曲线
plt.plot(threshold_scores,precision_scores)
plt.plot(threshold_scores,recall_scores)
plt.show()

画出精准率-召回率曲线
plt.plot(precision_scores,recall_scores)
plt.show()
sklearn中的精准率-召回率曲线
from sklearn.metrics import precision_recall_curve
precisions,recalls,thresholds = precision_recall_curve(y_test,decision_score)
# sklearn中最后一个精准率为1,召回率为0,没有对应的threshold
plt.plot(thresholds,precisions[:-1])
plt.plot(thresholds,recalls[:-1])
plt.show()